Text Capture
The Text Capture object enables you to extract some text from a page of a PDF document. When you create a text capture, it appears in the model tree in the Schema pane and in the Output pane. You can optionally wrap a text capture inside an XML tag, by giving the capture a name, which will help you organize the tree in the Output pane into a meaningful structure (see code listing below). The default name of a text capture is Capture. For information about how to add objects to the model tree, see Insert an Object.
<Invoice>
<Header>GARDENING SERVICES INVOICE</Header>
<BillTo>Oswald Grim
Darkwood St. 17
Boston, MA 02128
+1-617-8767675</BillTo>
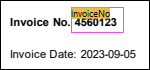
<InvoiceNo>4560123</InvoiceNo>
<Date>2023-09-05</Date>
<...>
</Invoice>
When you click a text capture in the model tree of the Schema pane, the capture becomes immediately highlighted in the PDF View pane (screenshot below), which helps to easily locate the capture on the page. The highlighted area has a text label that corresponds to the capture's name visible in the model tree and in the Output pane. You can also click elements or their values in the Output pane to see what objects they refer to on the page of your PDF document. For details, see Step 2 of the tutorial.
Properties in the Properties pane
You can configure the following properties of the Text Capture object:

The Output XML name property represents the name of the Text Capture object. If this property contains a value, this value will appear as an element in the XML tree in the Output pane. If the object has no name, no additional element will appear in the Output pane.
|
The Region property refers to the area of the page that a text capture occupies. If no value is specified, the Region property refers to the whole page. The screenshot below shows the definition of a region as well as the locations of the left, right, top, and bottom parts of a text capture called Col1. 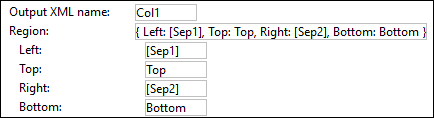 |
The Algorithm section contains various properties that enable you to handle basic PDF-processing procedures. The algorithm is visual in that it does not depend on the internal structure of a PDF document but rather on the order of visual elements of the document. The following properties are available:
•The Baseline Tolerance property specifies a distance for text baselines, which allows dealing with cases of minor text misalignment. •The Paragraph Spacing property specifies which baseline-to-baseline distance is considered a paragraph. This property enables you to configure whether two consecutive lines are treated as parts of the same paragraph or not. If the two consecutive lines belong to the same paragraph, no line break is inserted, and a space is inserted to join the lines, unless the Insert Space option is disabled (see Separate Words below). Setting this property to a high number enables you to treat the entire text as a single paragraph. The result will contain a line break for every paragraph, while non-paragraph line breaks in the PDF file will be converted to a single space by default. •The Baseline Angle property gives a reference angle (in degrees) for the baselines to use and can be used to extract vertical or angled text. The default option is set to 0°. •The Angle Deviation property specifies the extent to which the baseline of characters on the page can deviate from the Baseline Angle. The default is set to 180°, which means that every character will be taken into consideration. If you want to extract angled text, you can use this property to discard any non-angled text in the vicinity. •The Separate Words property specifies whether spaces are preserved or removed. If you select the Insert Space option, all the existing spaces will be preserved. If you select Glue Together, all the spaces will be removed. The Glue Together option is particularly useful for URLs that have line breaks.
|