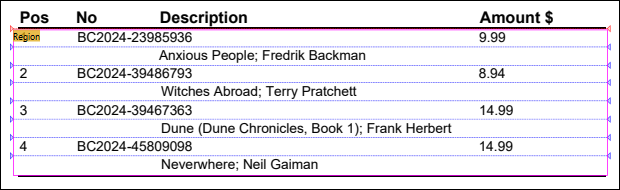
Split
The Split object (illustrated below) cuts a particular part of a page into pieces. The Split object can discard a fixed number of initial and/or final snippets of a region and supports different means of locating split positions. For details, see the Properties subsection below.
For information about how to add objects to the model tree, see Insert an Object.
Properties in the Properties pane
You can configure the following properties of the Split object:

The Region property describes the part of the page that is to be cut into pieces. If no value is specified, the Region property refers to the whole page. The screenshot below shows the definition of a region as well as the locations of the left, right, top, and bottom parts of the region. 
|
The Search property describes the part of the page where the PDF Extractor searches for particular split positions (see Method below). If no value is specified, the default option is equal to the value of the Region property.
The search region is usually used in combination with the region. The region specifies the part of a page that is to be split (e.g., the whole table), whereas the search region helps find lines or objects only in a particular area (e.g., along the left edge). For example, if there is a column where edges are reliable and consistent, you can restrict the search region only to that particular column. For an example in which the search region is used, see the Example 2 below.
|
The Skip Initial and Skip Final properties describe how many snippets from the start and end of the region, respectively, will be excluded from processing.
|
The Method property refers to the mechanism for locating split positions, based on which a specific region will be split into parts. The following methods are available:
•Find lines or edges •Find objects •Fixed distance
All the methods have two directions: (i) the search direction, which is vertical for the splitter and vertical location and boundary finders and horizontal for horizontal location and boundary finders, and (ii) the secondary direction, which is perpendicular to the search direction.
Find lines or edgesThe Find lines or edges method searches for lines or edges, along which the region will be split into snippets. The edge-finding method has the following properties:
•The Fill Gaps property enables you to specify the distance between adjacent high-contrast pixels, which causes them to merge. The Fill Gaps property can be particularly useful when, for example, a table row has dotted lines. Merging the dotted lines into one line will enable the PDF Extractor to identify this line as an edge. •The Minimum Edge Length property is an advanced setting that specifies the percentage of the search-region width an object has to cover in order to be counted. This property can be useful in situations when grid lines are inconsistent (e.g., when a grid line is shorter than the row). The default value is 60%. With enough space and consistent grid lines, the Minimum Edge Length property may not have a significant influence on the detection of split positions. However, you may want to tweak this parameter if there are missing grid lines. In this case, setting a lower percentage may help the splitter find the edge. •The Resolution property allows scanning a document at a higher resolution in case the document contains very fine lines. You can choose between Standard, Fine (144 ppi), and Extra Fine (288 ppi) resolution.
For an example that uses the Find lines or edges method, see Example 1 below.
Find objectsThe Find objects method can be particularly useful when there is a lack of edges. The object-finding method will scan the search region, and whenever a search direction coordinate has at least one pixel in the secondary direction which is different enough from the background color, this pixel is counted as being part of an object. Depending on the object's edge or edges you have selected, the splitter will cut the region into snippets, based on these lines. These lines can also be adjusted if necessary. With appropriate setup, the Find objects method can also be used to detect large gaps between lines of text.
The object-finding method has the following properties:
•The Background Color property is the background color of a PDF document and accepts hexadecimal color codes. The default option is #FFF, which stands for white. •The Tolerance property is the percentage of color deviation specified in the Background parameter. This is the range within which the background color is still considered a background. Anything above the percentage of color deviation is no longer considered a background. For example, the value 100 means that everything is treated as a background. •The Minimum Extent property specifies the minimum size of an object; any objects smaller than the value specified will be ignored. •The Fill Gaps property determines the size of a gap that is covered along the search direction; if two non-background rows are not farther apart than this distance, these rows are considered to be a single object. •The Edge to Find property determines on which edge an object will be split, which can be the beginning (Start), the end (End), or the beginning and end (Start and End) of the object. •The Displace property specifies an offset that will be added to the detected position of an object. The offset is usually negative when the Edge to Find property is set to Start and positive otherwise.
For an example that uses the Find objects method, see Example 2 below.
Fixed distanceThe fixed-distance method starts at the top of the search region (or whatever the controlling edge is) and moves ahead by a distance specified in the Distance field. This method may be particularly useful for certain documents that use fixed lines or cell heights.
The screenshot below illustrates an extract of a table that will be split into rows based on the parameters configured in the Method section in the Properties pane: The method has been set to Fixed Distance, and, using the measurements in the status bar, we have identified the distance between the start and end of each row, which is 24pt (set in the Distance field). For details about how to measure distances, see Example in the Post Process subsection below.  |
The Post Process section contains additional post-processing options for the result of the selected method:
•The Minimum Extent option specifies a threshold distance below which the split results are considered small fragments. •The Small Fragments parameter specifies how to proceed with small fragments. The following values are available:
oDiscard: Small fragments will not be included in the sequence of the splitter (default option). oMerge with previous: A small fragment will be merged with the first preceding non-small fragment. oMerge with following: A small fragment will be merged with the first succeeding non-small fragment. oSplit at center: The region between two non-small fragments will be split evenly; the initial and final small fragments will be merged with the first and last non-small fragments, respectively.
ExampleYou can use various ways of excluding unwanted fragments from processing. For example, if each page of your PDF document has the same number of snippets you want to eliminate, you can use the Skip Initial and Skip Final properties (see Example 1 below). However, if the number of unwanted snippets varies from page to page, you can use the Minimum Extent property.
To understand what value to supply for the Minimum Extent property, you need to measure the height of the fragment that you want to exclude from processing. Follow the steps below:
1.Select a rectangle that covers the height of the unwanted fragment (screenshot below). 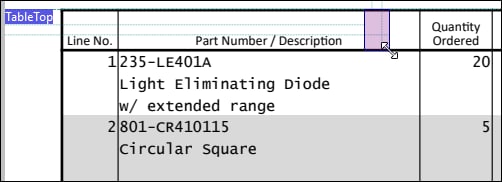 2.Check the measurements in the status bar (screenshot below). The value 26.84pt represents the height of the fragment.  3.Based on the measurements shown in the status bar, we can safely set the Minimum Extent property to 30pt. We have set the Small Fragments property to Discard. All the fragments smaller than 30pt will be excluded from processing. To avoid unpredictable results, you need to make sure that the height of the fragments you plan to include in the split results is greater than the value of the Minimum Extent property. In our example, the height of the rows we want to split is greater than the height of the header row. Therefore, the value we have set in the Minimum Extent property will affect only the snippets we want to discard.
|
Example 1: Find lines or edges
This example shows how to configure the Find lines or edges method. The goals of this example are as follows:
•To extract data from the table
•To exclude the top part of the page (which contains the header, company, client, and invoice details), the header row of the table, and the bottom part of the page from processing
To achieve the goals, we have configured the Split object in the following way:
•The Skip Initial property has been set to 2.
•The Skip Finial property has been set to 1.
•The Method has been set to Find lines or edges.
•No value has been set for the Region, therefore, the whole page is treated as a region.
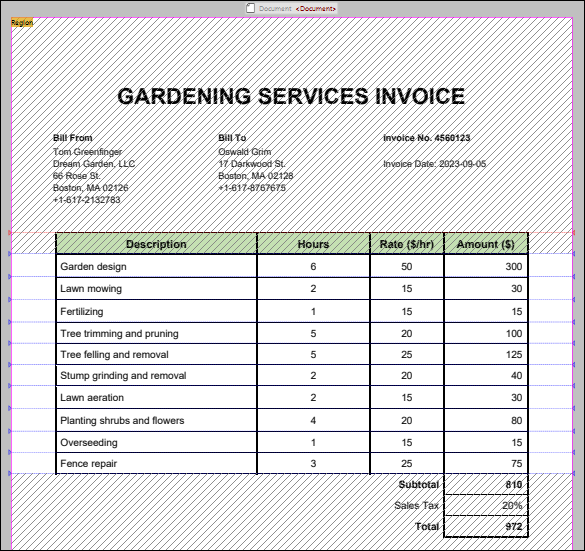
The algorithm has identified the first edge in the location where the header row starts and the second edge in the location where the header row ends. Therefore, the upper part of the document together with the header row of the table have been excluded from processing (grayed-out top part in screenshot below).
The Skip Initial value (1) has caused the algorithm to exclude the Subtotal, Sales Tax, and Total cells, because the first edge from the bottom of the region has been identified on the line where the Fence repair row ends. The rest of the table will be split into rows (grayed-out bottom part in screenshot below).
Example 2: Find objects
This example shows how to configure the Find objects method. The goal of this example is to extract table data from the sample invoice illustrated below.

The table shown in the screenshot above does not contain regular grid lines, which makes it difficult to identify correct split positions. Besides, the cells in the second column (No) and the cells in the third column (Description) overlap. In order to correctly split the table into rows, we have selected the Find objects method and configured it as follows:
•The Background Color and Tolerance properties have default values (#FFF and 10%, respectively).
•The Minimum Extent property has been set to 4pt, which helps eliminate objects smaller that this value.
•Since there are no gaps that can be filled in, the Fill Gaps property has its default value (0pt).
•The Edge to Find property has been set to Start, which means the objects will be split in locations where they start.
•By trial and error, we have identified the ideal value of the Displace property, which is -3pt. This value has caused the split positions to move slightly upwards, which will prevent the data from being truncated.
•No post-processing options have been defined.
Search region
Since there are no consistent lines along which the table could be split into rows, we use the Search region to identify reliable split positions, which will then be applied to the whole Region. The screenshot below shows that the Region contains all the rows of the table (light yellow area). The Region represents an area that we want to split. However, the Search region (bright yellow rectangle below) covers only the first column of the table, in which detecting objects works more reliably than in other parts of the table.
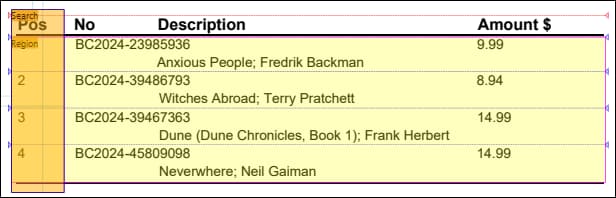
If no Search region is used, the splitter will identify the split positions shown below, which will lead to incorrect results in the output.