Database Relationships
When you add a database as a source component to your mapping, each table appears as the root table (screenshot below). When you click on the plus icon of a root table, you can see all related tables below the root table. The database component below displays two types of arrows that mean the following:
•The arrow pointing to the left ( ![]() ) indicates that the Books table is a child table of the Authors table.
) indicates that the Books table is a child table of the Authors table.
•The arrow pointing to the right ( ![]() ) shows that the Authors table is the parent of the Books table.
) shows that the Authors table is the parent of the Books table.
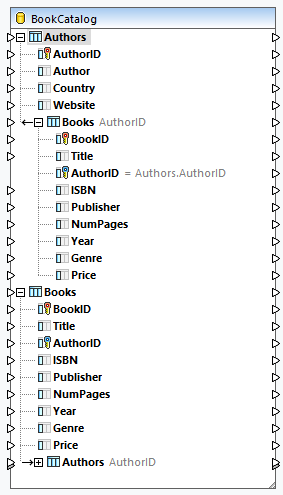
Structure of BookCatalog.sqlite
Depending on your business needs, you can use various mapping scenarios. The subsections below describe some of the possible scenarios. All the scenarios described below feature a hierarchical database called BookCatalog.sqlite. The database has two tables (Authors and Books) that have a foreign-key relationship. The screenshot below shows that the Books table has a foreign key called AuthorID that references the primary key in the Authors table.
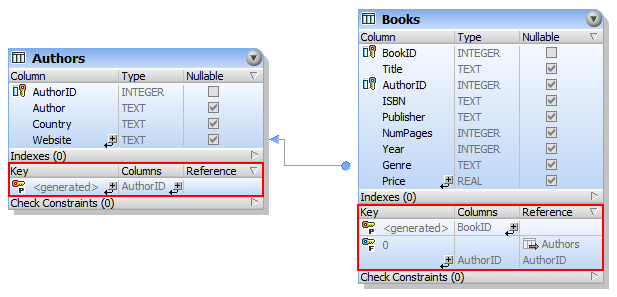
Sample data from BookCatalog.sqlite
The extracts from the Authors and Books tables are given below:
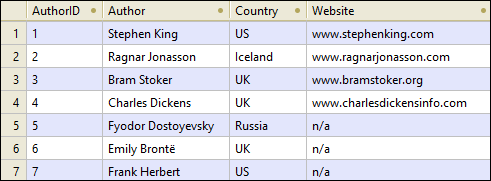
Authors table
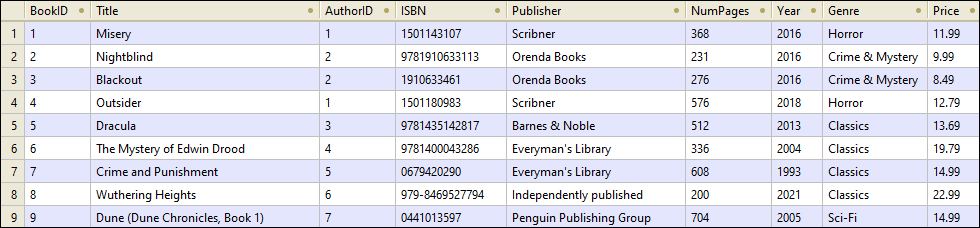
Books table
Scenario 1: Preserve the hierarchy
In our first scenario, we map data from BookCatalog.sqlite to Authors.xsd (see screenshot below). In this mapping, Authors is the root table. Our goal is to preserve the hierarchical relationship and get all the authors with their corresponding books in the output.
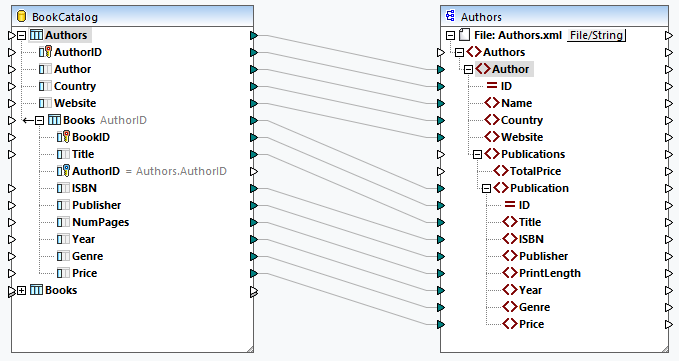
The code listing below shows an extract of the output:
<Authors>
<Author ID="23">
<Name>Fredrik Backman</Name>
<Country>Sweden</Country>
<Website>www.fredrikbackmanbooks.com</Website>
<Publications>
<Publication ID="26">
<Title>Anxious People</Title>
<ISBN>978-1-4059-3025-3</ISBN>
<Publisher>Penguin Books Ltd</Publisher>
<PrintLength>416</PrintLength>
<Year>2021</Year>
<Genre>Humor</Genre>
<Price>9.99</Price>
</Publication>
<Publication ID="27">
<Title>A Man Called Ove</Title>
<ISBN>9781444775815</ISBN>
<Publisher>Sceptre</Publisher>
<PrintLength>320</PrintLength>
<Year>2015</Year>
<Genre>Humor</Genre>
<Price>11.46</Price>
</Publication>
</Publications>
</Author>
</Authors>
Scenario 2: Swap the tables
In the second scenario, our goal is to get a list of books and their details in the output file. To achieve the goal, we will use Books as the root table. The table relationships will stay intact. The mapping design looks as follows:
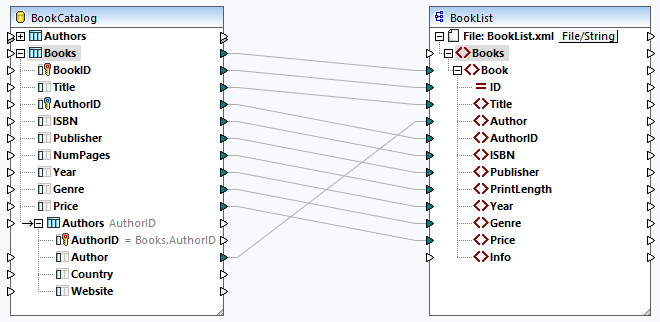
The code listing below shows an extract of the output:
<Books>
<Book ID="3">
<Title>Blackout</Title>
<Author>Ragnar Jonasson</Author>
<AuthorID>2</AuthorID>
<ISBN>1910633461</ISBN>
<Publisher>Orenda Books</Publisher>
<PrintLength>276</PrintLength>
<Year>2016</Year>
<Genre>Crime & Mystery</Genre>
<Price>8.49</Price>
</Book>
<Book ID="4">
<Title>Outsider</Title>
<Author>Stephen King</Author>
<AuthorID>1</AuthorID>
<ISBN>1501180983</ISBN>
<Publisher>Scribner</Publisher>
<PrintLength>576</PrintLength>
<Year>2018</Year>
<Genre>Horror</Genre>
<Price>12.79</Price>
</Book>
</Books>
Scenario 3: Map DB data from different root tables
In the third scenario, we will map data from each root table of the database component to Authors.xsd (see screenshot below). The related tables will be ignored.
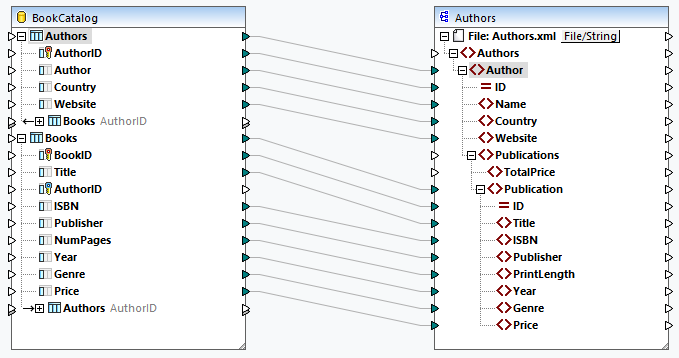
As a result, every single book, regardless of its author, will be listed under each author (code listing below).
<Author ID="19">
<Name>Sebastian Fitzek</Name>
<Country>Germany</Country>
<Website>www.sebastianfitzek.com</Website>
<Publications>
<Publication ID="1">
<Title>Misery</Title>
<ISBN>1501143107</ISBN>
<Publisher>Scribner</Publisher>
<PrintLength>368</PrintLength>
<Year>2016</Year>
<Genre>Horror</Genre>
<Price>11.99</Price>
</Publication>
<Publication ID="2">
<Title>Nightblind</Title>
<ISBN>9781910633113</ISBN>
<Publisher>Orenda Books</Publisher>
<PrintLength>231</PrintLength>
<Year>2016</Year>
<Genre>Crime & Mystery</Genre>
<Price>9.99</Price>
</Publication>
<Publication ID="3">...</Publication>
<Publication ID="4">...</Publication>
<Publication ID="5">...</Publication>
<Publication ID="6">...</Publication>
<Publication ID="7">...</Publication>
<Publication ID="8">...</Publication>
</Publications>
</Author>
Scenario 4: Map DB data to SQL/XML structure
In the fourth scenario, our goal is to map database data to a flat schema structure (SQL/XML Standard). The flat schema model is based on the ISO-ANSI SQL/XML specification INCITS/ISO/IEC 9075-14-2008. The SQL/XML specification defines how to map databases to XML. Relationships are defined in schemas using identity constraints; there are no references to elements. Therefore, the schema is a flat structure which resembles a tree-like view of the database. The specification can be purchased at the ANSI store. For more information, see www.iso.org.
The mapping below shows that database data is mapped from different root tables to a flat SQL/XML structure. The related tables are ignored. It is also possible to map database data from the related tables. However, if there are Book records that do not belong to an Author, these Book records will not be mapped to the target.
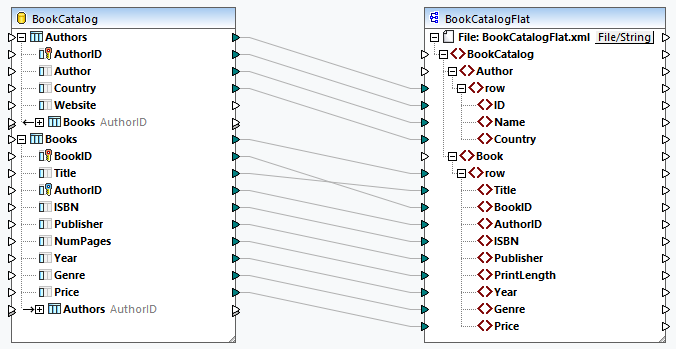
As a result, we will get a list of Author rows and a separate list of Book rows (screenshot below).
<Author>
<row>
<ID>1</ID>
<Name>Stephen King</Name>
<Country>US</Country>
</row>
<row>
<ID>2</ID>
<Name>Ragnar Jonasson</Name>
<Country>Iceland</Country>
</row>
<row>...</row>
<row>...</row>
</Author>
<Book>
<row>
<Title>Misery</Title>
<BookID>1</BookID>
<AuthorID>1</AuthorID>
<ISBN>1501143107</ISBN>
<Publisher>Scribner</Publisher>
<PrintLength>368</PrintLength>
<Year>2016</Year>
<Genre>Horror</Genre>
<Price>11.99</Price>
</row>
<row>
<Title>Nightblind</Title>
<BookID>2</BookID>
<AuthorID>2</AuthorID>
<ISBN>9781910633113</ISBN>
<Publisher>Orenda Books</Publisher>
<PrintLength>231</PrintLength>
<Year>2016</Year>
<Genre>Crime & Mystery</Genre>
<Price>9.99</Price>
</row>
<row>...</row>
<row>...</row>
</Book>
For more information about this scenario, see also the following mapping: MapForceExamples\DB_Altova_SQLXML.mfd.