Example: Group and Filter Nodes by Name
This example shows you how to design a mapping that reads key-value pairs from an XML property list (or XML plist) and writes them to a CSV file. (XML property lists represent a way of storing macOS and iOS object information in XML format, see https://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/PropertyLists/UnderstandXMLPlist/UnderstandXMLPlist.html.) The example is accompanied by a mapping sample which is available at the following path: <Documents>\Altova\MapForce2024\MapForceExamples\Tutorial\ReadPropertyList.mfd.
The code listing below represents the source XML file.
<?xml version="1.0" encoding="UTF-8"?> |
The goal of the mapping is to create a new line in the CSV file from certain key-value pairs found under <dict> node in the property list file. Specifically, the mapping must filter only <key> - <string> pairs. Other key-value pairs (for example, <key> - <integer>) must be ignored. In the CSV file, the line must store the name of the property, separated from the value of the property by a comma. In other words, the output must look as follows:
First Name,William Last Name,Shakespeare Profession,Playwright |
To achieve this goal, the mapping uses dynamic access to all children nodes of the dict node. Secondly, the mapping uses the group-starting-with function to group the key-value pairs retrieved from the XML file. Finally, the mapping uses a filter to filter only those nodes where the node name is "string".
The following steps show how the required mapping can be created.
Step 1: Add the source XML component to the mapping
1.Set the mapping transformation language to BUILT-IN.
2.On the Insert menu, click XML Schema/File, and browse for the following file: <Documents>\Altova\MapForce2024\MapForceExamples\Tutorial\plist.xml. This XML file points to the plist.dtd schema located in the same folder.
Step 2: Add the target CSV component to the mapping
1.On the Insert menu, click Text File. When prompted, select the Use simple processing for standard CSV... option.
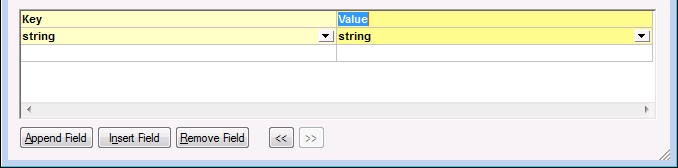
2.Add a CSV field to the component, by clicking Append field.
3.Double-click the name of each field, and enter "Key" as name of the first field, and "Value" as name of the second field. The "Key" field will store the name of the property, while the "Value" field will store the property value. For more information about CSV components, see CSV and Text Files.
Step 3: Add the filter and functions
1.Drag the equal, exists and group-starting-with functions from the Libraries window into the mapping. For general information about functions, see Functions.
2.To add the filter, click the Insert menu, and then click Filter: Nodes/Rows. For general information about filters, see Filters and Conditions.
3.On the Insert menu, click Constant, and then enter the text "string".
4.In the source component, right-click the dict node and select Show Child Elements with Dynamic Name from the context menu. On the "Dynamically Named Children Settings" dialog box, make sure that the check box Show name test nodes to filter or create elements by fixed node name is selected.
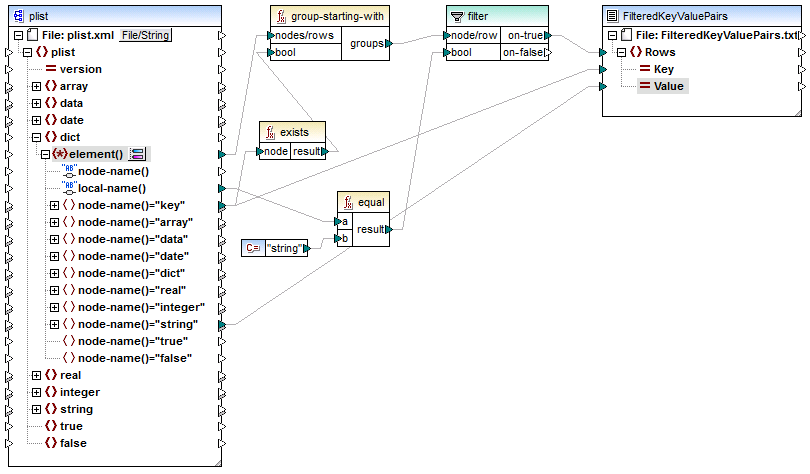
5.Draw the connections as shown below.
ReadPropertyList.mfd
The mapping explained
The element() item on the source component provides all children of the dict node, as a sequence, to the group-starting-with function. The group-starting-with function creates a new group whenever a node with the name key is encountered. The exists function checks for this condition and returns the result as Boolean true/false to the grouping function.
For each group, the filter checks if the name of the current node is equal to "string", with the help of the equal function. The name itself is read from the local-name(), which supplies the node's name as a string.
The connections to the target component have the following role:
•Only when the filter condition is true, a new row is created in the target CSV.
•Key (property name) is taken from the value of the key element in the source.
•Value (property value) is taken from the string name test node.