Capture de texte
L’objet de Capture de texte vous permet d’extraire du texte de la page d’un document PDF. Quand vous créez une capture de texte, elle apparaît dans l’arborescence de modèle dans le volet de schéma et dans le volet Sortie. Vous pouvez envelopper une capture de texte en option à l’intérieur d’une balise XML, en donnant un nom à une capture, qui vous aidera à organiser l’arborescence dans le volet Sortie en une structure utile (voir la liste de code ci-dessous). Le nom par défaut d’une capture de texte est Capture. Pour savoir comment ajouter les objets à l’arborescence modèle, voir Insérer un objet.
<Invoice>
<Header>GARDENING SERVICES INVOICE</Header>
<BillTo>Oswald Grim
Darkwood St. 17
Boston, MA 02128
+1-617-8767675</BillTo>
<InvoiceNo>4560123</InvoiceNo>
<Date>2023-09-05</Date>
<...>
</ Invoice>
Lorsque vous cliquez sur une capture de texte dans l’arborescence de modèle du volet de schéma, la capture se met immédiatement en surbrillance dans le volet de l’Affichage PDF (capture d’écran ci-dessous), qui aide à localiser la capture sur la page. La zone en surbrillance a un libellé de texte qui correspond au nom de la capture visible dans l’arborescence de modèle et dans le volet Sortie. Vous pouvez aussi cliquer sur des éléments ou leurs valeurs dans le volet Sortie pour voir quels objets ils référencent dans une page de votre document PDF. Pour les détails, voir Étape 2 du tutoriel.

Propriétés
Vous pouvez configurer les propriétés suivantes de l'objet Capture de texte dans le volet Propriétés : Output XML Name, Region et Algorithm (voir ci-dessous).
Sortie nom XML
La propriété Sortie nom XML représente le nom de l’objet Capture de texte. Si cette propriété contient une valeur, cette valeur apparaîtra comme élément dans l’arborescence XML dans le volet Sortie. Si l’objet n’a pas de nom, aucun élément supplémentaire n’apparaîtra dans le volet Sortie.
Région
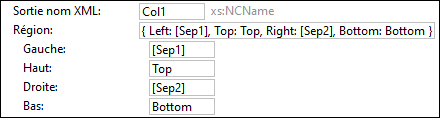
La propriété Région fait référence à la zone de la page qu’une capture de texte occupe. Si aucune valeur n’a été spécifiée, la propriété Région fait référence à toute la page. La capture d’écran ci-dessous affiche la définition d’une région ainsi que les emplacements dans les parties gauche, droite, du haut et du bas d’une capture de texte appelée Col1.
Algorithme
La section Algorithme contient différentes propriétés qui vous permettent de gérer des procédures de traitement PDF de base. L’algorithme est visuel dans le sens qu’il ne dépend pas de la structure interne d’un document PDF, mais plutôt de l’ordre d’éléments visuels du document. Les propriétés disponibles sont décrites dans la table ci-dessous.
Baseline Tolerance | La propriété Tolérance baseline spécifie une distance pour des baselines de texte, qui permettent de gérer des cas mineurs de mauvais alignements de texte.
|
Paragraph Spacing | La propriété Espacement de paragraphe spécifie quelle distance baseline-à-baseline est considérée comme paragraphe. Cette propriété vous permet de configurer si deux lignes consécutives sont traitées comme faisant partie du même paragraphe ou non.
Si les deux lignes consécutives font partie du même paragraphe, aucun saut de ligne n’est inséré, et un espace est inséré pour joindre les lignes sauf si l’option Insérer espace est désactivée (voir Mots séparés ci-dessous). Configurer cette propriété à un numéro élevé vous permet de traiter tout le texte comme paragraphe unique. Le résultat contiendra un saut de ligne pour chaque paragraphe, tandis que des sauts de ligne non-paragraphes dans le fichier PDF convertira en un espace unique par défaut.
|
Baseline Angle | La propriété Baseline Angle est utilisée pour extraire du texte vertical ou angulaire. L’option par défaut est définie à 0°.
|
Angle Deviation | La propriété Déviation d’angle spécifie l’étendue à laquelle la baseline des glyphes de caractère sur la page peuvent dévier de l’Angle baseline. Le défaut est défini à 180°, ce qui signifie que chaque caractère sera pris en considération. Si vous souhaitez extraire du texte à angle, vous pouvez utiliser cette propriété pour ignorer tout texte qui n’est pas à angle à proximité.
|
Separate Words | La propriété Mots séparés spécifie si des espaces sont préservés ou supprimés. Si vous sélectionnez l’option Insérer espace, tous les espaces existants seront préservés. Si vous sélectionnez Coller ensemble, tous les espaces seront supprimés. L’option Coller ensemble est particulièrement utile pour les URL qui ont des sauts de ligne.
|
Whitespace Mode | Le Mode Espace blanc aide à aborder des cas dans lesquels les polices intégrées ne contiennent pas de valeur de la largeur du caractère d’espace. Le mode de l’espace blanc peut également gérer des cas où l’espacement entre les caractères est écrasé par la composition. Le mode d’espace blanc a les valeurs suivantes : Default, Relative Value et Absolute Value (détails ci-dessous).
Défaut L’option par défaut assume que la largeur d’un espace horizontal est la largeur détectée pour la police.
Relative Value La moyen le plus commun d’utiliser l’option de la Relative Value serait de définir une valeur entre 0.2 et 0.5, ce qui est utilisé par les polices les plus proportionnelles, ou 1.0 pour la police mono-espacée (dans le cas où l’ExtracteurPDF n’extrait pas d’espace blanc correctement par lui-même). La largeur est relative à la largeur de la cellule du caractère de la police.
Absolute Value Le mode absolu aide à résoudre les problèmes avec les différentes tailles utilisées côte-à-côte. Le mode absolu prend la largeur en unités absolues (par ex., les points, millimètres). La valeur recommandée dans ce mode serait d’environ 20 % à 50 % de la taille de la police utilisée. Par exemple, pour une taille de police de 10pt, la valeur recommandée serait entre 2pt et 5pt.
|