Texterfassung
Mit Hilfe von Texterfassungsobjekten können Sie Text aus einer Seite eines PDF-Dokuments extrahieren. Wenn Sie ein Texterfassungsobjekt erstellen, wird es in der Modellstruktur des Schema-Fensters und im Ausgabefenster angezeigt. Sie können ein solches Objekt optional in einen XML-Tag verpacken, indem Sie dem erfassten Text einen Namen geben, wodurch Sie die Elemente im Ausgabefenster in einer beschreibenden Struktur anordnen können (siehe Codefragement unten). Der Standardname eines Texterfassungselements ist Capture. Informationen dazu, wie Sie Objekte zur Modellstruktur hinzufügen, finden Sie unter Einfügen eines Objekts.
<Invoice>
<Header>GARDENING SERVICES INVOICE</Header>
<BillTo>Oswald Grim
Darkwood St. 17
Boston, MA 02128
+1-617-8767675</BillTo>
<InvoiceNo>4560123</InvoiceNo>
<Date>2023-09-05</Date>
<...>
</Invoice>
Wenn Sie in der Modellstruktur des Schema-Fensters auf eine Texterfassung klicken, wird der erfasste Text im PDF-Ansichtsfenster sofort hervorgehoben (Abbildung unten), sodass Sie den Text auf der Seite leichter finden. Der markierte Bereich hat eine Textbeschriftung, die dem Namen des in der Modellstruktur und im Ausgabefenster angezeigten Texterfassungselements entspricht. Sie können auch auf Elemente oder deren Werte im Ausgabefenster klicken, um zu sehen, auf welche Objekte auf der Seite Ihres PDF-Dokuments sie sich beziehen. Nähere Informationen dazu finden Sie in Schritt 2 des Tutorials.
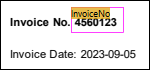
Eigenschaften
Für das Objekt "Texterfassung" können die folgenden Eigenschaften konfiguriert werden: XML-Ausgabename, Region und Algorithmus (siehe unten).
XML-Ausgabename
Die Eigenschaft XML-Ausgabename stellt den Namen das Texterfassungsobjekts dar. Wenn diese Eigenschaft einen Wert enthält, wird er in der XML-Struktur im Ausgabefenster als Element angezeigt. Wenn das Objekt keinen Namen hat, erscheint im Ausgabefenster kein zusätzliches Element.
Region
Die Eigenschaft Region bezeichnet den Seitenbereich, in dem eine Texterfassung erfolgt. Wenn kein Wert definiert wird, bezieht sich die Eigenschaft Region auf die gesamte Seite. In der Abbildung unten sehen Sie die Definition einer Region sowie die Positionen des linken, rechten, oberen und unteren Rands eines Texterfassungsobjekts namens Col1.
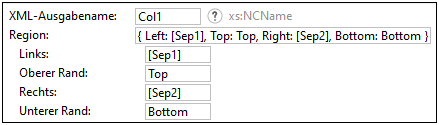
Algorithmus
Der Abschnitt Algorithmus enthält verschiedene Eigenschaften, mit Hilfe derer Sie grundlegende PDF-Verarbeitungsprozeduren behandeln können. Der Algorithmus ist insofern visuell, als er nicht von der internen Struktur eines PDF-Dokuments, sondern von der Reihenfolge von visuellen Elementen des Dokuments abhängt. Die verfügbaren Eigenschaften sind in der Tabelle unten beschrieben.
Grundlinientoleranz | Mit der Eigenschaft Grundlinientoleranz wird ein Abstand für Textgrundlinien definiert, wodurch kleinere Fehlausrichtungen des Texts korrigiert werden können.
|
Absatzabstand | Mit der Eigenschaft Absatzabstand wird definiert, welcher Abstand zwischen einer Grundlinie und der nächsten als Absatz betrachtet werden soll. Mit Hilfe dieser Eigenschaft können Sie einstellen, ob zwei aufeinander folgende Zeilen als Teil desselben Absatzes behandelt werden sollen oder nicht.
Wenn zwei aufeinander folgende Zeilen zum selben Absatz gehören, wird kein Zeilenumbruch eingefügt und es wird ein Leerzeichen eingefügt, um die Zeilen miteinander zu verbinden, es sei denn die Option Leerzeichen einfügen ist deaktiviert (siehe Separate Wörter unten). Wenn Sie für diese Eigenschaft eine höhere Zahl definieren, können Sie dadurch den gesamten Text als einen einzigen Absatz behandeln. Das Ergebnis enthält dann für jeden Absatz einen Zeilenumbruch, während Nicht-Absatz-Zeilenumbrüche in der PDF-Datei standardmäßig in ein einziges Leerzeichen konvertiert werden.
|
Grundlinienwinkel | Mit Hilfe der Eigenschaft Grundlinienwinkel können Sie vertikalen oder in einem Winkel geschriebenen Text extrahieren. Standardmäßig ist diese Option auf 0° gesetzt.
|
Winkelabweichung | Mit der Eigenschaft Winkelabweichung wird festgelegt, wie weit die Zeichengrundlinie auf der Seite vom Grundlinienwinkel abweichen kann. Der Standardwert ist 180°, d.h. es wird jedes Zeichen berücksichtigt. Wenn Sie schräg geneigten Text extrahieren möchten, können Sie nicht geneigten Text in der Nähe mit Hilfe dieser Eigenschaft verwerfen.
|
Separate Wörter | Mit der Eigenschaft Separate Wörter wird definiert, ob Leerzeichen beibehalten oder entfernt werden sollen. Bei Auswahl der Option Leerzeichen einfügen werden alle vorhandenen Leerzeichen beibehalten. Bei Auswahl von Zusammenkleben werden alle Leerzeichen entfernt. Die Option Zusammenkleben ist vor allem bei URLs mit Zeilenumbrüchen nützlich.
|
Whitespace-Modus | Der Whitespace-Modus hilft in Fällen, in denen die eingebetteten Schriftarten keinen Wert für die Breite eines Leerzeichens enthalten. Außerdem hilft der Whitespace-Modus in Fällen, in denen die Abstände zwischen Zeichen durch den Schriftsatz außer Kraft gesetzt werden. Im Whitespace-Modus stehen die folgenden Werte zur Verfügung: Standardwert, Relativer Wert und Absoluter Wert (nähere Informationen siehe unten).
Standardwert Bei der Standardoption wird angenommen, dass die Breite eines horizontalen Abstands der für die Schriftart ermittelten Breite entspricht.
Relativer Wert Am häufigsten wird die Option Relativer Wert verwendet, um einen Wert zwischen 0,2 und 0,5 zu definieren, wie er von den meisten Proportionalschriftarten verwendet wird, oder 1,0 für eine Mono-Spaced Schriftart (für den Fall, dass PDFExtractor Whitespace nicht selbst korrekt extrahiert). Die Breite ist relativ zur Zellenbreite der Schriftartzeichen.
Absoluter Wert Bei Verwendung des absoluten Modus können Sie Probleme mit nebeneinander verwendeten Schriftarten unterschiedlicher Größe lösen. Im absoluten Modus wird die Breite in absoluten Einheiten (z.B. Punkt, Millimeter) angegeben. Der empfohlene Wert in diesem Modus wäre ungefähr 20 % - 50 % der verwendeten Schriftgröße. So läge der empfohlene Wert bei einer Schriftgröße von 10 etwa zwischen 2 pt und 5 pt.
|