查找,查找下一个
图标和快捷方式
命令 | 图标 | 快捷方式 |
查找 | Ctrl+F | |
查找下一个 | F3 |
查找
使用查找命令会打开“查找/替换”对话框(参见下方截图),您可以在其中指定要查找的字符串和其他搜索选项。要查找文本,请在“查找”字段中输入文本,或使用组合框从最近10个搜索标准中选择一个,然后指定搜索的选项。
当在“项目”窗口中选择一个项目时,查找命令也可以用来查找文件和文件夹名称。
查找下一个
查找下一个命令重复上一个查找命令。它会搜索输入文本的下一个匹配项。
当在“项目”窗口中选择一个项目时,还可以使用查找下一个命令来查找文件和文件夹名称。
“查找/替换”对话框
下方描述的“查找/替换”对话框出现在文本视图和网格视图中。查找选项可通过位于搜索字段下方的按钮来指定(参见下方截图)。当一个选项被启用时,其按钮颜色会变为蓝色(参见下图中的第一个(大小写)选项)。

您可以在以下选项中进行选择:
•区分大小写:启用区分大小写的搜索(Address不同于address)。
•全字匹配:只有文本中的确切字词才会被匹配。例如,对于输入字符串fit, 当启用全字匹配时,仅单词fit才匹配该搜索字符串;而fitness中的fit将无法匹配。
•正则表达式:启用时,搜索词将被读取为正则表达式。有关如何使用正则表达式的说明,请参见下方的正则表达式。
•过滤结果:选择一个或多个文档组件进行搜索。
•查找定位点:当输入搜索词时,文档中的匹配项将突出显示,其中一个匹配项将被标记为当前选定的匹配项。查找定位点按钮确定当前第一个选择是否是相对于光标位置进行的。如果打开了查找定位点,则当前选择的第一个匹配项将是当前光标位置的下一个匹配项。如果关闭了查找定位点,则当前选择的第一个匹配项将是从文档顶部开始的第一个匹配项。
•在选定内容中查找:启用时将锁定当前选定文本并将搜索范围限制在该选定内容内。否则,将搜索整个文档。在选择新的文本范围之前,通过关闭在选定内容中查找选项可解锁当前选定内容。
使用正则表达式
您可以使用正则表达式(regex)来查找文本字符串。为此,请先启用正则表达式选项(请参见上方查找选项)。这表明搜索字段中的文本将作为正则表达式进行评估。然后,在搜索字段中输入正则表达式。如需构建正则表达式的帮助,单击位于搜索字段右侧的正则表达式生成器按钮(请参见下方截图)。单击生成器中的条目以在搜索字段中输入相应的正则表达式元字符。下方截图显示了一个用于查找电子邮件地址的简单正则表达式。有关元字符的简要说明,请参见下方正则表达式元字符部分。

正则表达式元字符
下方给出了正则表达式元字符的列表。
. | 匹配任何字符。这是单个字符的占位符。 |
( | 标记带标记的表达式的开始。 |
) | 标记带标记的表达式的结束。 |
(abc) | ( and )元字符标记带标记的表达式的开始和结束。带标记的表达式可用于标记搜索区域,以便以后能够引用它(反向引用)。您可以标记多达九个表达式(稍后在“查找”或“替换”字段中进行反向引用)。
例如,(the) \1匹配字符串the the。这个表达式解释如下:找到字符串“the”(并记住它是一个标记区域),后跟一个空格字符,然后是对之前匹配的标记区域的反向引用。 |
\ | n是一个变量,可以采用1到9之间的整数值。替换时,该表达式指的是第一至第九个标记区域。例如,如果查找字符串是Fred([1-9])XXX,替换字符串是Sam\1YYY,这意味着在查找字符串中,有一个带标记的表达式,(隐式地)用数字1来索引;在替换字符串中,带标记的表达式用\1来引用。如果将查找替换命令应用于Fred2XXX,它将生成Sam2YYY。 |
\< | 匹配词的开头。 |
\> | 匹配词的结尾。 |
\x | 允许您使用一个字符x,否则它会具有特殊含义。例如,\[可能会被解释为[,而不是字符集的开头。 |
[...] | 表示一组字符。例如,[abc]表示匹配a、b或c字符中的任何一个。您还可以指定范围,例如[a-z]用于任何小写字符。 |
[^...] | 集合中字符的补集。例如,[^A-Za-z]表示除字母字符之外的任何字符。 |
^ | 匹配行的开头(除非在集合内部使用,参见上文)。 |
\$ | 匹配行的结尾。例如,A+\$在行尾查找一个或多个A。 |
* | 匹配0次或多次。例如,Sa*m匹配Sm、Sam、Saam、Saaam 等。 |
+ | 匹配1次或多次。例如,Sa+m匹配Sam、Saam、Saaam等。 |
特殊字符的表示形式
请注意以下表达式。
\ | 回车键(CR)。您可以使用CR(\)或LF(\)来查找或创建新行。 |
\ | 换行(LF)。您可以使用CR(\)或LF(\)来查找或创建新行。 |
\t | 制表符 |
\\ | 使用该字符对出现在正则表达式中的字符进行转义,例如:\\\。 |
正则表达式示例
本示例展示了如何使用正则表达式查找和替换文本。在许多情况下,查找和替换文本是很简单直接的,根本不需要正则表达式。但是,在某些情况下,您想要对文本进行的操作是无法通过标准的查找和替换操作完成的。例如,假设您有一个包含数千行的XML文件,您需要通过一个操作来对某些元素进行重命名,而不会影响其中包含的内容。或者,您需要更改一个元素的多个特性的顺序。这就是正则表达式派上用场的地方,因为它们可以为您节省大量工作。
示例1:重命名元素
下方的XML示例代码片段包含一个书籍列表。假设您的目标是将每本书的<Category>元素替换为<Genre>。实现此目标的方法之一是使用正则表达式。
<?xml version="1.0" encoding="UTF-8"?> |
为此,请执行以下步骤:
1.按Ctrl+H以打开“查找”和“替换”对话框。
2.单击使用正则表达式 ![]() 。
。
3.在“查找”字段中,输入以下文本: <category>(.+)</category>。该正则表达式将找到所有category元素并突出显示它们。
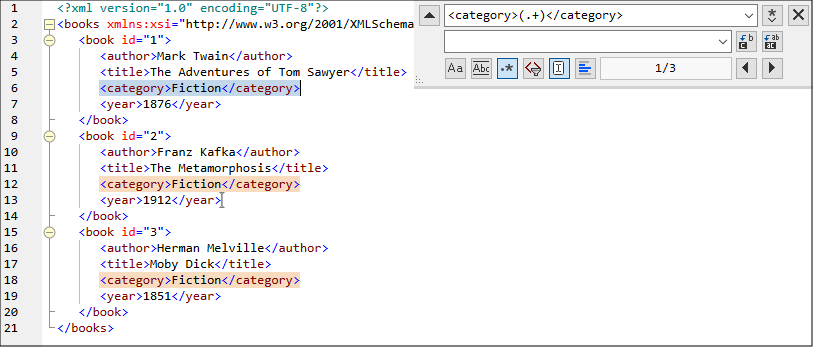
为了查找每个元素的内部文本(事先并不知晓),我们使用了带标记的表达式(.+)。带标记的表达式(.+) 表示“匹配一个或多个出现的任何字符,即.+,并记住这一匹配”。如下一步所示,我们稍后将需要引用带标记的表达式。
4.在“替换”字段中,请输入以下文本:<genre>\1</genre>。该正则表达式指定替换文本。请注意,它对“查找”字段中之前带标记的表达式使用了反向引用\1。换句话说,在这种情况下,\1表示“当前匹配的 <category>元素的内部文本”。
5.单击全部替换 ![]() 并观察结果。 现在所有category元素都已被重命名为genre。
并观察结果。 现在所有category元素都已被重命名为genre。
示例2:更改特性的顺序
下方的XML示例代码片段包含一个产品列表。每个product元素都有两个特性:id和size。假设我们的目标是更改每个product元素中id和size特性的顺序(也就是说,size应在id之前)。满足这一要求的方法之一是使用正则表达式。
<?xml version="1.0" encoding="UTF-8"?> |
为此,请执行以下步骤:
1.按Ctrl+H以打开“查找”和“替换”对话框。
2.单击使用正则表达式  。
。
3.在“查找”字段中,请输入以下文本:<product id="(.+)" size="(.+)"/> .该正则表达式会在XML文档中查找product元素。请注意,为了查找每个特性的值(事先并不知晓),我们使用了带标记的表达式(.+)两次。带标记的表达式(.+) 查找每个特性的值(假定该值是一次或多次出现的任何字符,即.+)。
4.在“替换”字段中,请输入以下文本:<product size="\2" id="\1"/>。该正则表达式包含找到的每个product元素的替换文本。请注意,它使用了两个引用\1和\2。它们对应于“查找”字段中的带标记的表达式。也就是说,\1表示“id特性的值”,\2表示“size特性的值”。
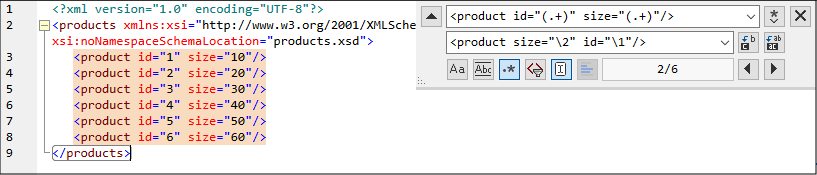
6.单击全部替换  并观察结果。 所有的product元素现在都已更新,size特性排在了id特性之前。
并观察结果。 所有的product元素现在都已更新,size特性排在了id特性之前。