从示例Schema生成代码后,将生成一个测试Java项目以及多个支持的Altova库。
关于生成的Java库
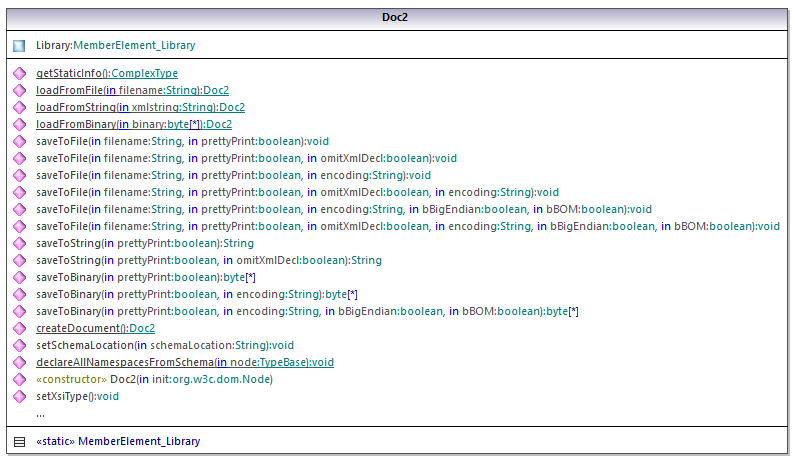
生成的代码的中心类是Doc2类,它表示XML文档。为每个Schema生成这样的类,其名称取决于Schema文件名。请注意,将此类命名为Doc2以避免可能与命名空间名称发生冲突。如图所示,此类提供了从文件、二进制流或字符串中加载文档(或将文档保存到文件、流和字符串)的方法。有关此类的描述,请参见com.[YourSchema].[Doc]类引用。
Doc2类的Library成员表示文档的实际根。
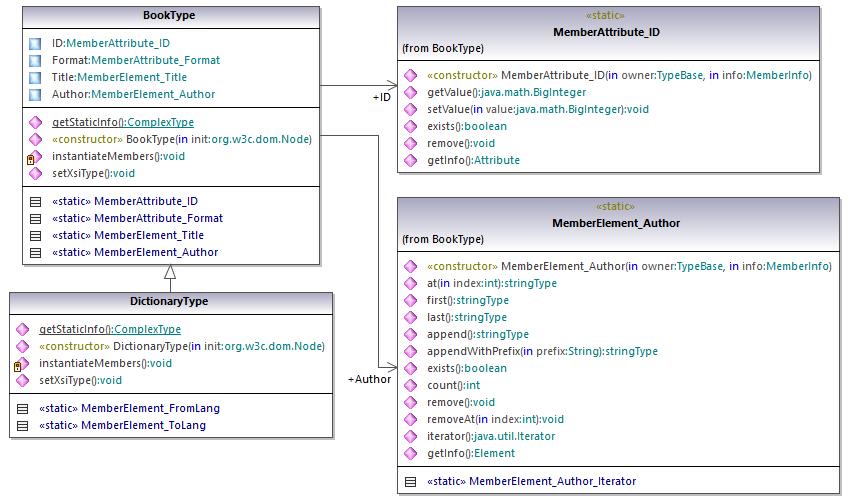
根据关于生成的Java代码中的代码生成规则,将为特定类型的每个特性和元素生成成员类。在生成的代码中,此类成员类的名称将分别以MemberAttribute_和MemberElement_为前缀。在下图中,此类的示例是MemberAttribute_ID and MemberElement_Author,它们分别从图书的Author元素和ID特性生成。它们允许您对XML实例文档中的相应元素和特性进行编程操作(例如追加、删除、设置值等)。有关更多信息,请参见com.[YourSchema].[YourSchemaType].MemberAttribute和com.[YourSchema].[YourSchemaType].MemberElement类引用。
由于DictionaryType是一个复杂类型,从Schema中的BookType派生,因此这一关系也反映在生成的类中。如下图所示,DictionaryType类继承了BookType类。
如果简单类型在您的XML Schema中定义为枚举,则枚举值将在生成的代码中作为Enum值可用。在本例使用的Schema中,有精装、平装、电子书等图书格式。因此,在生成的代码中,这些值以Enum的形式提供,即作为BookFormatType类的成员。
编写XML文档
1.在Eclipse文件菜单上,单击导入,选择现有项目到工作区,然后单击下一步。
2.在选择根目录旁边,单击浏览,,选择生成Java代码的目录并单击完成。
3.在Eclipse包资源管理器中,展开com.LibraryTest包并打开LibraryTest.java文件。
在根据频繁更改的XML Schema对应用程序进行原型设计时,您可能需要频繁地将代码生成到同一目录,从而将Schema更改及时反映在代码中。请注意,每次将代码生成到同一个目标目录中时,都会覆盖生成的测试应用程序和Altova库。因此,不能将代码添加到生成的测试应用程序中。取而代之的是,将Altova库集成到您的项目中(参见集成Schema包装库)。 |
4.编辑Example()方法,如下所示:
protected static void example() throws Exception {
// create a new, empty XML document
Doc2 libDoc = Doc2.createDocument();
// create the root element <Library> and add it to the document
LibraryType lib = libDoc.Library.append();
// set the "LastUpdated" attribute
com.altova.types.DateTime dt = new com.altova.types.DateTime(DateTime.now());
lib.LastUpdated.setValue(dt);
// create a new <Book> and populate its elements and attributes
BookType book = lib.Book.append();
book.ID.setValue(java.math.BigInteger.valueOf(1));
book.Format.setEnumerationValue( BookFormatType.EPAPERBACK );
book.Title.append().setValue("The XML Spy Handbook");
book.Author.append().setValue("Altova");
// create a dictionary (book of derived type) and populate its elements and attributes
DictionaryType dict = new DictionaryType(lib.Book.append().getNode());
dict.ID.setValue(java.math.BigInteger.valueOf(2));
dict.Title.append().setValue("English-German Dictionary");
dict.Format.setEnumerationValue(BookFormatType.EE_BOOK);
dict.Author.append().setValue("John Doe");
dict.FromLang.append().setValue("English");
dict.ToLang.append().setValue("German");
dict.setXsiType();
// set the schema location (this is optional)
libDoc.setSchemaLocation("Library.xsd");
// save the XML document to a file with default encoding (UTF-8). “true”使得文件进行了代码优化。
libDoc.saveToFile("Library1.xml", true);
} |
5.构建Java项目并运行它。如果成功运行代码,则会在项目目录中创建Library1.xml文件。
读取XML文档
1.在Eclipse文件菜单上,单击导入,选择现有项目到工作区,然后单击下一步。
2.在选择根目录旁边,单击浏览,,选择生成Java代码的目录并单击完成。
3.将下方代码以Library1.xml的形式保存到本地目录(您将需要从下方示例代码中引用Library1.xml文件的路径)。
<?xml version="1.0" encoding="utf-8"?>
<Library xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.nanonull.com/LibrarySample" xsi:schemaLocation="http://www.nanonull.com/LibrarySample Library.xsd" LastUpdated="2016-02-03T17:10:08.4977404">
<Book ID="1" Format="E-book">
<Title>The XMLSpy Handbook</Title>
<Author>Altova</Author>
</Book>
<Book ID="2" Format="Paperback" xmlns:n1="http://www.nanonull.com/LibrarySample" xsi:type="n1:DictionaryType">
<Title>English-German Dictionary</Title>
<Author>John Doe</Author>
<FromLang>English</FromLang>
<ToLang>German</ToLang>
</Book>
</Library> |
4.在Eclipse包资源管理器中,展开com.LibraryTest包并打开LibraryTest.java文件。
5.编辑Example()方法,如下所示:
protected static void example() throws Exception {
// load XML document from a path, make sure to adjust the path as necessary
Doc2 libDoc = Doc2.loadFromFile("Library1.xml");
// get the first (and only) root element <Library>
LibraryType lib = libDoc.Library.first();
// check whether an element exists:
if (!lib.Book.exists()) {
System.out.println("This library is empty.");
return;
}
// read a DateTime schema type
com.altova.types.DateTime dt = lib.LastUpdated.getValue();
System.out.println("The library was last updated on: " + dt.toDateString());
// iteration: for each <Book>...
for (java.util.Iterator itBook = lib.Book.iterator(); itBook.hasNext();) {
BookType book = (BookType) itBook.next();
// output values of ID attribute and (first and only) title element
System.out.println("ID: " + book.ID.getValue());
System.out.println("Title: " + book.Title.first().getValue());
// read and compare an enumeration value
if (book.Format.getEnumerationValue() == BookFormatType.EPAPERBACK)
System.out.println("This is a paperback book.");
// for each <Author>...
for (java.util.Iterator itAuthor = book.Author.iterator(); itAuthor
.hasNext();)
System.out.println("Author: " + ((com.Doc.xs.stringType) itAuthor.next()).getValue());
// find the derived type of this book
// by looking at the value of the xsi:type attribute, using DOM
org.w3c.dom.Node bookNode = book.getNode();
if (bookNode.getAttributes().getNamedItem("xsi:type") != null) {
// Get the value of the xsi:type attribute
String xsiTypeValue = bookNode.getAttributes().getNamedItem("xsi:type").getNodeValue();
// Get the namespace URI and lookup prefix of this namespace
String namespaceUri = bookNode.getNamespaceURI();
String lookupPrefix = bookNode.lookupPrefix(namespaceUri);
// If xsi:type matches the namespace URI and type of the book node
if (namespaceUri == "http://www.nanonull.com/LibrarySample"
&& ( xsiTypeValue.equals(lookupPrefix + ":DictionaryType" ))) {
// ...then this is a book of derived type (dictionary)
DictionaryType dictionary = new DictionaryType( book.getNode());
// output the value of the "FromLang" and "ToLang" elements
System.out.println("From language: " + dictionary.FromLang.first().getValue());
System.out.println("To language: " + dictionary.ToLang.first().getValue());
}
else
{
// throw an error
throw new java.lang.Error("This book has an unknown type.");
}
}
}
} |
6.构建Java项目并运行它。如果成功运行代码,程序代码会读取Library1.xml并将其内容显示在控制台视图中。
读取和编写元素和特性
使用生成的成员元素或特性类的getValue()方法可访问特性和元素的值。例如:
// output values of ID attribute and (first and only) title element
System.out.println("ID: " + book.ID.getValue());
System.out.println("Title: " + book.Title.first().getValue()); |
要在此示例中检索Title元素的值,我们还可以使用first()方法,因为这是图书的第一个(也是唯一一个)Title元素。如果要按索引从列表中选择一个特定元素,则使用at() 方法。
要在多个元素中迭代,请使用基于索引的迭代或java.util.Iterator。例如,您可以迭代访问Library的所有图书,如下所示:
// index-based iteration
for (int j = 0; j < lib.Book.count(); ++j ) {
// your code here
}
// alternative iteration using java.util.Iterator
for (java.util.Iterator itBook = lib.Book.iterator(); itBook.hasNext();) {
// your code here
} |
要添加新元素,请使用append()方法。例如,以下代码将一个空的根Library元素追加到文档:
// create the root element <Library> and add it to the document
LibraryType lib = libDoc.Library.append(); |
在追加元素后,您可以使用setValue()方法设置其元素或特性的值。
// set the value of the Title element
book.Title.append().setValue("The XML Spy Handbook");
// set the value of the ID attribute
book.ID.setValue(java.math.BigInteger.valueOf(1)); |
读取和编写枚举值
如果简单类型在您的XML Schema中定义为枚举,则枚举值将在生成的代码中作为Enum值可用。在本例使用的Schema中,有精装、平装、电子书等图书格式。因此,在生成的代码中,这些值以Enum的形式提供(请参见上图中的BookFormatType类)。要将枚举值分配给对象,请使用如下代码:
// set an enumeration value
book.Format.setEnumerationValue( BookFormatType.EPAPERBACK ); |
您可以按如下方式从XML实例文档中读取此类枚举值:
// read an enumeration value
if (book.Format.getEnumerationValue() == BookFormatType.EPAPERBACK)
System.out.println("This is a paperback book." |
当“if”条件不充分时,创建一个开关以获取每个枚举值并根据需要对其进行处理。
使用xs:dateTime和xs:duration类型
如果您从中生成代码的Schema使用时间和持续时间类型,例如xs:dateTime或xs:duration,这些将在生成的代码中转换为Altova本机类。因此,要将日期或持续时间值写入XML文档,请执行以下操作:
1.构建一个com.altova.types.DateTime或com.altova.types.Duration对象。
2.将对象设为所需元素或特性的值,例如:
// set the value of an attribute of DateTime type
com.altova.types.DateTime dt = new com.altova.types.DateTime(DateTime.now());
lib.LastUpdated.setValue(dt); |
要从XML文档读取日期或持续时间,请执行以下操作:
1.将元素值(或特性)声明为com.altova.types.DateTime或com.altova.types.Duration对象。
2.对所需的元素或特性进行格式设置,例如:
// read a DateTime type
com.altova.types.DateTime dt = lib.LastUpdated.getValue();
System.out.println("The library was last updated on: " + dt.toDateString()); |
有关更多信息,请参见com.altova.types.DateTime和com.altova.types.Duration类引用。
使用派生类型
如果您在XML Schema中定义了派生类型,则可以在以编程方式创建或加载的XML文档中保留类型派生。以本例中使用的Schema为例,以下代码片段展示了如何创建一个DictionaryType派生类型的新书:
// create a dictionary (book of derived type) and populate its elements and attributes
DictionaryType dict = new DictionaryType(lib.Book.append().getNode());
dict.ID.setValue(java.math.BigInteger.valueOf(2));
dict.Title.append().setValue("English-German Dictionary");
dict.Format.setEnumerationValue(BookFormatType.EE_BOOK);
dict.Author.append().setValue("John Doe");
dict.FromLang.append().setValue("English");
dict.ToLang.append().setValue("German");
dict.setXsiType(); |
请注意,为新创建的书设置xsi:type特性是很重要的。这确保了在验证XML文档时,Schema可以正确解释图书类型。
以下代码片段显示了当从XML文档加载数据时,如何在加载的XML实例中标识派生类型DictionaryType的图书。首先,代码找到图书节点的xsi:type特性的值。如果此节点的命名空间URI是http://www.nanonull.com/LibrarySample,并且URI查找前缀和类型与xsi:type特性的值匹配,则它是一个字典:
// find the derived type of this book
// by looking at the value of the xsi:type attribute, using DOM
org.w3c.dom.Node bookNode = book.getNode();
if (bookNode.getAttributes().getNamedItem("xsi:type") != null) {
// Get the value of the xsi:type attribute
String xsiTypeValue = bookNode.getAttributes().getNamedItem("xsi:type").getNodeValue();
// Get the namespace URI and lookup prefix of the book node
String namespaceUri = bookNode.getNamespaceURI();
String lookupPrefix = bookNode.lookupPrefix(namespaceUri);
// If xsi:type matches the namespace URI and type of the book node
if (namespaceUri == "http://www.nanonull.com/LibrarySample"
&& ( xsiTypeValue.equals(lookupPrefix + ":DictionaryType" ))) {
// ...then this is a book of derived type (dictionary)
DictionaryType dictionary = new DictionaryType( book.getNode());
// output the value of the "FromLang" and "ToLang" elements
System.out.println("From language: " + dictionary.FromLang.first().getValue());
System.out.println("To language: " + dictionary.ToLang.first().getValue());
}
else
{
// throw an error
throw new java.lang.Error("This book has an unknown type.");
}
} |