Zwar ist das PDF-Format heutzutage im Geschäftsleben allgegenwärtig, doch können in PDF-Dokumenten enthaltene Daten nicht ohne Weiteres für das Mappen auf andere Systeme genutzt werden. PDF-Dokumente sind normalerweise für vom Menschen lesbare Inhalte mit verschiedenen Formatierungen und Layouts gedacht, wodurch die Extraktion strukturierter Daten zu einer Herausforderung wird. PDF-Dokumente können Text, Bilder, Tabellen und andere Elemente enthalten, wobei die Daten nicht in einem maschinenlesbaren Format strukturiert sind. Normale Tools zur Extraktion von PDF-Daten liefern oft, vor allem bei PDF-Dokumenten mit komplexem Layout, keine genauen Ergebnisse. Zu diesem Zweck haben wir den MapForce PDF Extractor entwickelt.
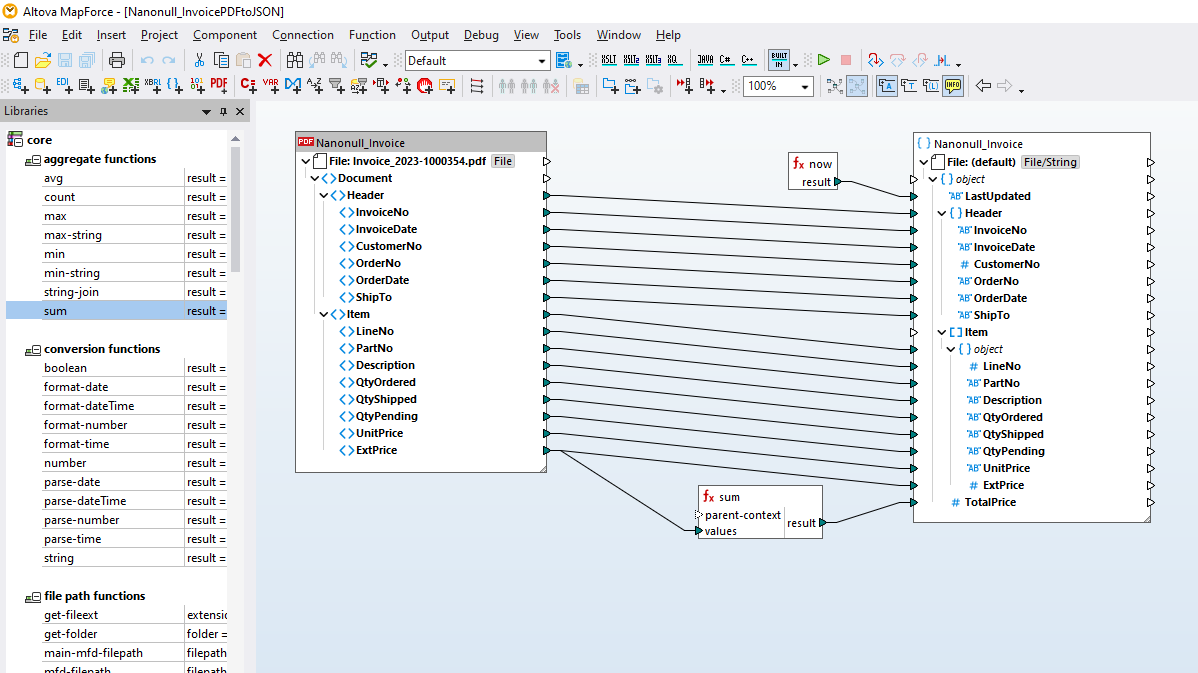
Der MapForce PDF Extractor ist ein einfach zu verwendendes Tool zum schnellen Definieren der Struktur eines PDF-Dokuments und zum Extrahieren von Daten daraus. Die PDF-Daten können anschließend in MapForce für die weitere Transformation und Konvertierung in andere Formate wie XML, JSON, Datenbanken, Excel, usw. aufgerufen werden. Der Extractor ist das ultimative Tool, mit dem die PDF-Datenintegration und ETL-Projekte möglich werden.
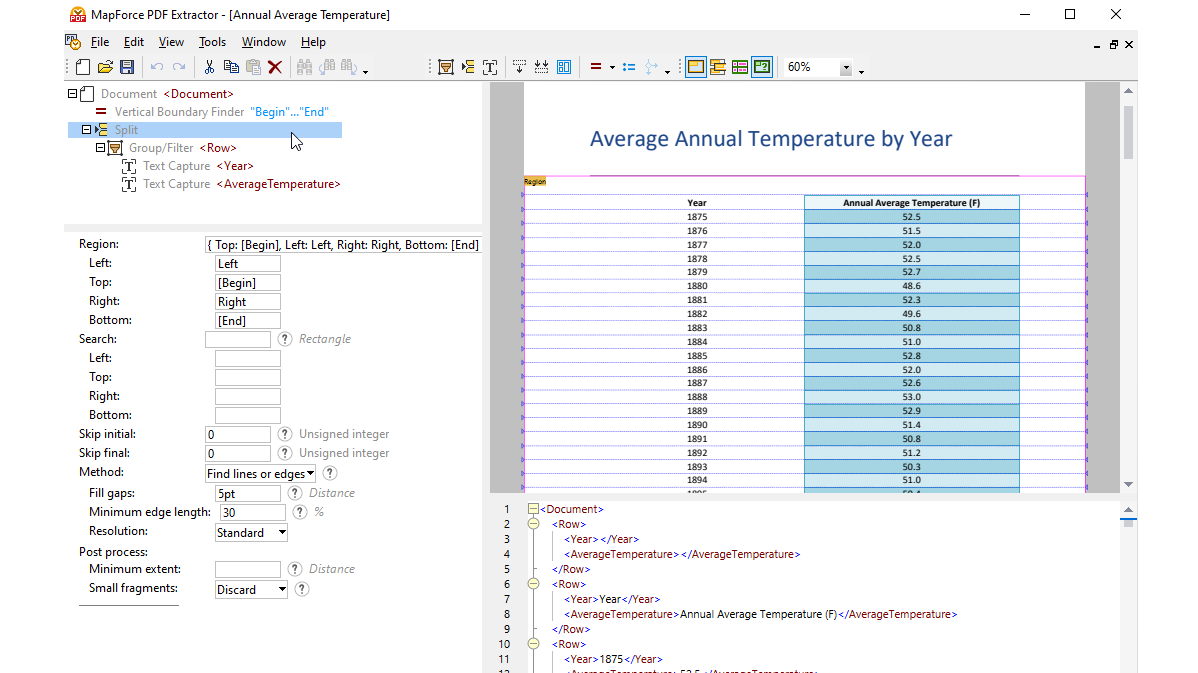
Mit Hilfe visueller Tools können Sie im MapForce PDF Extractor die Struktur eines PDF-Dokuments definieren und Daten effizient extrahieren. PDF Extractor ist ein extrem flexibles Tool, mit dem Sie anstelle des gesamten Dokuments nur Teile eines Texts extrahieren, Datenbereiche aus verschiedenen Seiten derselben PDF-Datei miteinander kombinieren, Tabellen in Zeilen aufteilen und Daten in Gruppen zusammenfassen können.

Dank des intuitiven, übersichtlichen Designs von MapForce PDF Extractor lässt sich die Struktur von PDF-Dokumenten schnell und einfach mit der Maus mittels Point-and-Click und Drag-and-Drop visuell definieren. Endlich stehen die riesigen Datenmengen aus PDF-Dokumenten nun für das Mapping auf andere Formate zur Verfügung.