Aunque el PDF es un formato de datos omnipresente en las empresas hoy en día, no es fácil asignar los datos contenidos en este formato a otros sistemas. Los PDF suelen estar diseñados con formatos y diseños variables para que el contenido sea legible para el lector. Esto dificulta enormemente la extracción de datos estructurados. Estos documentos pueden contener texto, imágenes, tablas y otros elementos. Esto significa que los datos no están organizados en un formato que una máquina pueda leer o descifrar con facilidad. Las herramientas habituales de extracción de datos PDF no suelen dar resultados correctos, sobre todo cuando se trata de un PDF con una estructura compleja. Ahí es donde entra en juego MapForce PDF Extractor.
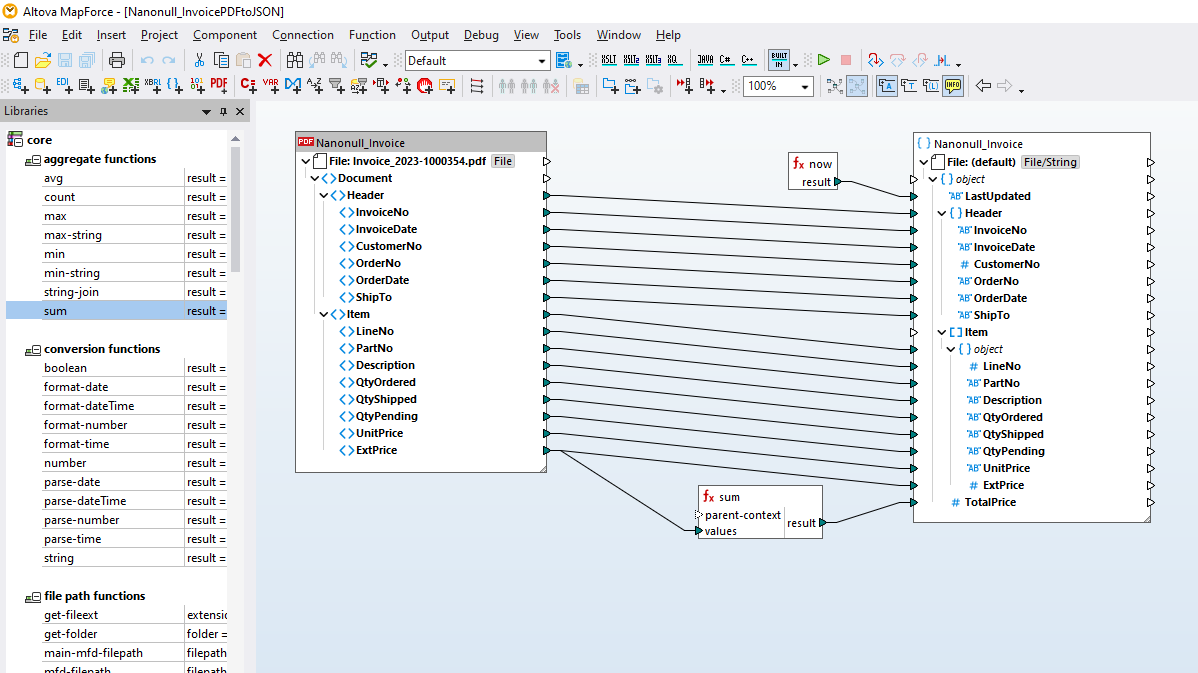
Las herramientas de asignación de datos en MapForce incluyen la utilidad MapForce PDF Extractor que es fácil de usar y permite definir rápidamente la estructura y extraer datos de un documento PDF. Después, se puede acceder a esos datos PDF para su transformación y conversión a otros formatos como XML, JSON, bases de datos, Excel, etc., directamente en MapForce. Es la herramienta más avanzada para facilitar la integración de datos PDF y los proyectos ETL.
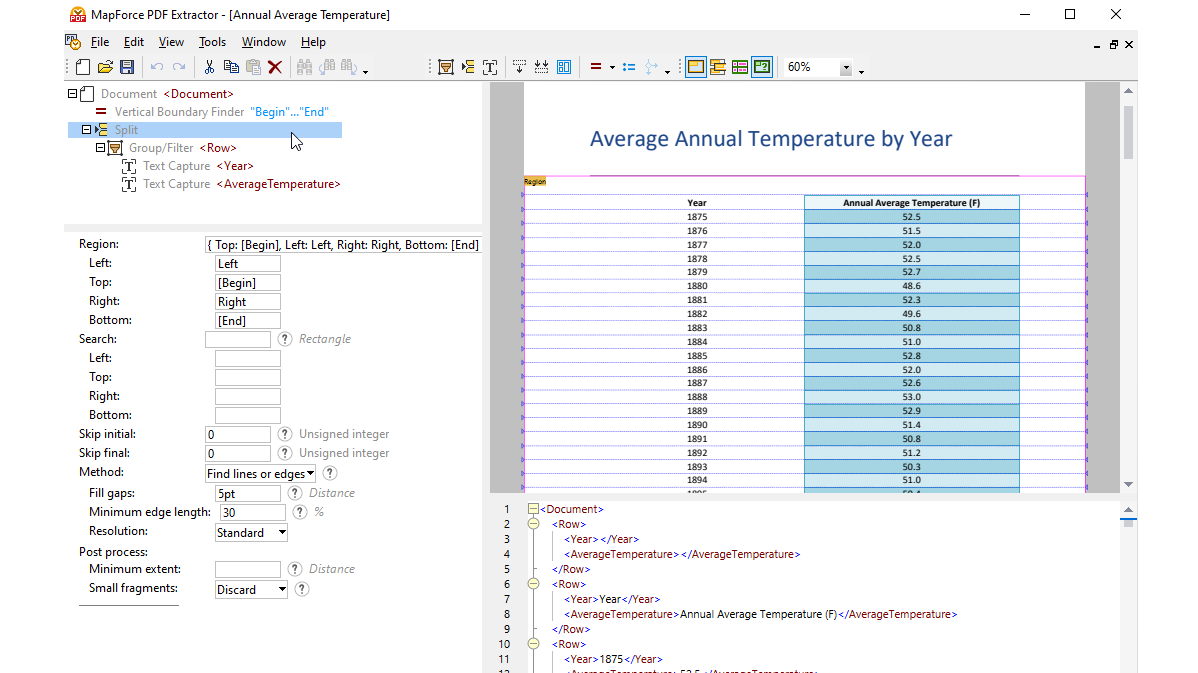
A través de las herramientas visuales en MapForce PDF Extractor puede definir la estructura y extraer los datos de un documento PDF de manera eficaz. MapForce PDF Extractor es una herramienta de gran flexibilidad que le permite extraer partes del texto en lugar de todo el documento, mezclar y combinar fragmentos de información de diferentes páginas del mismo archivo PDF, dividir tablas en filas y organizar los datos en grupos.

El diseño de MapForce PDF Extractor es sencillo y fácil de usar, lo que facilita definir rápidamente la estructura del documento PDF de forma visual, con funciones como ‘apuntar y hacer clic’ y ‘arrastrar y soltar’. Por fin, los enormes volúmenes de datos que antes estaban encerrados en PDF están disponibles para pasarlos a otros formatos.