Bien que le PDF soit un format de données omniprésent dans l’environnement professionnel de nos jours, les données contenues dans les PDF ne sont pas disponibles pour les autres systèmes. Les PDF sont généralement conçus pour du contenu lisible pour les hommes avec un formatage et des mises en page variables, rendant l’extraction des données structurée très difficile. Ils peuvent contenir du texte, des images, des tables, et d’autres éléments et les données ne sont pas organisées dans un format lisible aux appareils. Les outils d’extraction de données PDF typiques ne peuvent éventuellement pas fournir de résultats précis, en particulier pour des PDF avec des mises en page complexes. C’est à cet instant que l’Extracteur PDF de MapForce entre en jeu.
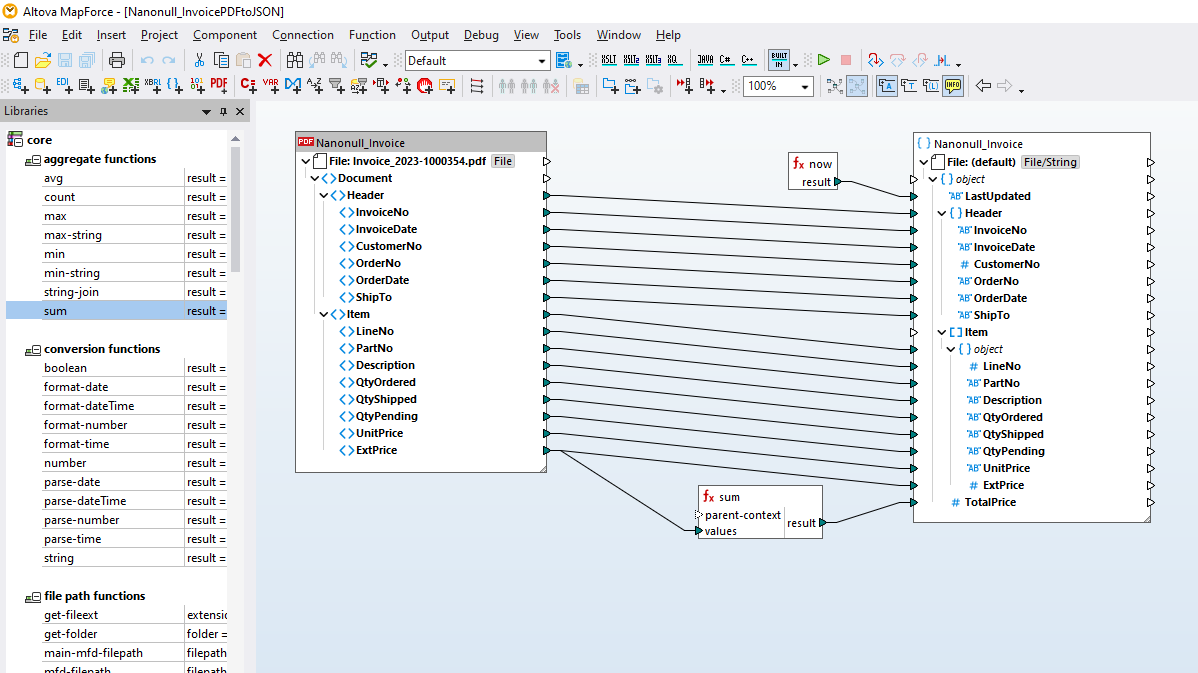
L’outil de mappage de données de MapForce inclut l’Extracteur PDF de MapForce, un utilitaire facile à utiliser qui vous permet de définir rapidement la structure d’un document PDF et en extraire les données. Puis, ces données PDF peuvent être accédées pour une transformation et conversion ultérieures vers d’autres formats tels que XML, JSON, bases de données, Excel, etc. dans MapForce. Il s’agit de l’outil ultime qui permet d’activer l’intégration des données PDF et les projets ETL.
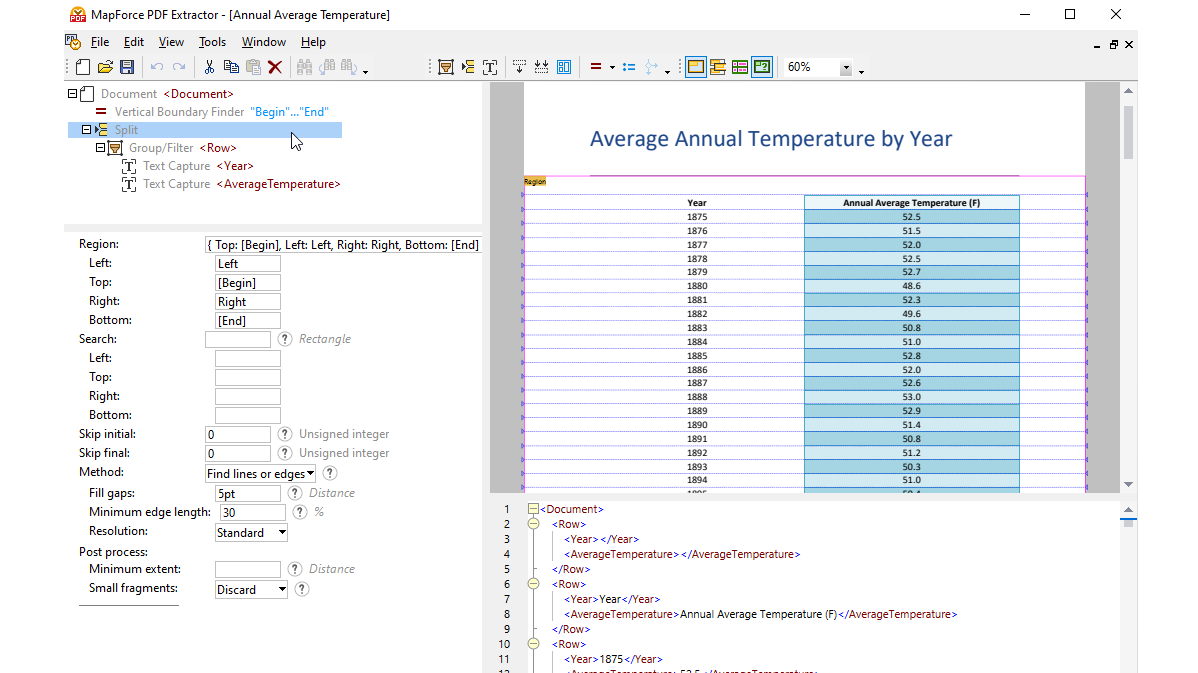
En utilisant les outils visuels dans l’Extracteur PDF de MapForce, vous pouvez définir la structure d’un document PDF et extraire ses données de manière efficace. L’Extracteur PDF est un outil hautement flexible qui vous permet d’extraire uniquement des portions de texte à la place du document entier, mélanger et faire correspondre des morceaux d’information depuis différentes pages du même fichier PDF, fractionner des tables en lignes et arranger des données en groupes.

Son utilisation facile et sa conception claire dans l’Extracteur PDF de MapForce rend le travail visuel de définition de la structure du document PDF facile, en utilisant les fonctions pointer-et-cliquer ainsi que glisser-et-déposer. Les grands volumes de données bloqués dans les PDF sont enfin disponibles pour les mappages vers d’autres formats.