Execution Result
FlowForce Server enables you to declare the return type of a job. When you declare the return type, keep in mind the following points:
•Declaring the return type is mandatory if you want to process the return value of a job in another job (see example below).
•Declaring the return type is meaningful only for jobs that actually return a result.
•Declaring the return type is also mandatory if you want to cache the result of a job.
•The return type of a job must be the same as the data type of the last step in the job. Otherwise, FlowForce Server returns an error. To avoid data type-matching errors, use expression functions to change the data type of the last step in the job to the data type declared as the job return type.
How to define the return type
To define the return type of a job, take the following steps:
1.Create a new job or open an existing one for editing.
2.Select a return type in the Execution Result section on the Configuration page.
Return types
The available return types are listed below.
•ignore/discard
•string
•stream
•number
•boolean
•credential
•certificate
•result
•AS2 partner (Advanced Edition)
•AS2 MDN (Advanced Edition)
•SFTP connection (Advanced Edition)
The default option is ignore/discard. It instructs FlowForce Server to ignore or discard the result of a job. Select this option if the job does not return a result or if you do not need to process the returned result in any way.
About the result type
A return value of type result represents the outcome of a step function (e.g., a step that executes a MapForce mapping; a step that executes a shell command). You can access and manipulate the contents of the result, using the following expression functions:
•stdout: Takes a result of type result as its argument and produces a stream.
•stderr: Returns the standard error of the result.
•results: Returns a list of all the result streams.
•exitcode: Returns the numeric exit code of the result (if available).
•error-message: Returns a textual error message (if available)
Example
This example explains how to access the return value of a job in another job. The configuration procedures comprise two stages:
1.First, we configure a job that executes a MapForce mapping. This mapping produces multiple output files.
2.Second, we configure another job that calls the mapping in one of its steps, selects only one output file, and copies this file to the target directory.
Job 1: Run deployed MapForce mapping
To be able to create a FlowForce job that executes a MapForce mapping, we first need to deploy this mapping to FlowForce Server. See also the MapForce Mapping as a Scheduled Job tutorial for more details. For this example, we have chosen the following mapping that is shipped together with MapForce: MapForceExamples\SplitFiles.mfd (screenshot below). This mapping produces multiple output files, whose names are created dynamically, based on the parameters supplied to the mapping.
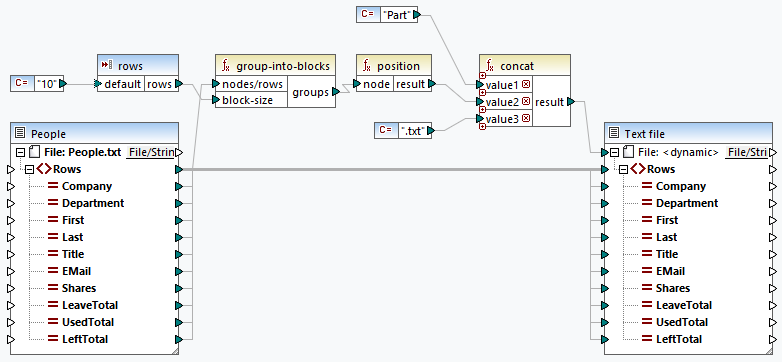
After deploying this mapping to FlowForce Server, we have configured the following job:
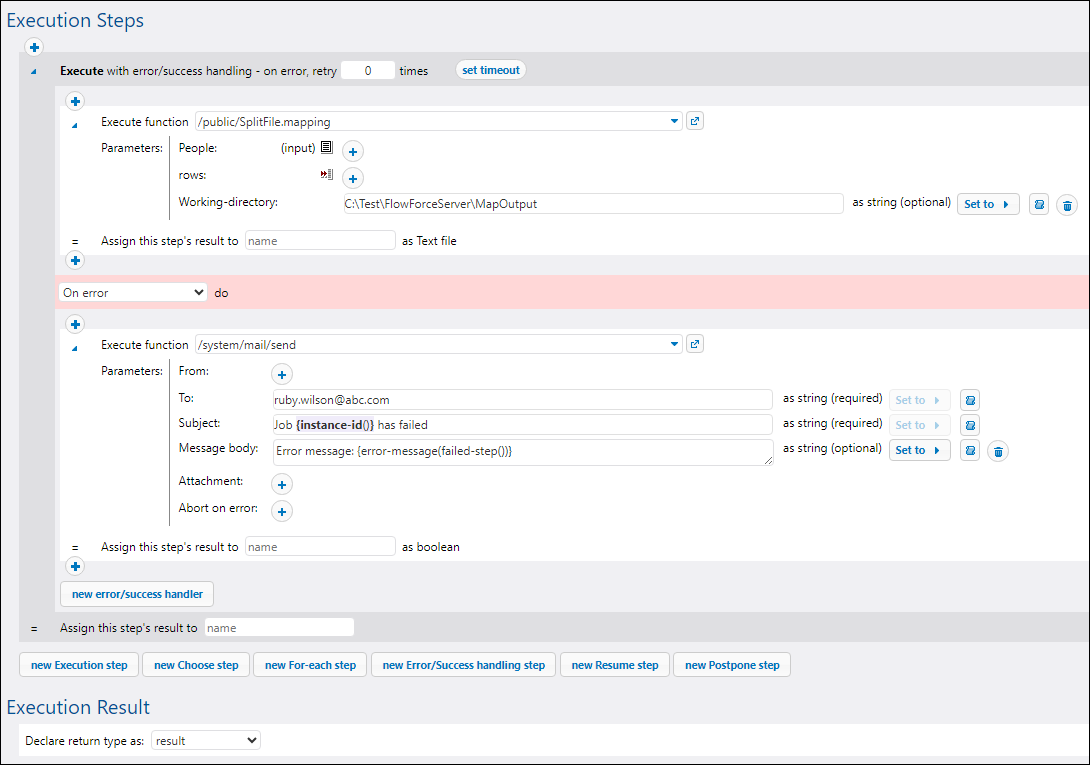
The job has an Error/Success Handling block that executes the mapping and copies output files to the path indicated in the Working Directory field. If the execution of the mapping fails, the On-Error step will be executed, i.e., an email containing an error message will be sent to the specified recipient. Note that to be able to send emails, you must first configure the SMTP settings.
Since this job produces a result that we intend to use in another job, we must declare the return value of the job. In order to do this, we have selected result from the dropdown list of the Execution Result section (screenshot above). Note that if you do not declare the return type of the job, you will not be able to access the job's result in another job, and saving this other job will not be possible.
To run the job, supply your credentials.
For details about integrating FlowForce Server with MapForce and other Altova products, see Integration with Altova Products.
Job 2: Call the mapping and select only one output
The goal of the second job is to call the job with the deployed mapping, select only one output file, and output this file to the target directory. The screenshot below illustrates the configuration of this job.
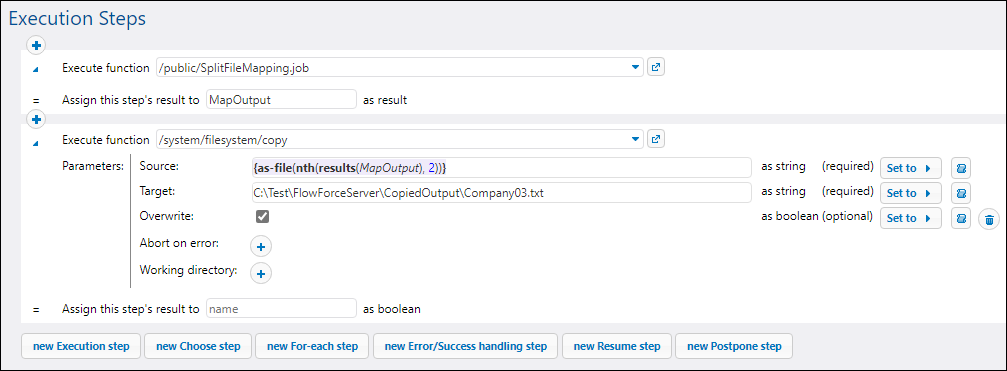
The first step executes Job 1 that we have just configured. We have assigned the step's result to the value MapOutput of type result. This will enable us to use this step's return value in the second step.
In the second step, we call the copy system function that copies the source file to the destination folder. The Source field contains the following expression:
{as-file(nth(results(MapOutput), 2))}
The results function converts the result of the mapping step to a list of result streams. The nth function takes the list of streams as its first argument and selects the third item (the nth function is zero-based). The as-file function creates a file from the stream. The output file called Company03.txt will be saved at the path specified in the Target field. If the target file already exists, it will be overwritten.
Note that the expression is enclosed in the curly braces. This is because the Source field expects a string. For details about expressions and their syntax, see Expressions.
Declaring the return type of the second job is not necessary, because we do not intend to use this job's return value in any other jobs.
To test the job, supply your credentials and set a trigger that will fire the job.
Output of Job 2
After the job has fired, Company03.txt has successfully been saved in the destination folder. The file contains the following details:
"Nanonull Europe, AG",Research & Development,Valentin,Rutger,R&D Manager,v.rutger@nanonull.com,1500,28,21,7
"Nanonull Europe, AG",Research & Development,Gaia,Winkler,Research Scientist,g.winkler@nanonull.com,500,22,5,17
"Nanonull Europe, AG",Research & Development,Felipe,Gomez,Research Scientist,f.gomez@nanonull.com,500,20,6,14
"Nanonull Europe, AG",Research & Development,Mirko,Filipcic,Research Scientist,m.filipcic@nanonull.com,500,21,8,13
"Nanonull Europe, AG",Research & Development,Norbert,Riedler,Research Scientist,n.riedler@nanonull.com,1500,18,2,16
"Nanonull Europe, AG",Research & Development,Sabine,Kraus,Research Scientist,s.kraus@nanonull.com,0,18,7,11
"Nanonull Europe, AG",Research & Development,Robert,Manko,Research Scientist,r.manko@nanonull.com,500,20,10,10
"Nanonull Europe, AG",Research & Development,Mandy,Mitchell,Research Scientist,m.mitchell@nanonull.com,500,19,6,13
"Nanonull Europe, AG",Research & Development,Lempel,Wenzl,Research Scientist,l.wenzl@nanonull.com,0,28,3,25
"Nanonull Europe, AG",Research & Development,Max,Matzik,Research Scientist,m.matzik@nanonull.com,0,19,5,14