Ejemplo: filtrar con el contexto de prioridad
Cuando se conecta una función a un filtro, el contexto de prioridad no solo afecta a la función en sí, sino también a la evaluación del filtro. La asignación de la imagen siguiente muestra un caso típico en el que es necesario usar el contexto de prioridad para obtener el resultado correcto. Puede encontrar esta asignación en la ruta: <Documentos>\Altova\MapForce2023\MapForceExamples\Tutorial\FilterWithPriority.mfd.
| Nota: | esta asignación usa componentes XML, pero otros tipos de componentes de MapForce obedecen a la misma lógica, incluidos EDI, JSON, etc. Para las bases de datos se recomienda filtrar con componentes SQL WHERE en lugar de filtros estándar. |
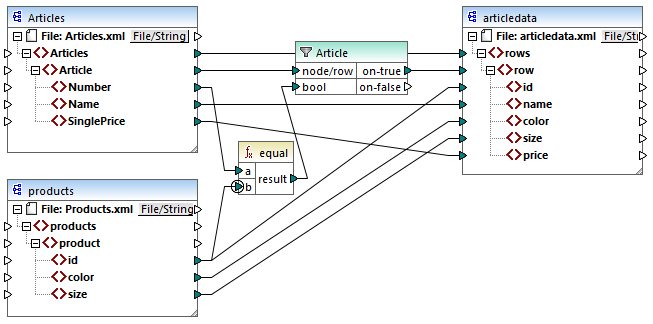
El objetivo de esta asignación es copiar datos de personas de Articles.xml en un archivo XML nuevo con un esquema distinto, articledata.xml. Al mismo tiempo, la asignación debería buscar los detalles de cada artículo en el archivo Products.xml y combinarlos con el registro de archivo correspondiente. Observe que cada registro de Articles.xml tiene un elemento Numbers y cada registro en Products.xml tiene un elemento id. Si estos dos valores son iguales, entonces todos los otros valores () se deben copiar a la misma fila en el destino.
Para conseguir este objetivo se ha añadido un filtro. Cada filtro requiere una condición booleana como entrada; solamente aquellos nodos/filas que cumplan con esa condición se copian en el destino, para lo que se ha incluido una función equal a la asignación. La función equal comprueba si el número de artículo y el ID del producto son iguales en ambos orígenes. El resultado se suministra como entrada para el filtro. Si es true, entonces el elemento Article se copia en el destino.
Observe que se ha definido un contexto de prioridad en el segundo parámetro de entrada de la segunda función equal. En esta asignación no incluir el contexto de prioridad en la asignación resultaría en un resultado incorrecto.
Asignación inicial: sin contexto de prioridad
Esta es la lógica de la asignación sin contexto de prioridad:
•Conforme a la regla general de asignación, por cada elemento Article que cumpla con la condición del filtro se crea una fila nueva en el destino. La conexión entre Article y row (mediante la función y el filtro) se encarga de ello.
•El filtro comprueba la condición de cada artículo. Para ello, recorre todos los productos y trae varios productos al contexto actual.
•Para rellenar el id en el lado de destino, MapForce sigue la regla general (por cada elemento de origen se crea uno de destino). Sin embargo, como hemos explicado más arriba, todos los productos de Products.xml están en el contexto actual. No hay ninguna conexión entre product y otro lugar del destino de forma que se lea el id de un producto en concreto. En consecuencia, se crearán varios elementos id por cada Article en el destino. Lo mismo ocurre con color y size.
En resumen: los elementos de Products.xml tienen el contexto del filtro (que debe recorrer todos los productos); por tanto, los valores id, color y size se copiarán en cada fila de destino tantas veces como productos haya en el archivo de origen, lo que generará un resultado incorrecto, como este:
<rows> |
Solución A: use contexto de prioridad
El problema anterior se soluciona añadiendo un contexto de prioridad a la función que computa la condición booleana del filtro.
En concreto, si el segundo parámetro de entrada de la función equal se designa como contexto de prioridad, la secuencia proveniente de Products.xml se prioriza. Esto se traduce en la siguiente lógica de asignación:
•Por cada producto se rellena la entrada b de la función equal (en otras palabras, se prioriza b). En este punto, los detalles del producto actual están en contexto.
•Por cada artículo se rellena la entrada a de la función equal y se comprueba si la condición del filtro es true. Si lo es, entonces los detalles del artículo también se añaden al contexto actual.
•A continuación, se copian los detalles del artículo y del producto desde el contexto actual a los elementos correspondientes del destino.
La lógica de asignación anterior produce un resultado correcto, por ejemplo:
<rows> |
Solución B: usar una variable
Una solución alternativa es llevar al mismo contexto a cada artículo y producto que cumpla con la condición del filtro, con ayuda de una variable intermedia. Las variables se pueden usar en escenarios como este porque permiten almacenar datos de forma temporal en la asignación, lo que permite cambiar el contexto según lo necesite.
Para escenarios como este puede añadir a la asignación una variable que tiene el mismo esquema que el componente de destino. En el menú Insertar, haga clic en Insertar, después en Variable y proporcione el esquema articledata.xml como estructura cuando la aplicación se lo pida.
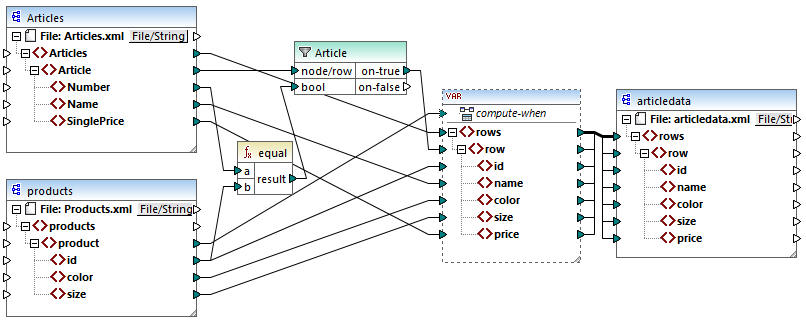
En la asignación anterior ocurre lo siguiente:
•El contexto de prioridad ya no se usa. En su lugar hay una variable que tiene la misma estructura que el componente de destino.
•Como es habitual, la ejecución de la asignación empieza en el nodo raíz de destino. Antes de rellenar el destino, la asignación recopila datos en la variable.
•La variable se computa en el contexto de cada producto. Esto ocurre porque existe una conexión desde product hasta la entrada compute-when de la variable.
•La condición del filtro se comprueba en el contexto de cada producto. La estructura de la variable solo se rellena y se pasa al destino si se cumple esta condición.