tokenize
Splits the input string into a sequence of strings using the delimiter supplied as argument.

Languages
Built-in, C++, C#, Java, XQuery, XSLT 2.0, XSLT 3.0.
Parameters
Name | Description |
|---|---|
input | The input string. |
delimiter | The delimiter to use. |
Example
If the input string is A,B,C and the delimiter is , then the function returns a sequence of three strings: A, B, and C.
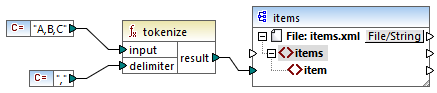
In the mock-up mapping illustrated above, the function's result is a sequence of strings. According to the general mapping rules, for each item in the source sequence, a new item is created in the target component. Consequently, the mapping output looks as follows:
<items> |
For a more elaborate example, see the tokenizeString1.mfd mapping available in the <Documents>\Altova\MapForce2025\MapForceExamples\ folder.
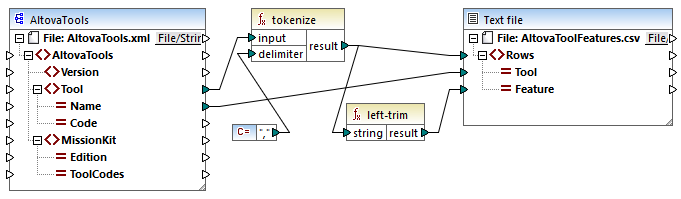
tokenizeString1.mfd
A fragment from the source XML file is shown below. The Tool element has two attributes: Name and Code. The Tool element data consists of comma-delimited text.
<?xml version="1.0" encoding="UTF-8"?> |
The mapping does the following:
•The tokenize function receives data from the Tool source item and uses the comma , delimiter to split that data into separate chunks. The first chunk is "XML editor", the second one is "XSLT editor", and so on.
•For each chuck resulting from the tokenize function, a new row is generated in the target. This happens thanks to the connection between the function's result and the Rows item in the target component.
•The result of the tokenize function is also mapped to the left-trim function, which removes the leading white space of each chunk.
•The result of the left-trim function (each chunk) is written to the Feature item of the target component.
•The target component output file has been defined as a CSV file (AltovaToolFeatures.csv) with the field delimiter being a semicolon (double click component to see settings).
The result of the mapping is that, for each chunk created by the tokenize function, a new row is created in the target CSV file. A fragment of the mapping output looks as follows:
Tool;Feature XMLSpy;XML editor XMLSpy;XSLT editor XMLSpy;XSLT debugger XMLSpy;XQuery editor XMLSpy;XQuery debugger XMLSpy;XML Schema / DTD editor XMLSpy;WSDL editor XMLSpy;SOAP debugger MapForce;Data integration MapForce;XML mapping MapForce;database mapping MapForce;text conversion MapForce;EDI translator MapForce;Excel mapping |