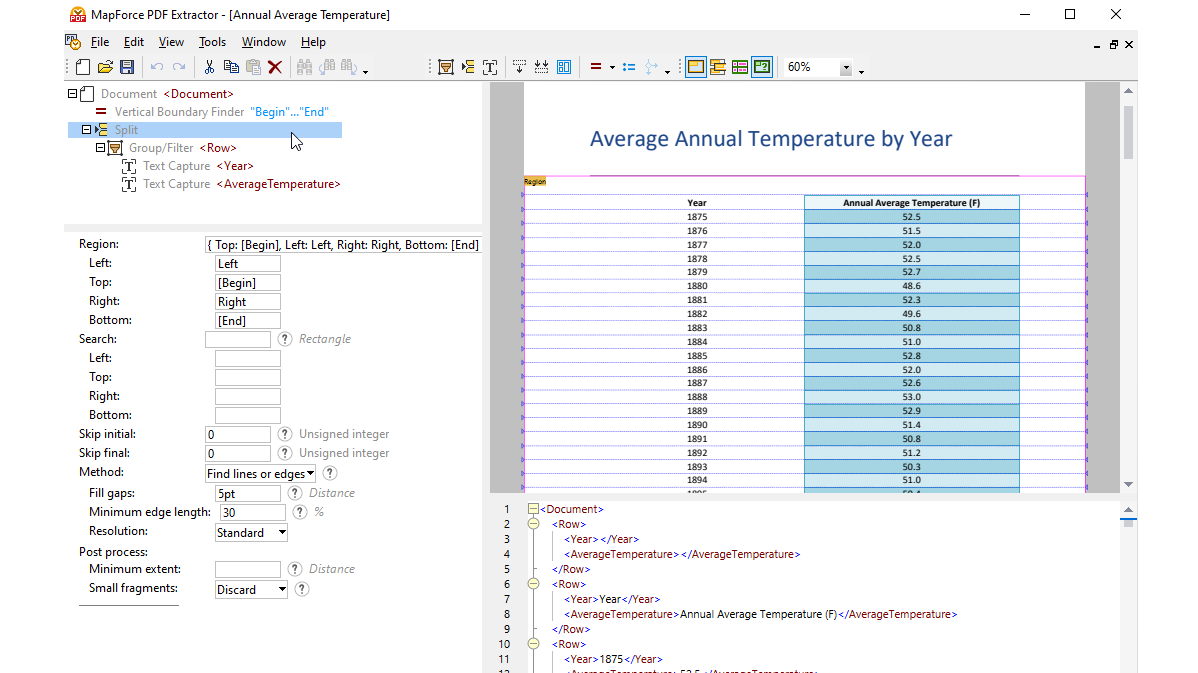
Though PDF is a ubiquitous data format in business today, data contained in PDFs is not readily available for mapping to other systems. PDFs are typically designed for human-readable content with variable formatting and layouts, making structured data extraction extremely challenging. They may contain text, images, tables, and other elements, and the data is not organized in a machine-readable format. Typical PDF data extraction tools may not provide accurate results, especially for PDFs with complex layouts. That's where the MapForce PDF Extractor comes in.
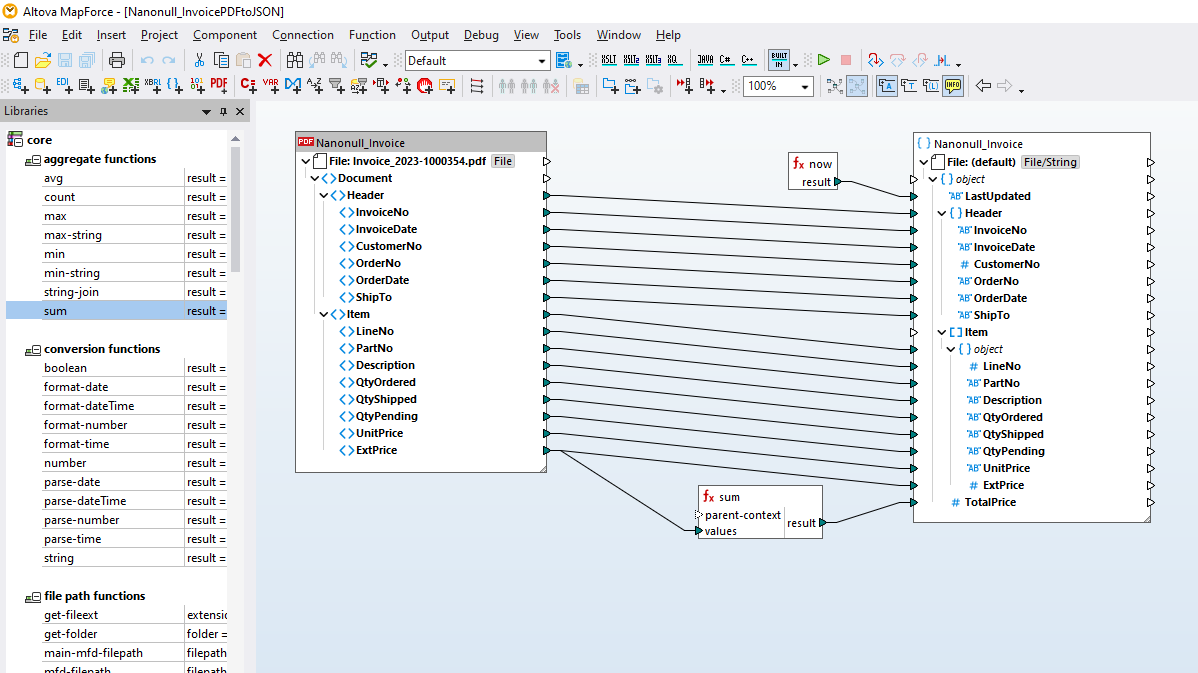
The MapForce PDF Extractor is an easy-to-use utility that allows you to quickly define the structure of a PDF document and extract data from it. Then, that PDF data can be accessed for further transformation and conversion to other formats such as XML, JSON, databases, Excel, and so on, in MapForce. It is the ultimate tool for enabling PDF data integration and ETL projects.
Using visual tools in the MapForce PDF Extractor, you can define the structure of a PDF document and efficiently extract its data. PDF Extractor is a highly flexible tool that allows you to extract only portions of text instead of the whole document, mix and match pieces of information from different pages of the same PDF file, split tables into rows, and arrange data into groups.

The intuitive, straightforward design of the MapForce PDF Extractor makes it easy to define PDF document structure in a visual way, using point-and-click and drag-and-drop functionality. At last, the vast volumes of data previously locked in PDFs is available for mapping to other formats.