Example: Changing the Parent Context
Some mapping components have an optional parent-context item.
The parent-context argument is an optional argument in some MapForce core aggregation functions (e.g., min, max, avg, count). In a source component which has multiple hierarchical sequences, the parent context determines the set of nodes on which the function should operate.
With the help of this item you can influence the mapping context in which that component should operate and consequently change the mapping output. The components that have an optional parent-context are: aggregate functions, variables, and Join components.
For a demo of how changing the parent context is useful, open the following mapping: <Documents>\Altova\MapForce2023\MapForceExamples\Tutorial\ParentContext.mfd.
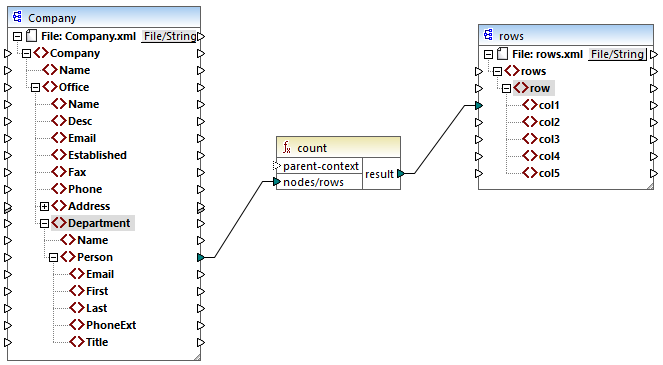
In the source XML of the mapping above, there is a single Company node which contains two Office nodes. Each Office node contains multiple Department nodes, and each Department contains multiple Person nodes. If you open the XML file in an XML editor, you can see that the distribution of people by office and department is as follows:
Office | Department | Number of people |
|---|---|---|
Nanonull, Inc. | Administration | 3 |
Marketing | 2 | |
Engineering | 6 | |
IT & Technical Support | 4 | |
Nanonull Partners, Inc. | Administration | 2 |
Marketing | 1 | |
IT & Technical Support | 3 |
The mapping counts all people in all departments. For this purpose, it uses the count function from the core library. If you click the Output pane to preview the mapping, you will notice that it produces a single value, 21, which corresponds to the total number of people in the source XML file.
The mapping works as follows:
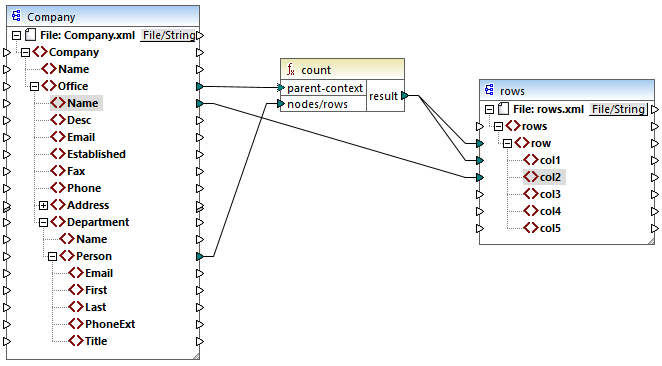
•As usual, the mapping execution starts from the top node of the target component (rows, in this example). There is no incoming connection to rows. As a result, an implicit mapping context is established between Company (top item of the source component) and rows (top item of the target component).
•The function's result is a single value, because there is only one company in the source file.
•To populate the col1 target item, MapForce executes the count function in the implicit parent context mentioned above, so it will count all Person nodes from all offices and from all departments.
The parent-context argument of the function lets you change the mapping context. This enables you, for example, to count the number of people in each department. To do this, draw two more connections as shown below:
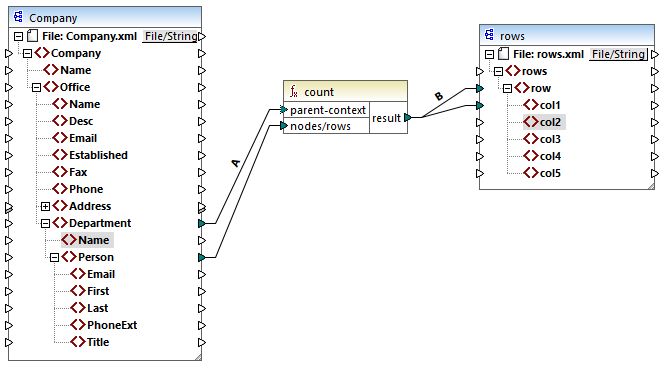
In the mapping above, connection A changes the parent context of the count function to Department. As a result, the function will count the number of people in each department. Very importantly, the function will now return a sequence of results instead of a single result, because multiple departments exist in the source. This is the reason why connection B exists: for each item in the resulting sequence it creates a new row in the target file. The mapping output has now changed accordingly (notice the numbers correspond exactly to the count of people in each department):
<rows> |
Given that the current mapping creates a row for each department, you can optionally copy the office name and the department name as well into the target file, by drawing connections C and D:
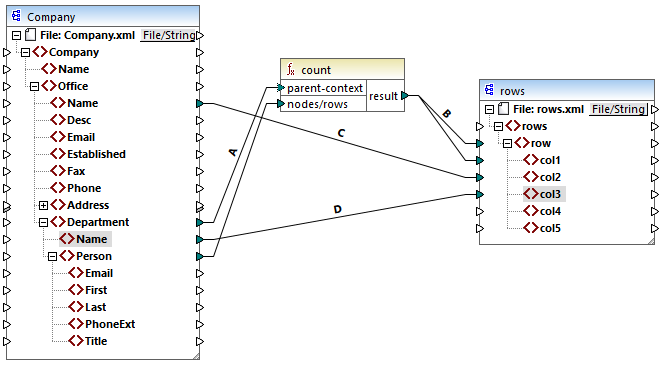
This way, the output will display not only the count of people but also the corresponding office and department name.
If you would like to count the number of people in each office, connect the parent context of count function to the Office item in the source.
With the connections shown above, the count function returns one result for each office. There are two offices in the source file, so the function will now return two sequences. Consequently, there will be two rows in the output, where each row is the number of people in that office:
<rows> |