Gruppierungsfunktionen
Wenn in Ihrem Mappings Nodes oder Zeilen gruppiert werden müssen, können Sie dies mit Hilfe der folgenden vordefinierten MapForce-Funktionen tun:
•group-by
•group-adjacent
•group-into-blocks
•group-starting-with
•group-ending-with
Um eine dieser Funktionen im Mapping zu verwenden, ziehen Sie sie aus dem Fenster "Bibliotheken" in das Mapping. Siehe auch Hinzufügen einer Funktion zu einem Mapping.
| Anmerkung: | Gruppierfunktionen stehen in den folgenden Sprachen nicht zur Verfügung: XSLT 2.0, XSLT 3.0, C++, C#, Java, Built-In. |
In den folgenden Abschnitten finden Sie typische Verwendungsbeispiele für die Gruppierung von Funktionen. Dazu gibt es das folgende Demo-Mapping: <Dokumente>\Altova\MapForce2023\MapForceExamples\GroupingFunctions.mfd. Beachten Sie, dass das Demo-Mapping mehrere Transformationen enthält, nämlich eine für jede Funktion. Da immer nur eine Ausgabevorschau auf einmal angezeigt werden kann, klicken Sie auf die Vorschau  Schaltfläche für die gewünschte Transformation, bevor Sie auf das Ausgaberegister klicken.
Schaltfläche für die gewünschte Transformation, bevor Sie auf das Ausgaberegister klicken.
group-by
Mit der Funktion group-by werden anhand eines von Ihnen definierten Gruppierungsschlüssels Datensatzstrukturen erstellt.

So ist etwa in der unten gezeigten abstrakten Transformation der Gruppierungsschlüssel "Department". Da es insgesamt drei eindeutige Abteilungen (Departments) gibt, würden bei Anwendung der Funktion group-by drei Gruppen erstellt:
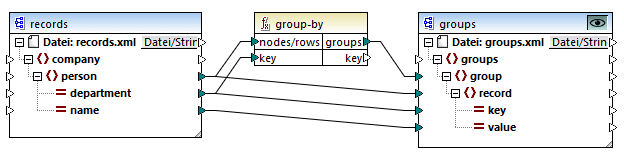
Nähere Informationen dazu finden Sie unter der Funktion group-by.
group-adjacent
Für die Funktion group-adjacent ist, ähnlich wie für die Funktion group-by, als Argument ein Gruppierungsschlüssel erforderlich. Im Gegensatz zur Funktion group-by wird mit dieser Funktion immer dann eine neue Gruppe erstellt, wenn der nächste Schlüssel ein anderer ist. Wenn zwei benachbarte Datensätze denselben Schlüssel haben, werden sie in dieselbe Gruppe eingeordnet.
So ist etwa in der unten gezeigten abstrakten Transformation der Gruppierungsschlüssel "Department". Auf der linken Seite des Diagramms sehen Sie die Input-Daten, während rechts die Ausgabedaten nach der Gruppierung angezeigt werden. Bei Ausführung der Transformation geschieht Folgendes:
•Anfangs wird anhand des ersten Schlüssels "Administration" eine neue Gruppe erstellt.
•Der nächste Schlüssel ist ein anderer, daher wird eine zweite Gruppe "Marketing" erstellt.
•Der dritte Schlüssel ist ebenfalls ein anderer, daher wird eine weitere Gruppe namens "Engineering" erstellt.
•Der vierte Schlüssel ist derselbe wie der dritte, daher wird dieser Datensatz in die bereits vorhandene Gruppe platziert.
•Der fünfte Schlüssel schließlich ist anders als der vierte, weshalb die letzte Gruppe erstellt wird.
Wie unten gezeigt, landen "Michelle Butler" und "Fred Landis" in derselben Gruppe, weil sie denselben Schlüssel aufweisen und nebeneinander liegen. "Vernon Callaby" und "Frank Further" hingegen befinden sich in separaten Gruppen, weil sie nicht benachbart sind, obwohl sie denselben Schlüssel aufweisen.
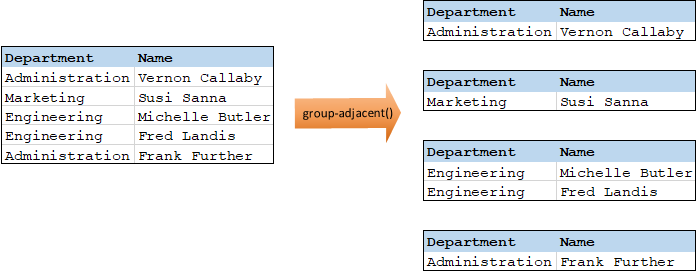
Nähere Informationen dazu finden Sie unter der Funktion group-adjacent.
group-into-blocks
Mit der Funktion group-into-blocks werden gleiche Gruppen erstellt, die genau N Elemente enthalten, wobei N der an das Argument block-size (Blockgröße) gelieferte Wert ist. Beachten Sie, dass die letzte Gruppe, je nach Anzahl der Elemente in der Quellkomponente, N oder weniger Elemente enthalten kann.

Im Beispiel unten ist block-size gleich 2. Da es insgesamt fünf Elemente gibt, enthält jede Gruppe mit Ausnahme der letzten genau zwei Elemente.
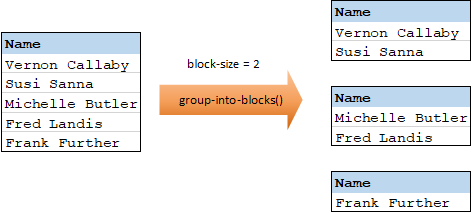
Nähere Informationen dazu finden Sie unter der Funktion group-into-blocks.
group-starting-with
Die Funktion group-starting-with erhält eine Boolsche Bedingung als Argument. Wenn die Boolsche Bedingung "true" ergibt, wird ab dem Datensatz, auf den die Bedingung zutrifft, eine neue Gruppe erstellt.

Im Beispiel unten ist die Bedingung, dass "Key" (Schlüssel) gleich "heading" sein soll. Diese Bedingung triftt auf den ersten und vierten Datensatz zu, daher werden als Ergebnis zwei Gruppen erstellt:
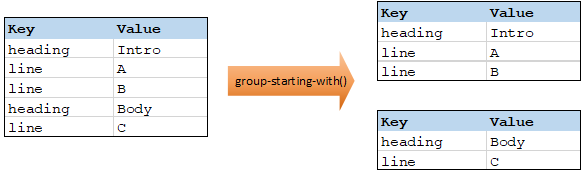
| Anmerkung: | Wenn vor dem ersten Datensatz, auf den die Bedingung zutrifft, weitere Datensätze vorhanden sind, wird eine zusätzliche Gruppe erstellt. Wenn vor dem ersten "heading"-Datensatz z.B. weitere "line"-Datensätze vorhanden waren, würden diese in eine neue Gruppe platziert. |
Nähere Informationen dazu finden Sie unter der Funktion group-starting-with.
group-ending-with
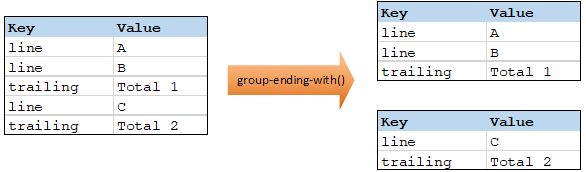
Die Funktion group-ending-with erhält eine Boolsche Bedingung als Argument. Wenn die Boolsche Bedingung "true" ergibt, wird bis inklusive dem Datensatz, auf den die Bedingung zutrifft, eine neue Gruppe erstellt.

Im Beispiel unten ist die Bedingung, dass "Key" (Schlüssel) gleich "trailing" sein soll. Diese Bedingung triftt auf den dritten und fünften Datensatz zu, daher werden als Ergebnis zwei Gruppen erstellt:
| Anmerkung: | Wenn nach dem letzten Datensatz, auf den die Bedingung zutrifft, weitere Datensätze vorhanden sind, wird eine zusätzliche Gruppe erstellt. Wenn z.B. nach dem letzten "trailing"-Datensatz z.B. weitere "line"-Datensätze vorhanden wären, würden diese in eine neue Gruppe platziert. |
Nähere Informationen dazu finden Sie unter der Funktion group-ending-with.