Client Requests
Nachdem RaptorXML+XBRL Server als Dienst gestartet wurde, stehen seine Funktionalitäten jedem HTTP-Client zur Verfügung. Der HTTP-Client kann:
•die HTTP-Methoden GET, PUT, POST und DELETE verwenden
•das Content-Type Header-Feld definieren
Benutzerfreundlicher HTTP-ClientIm Internet steht ein ganze Reihe von Web Clients zum Download zur Verfügung. Wir haben RESTClient von Mozilla, einen benutzerfreundlichen und zuverlässigen Web Client, verwendet. Dieser Client kann als Plug-in zu Firefox hinzugefügt werden, ist einfach zu installieren, unterstützt die von RaptorXML benötigen HTTP-Methoden und bietet eine ausreichend gute JSON-Syntaxfärbung. Wenn Sie bisher noch nicht mit HTTP-Clients gearbeitet haben, empfehlen wir Ihnen RESTClient. Beachten Sie bitte, dass Sie RESTClient auf eigenes Risiko installieren und verwenden. |
Ein typischer Client Request besteht, wie im Diagramm unten gezeigt, aus einer Reihe von Schritten.
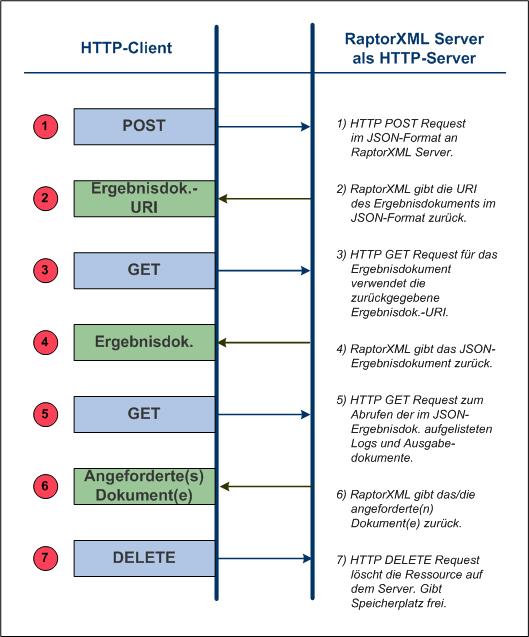
Im Folgenden finden Sie einige wichtige Anmerkungen zu den einzelnen Schritten. Schlüsselbegriffe sind fett gedruckt.
1.Mit Hilfe einer HTTP POST-Methode wird ein Request im JSON-Format erstellt. Der Request könnte für jede Funktionalität von RaptorXML+XBRL Server sein. So könnte z.B. eine Validierung oder eine XSLT-Transformation angefordert werden. Die im Request verwendeten Befehle, Argumente und Optionen sind dieselben, die auch in der Befehlszeile verwendet werden. Der Request wird auf: http://localhost:8087/v1/queue mittels POST bereitgestellt, wobei localhost:8087 hier die Adresse von RaptorXML+XBRL Server (die in der Anfangskonfiguration verwendete Server-Adresse) ist. Ein solcher Request wird als RaptorXML+XBRL Server-Auftrag bezeichnet.
2.Wenn der Request von RaptorXML+XBRL Server erhalten und für die Verarbeitung akzeptiert wurde, wird nach Verarbeitung des Auftrags ein Ergebnisdokument mit den Ergebnissen der Server-Aktion erstellt. Die URI dieses Ergebnisdokuments (im Diagramm oben die Ergebnisdok.-URI) wird an den Client zurückgegeben. Beachten Sie, dass die URI unmittelbar nach Übernahme des Auftrags für die Verarbeitung (nachdem er in die Warteschlange gestellt wurde) und auch, wenn die Verarbeitung noch nicht abgeschlossen wurde, zurückgegeben wird.
3.Der Client sendet (über die Ergebnisdokument-URI) in einer GET-Methode einen Request für das Ergebnisdokument an den Server. Wenn der Auftrag zum Zeitpunkt des Empfangs des Request noch nicht gestartet oder noch nicht abgeschlossen wurde, gibt der Server den Status Running zurück. Der GET Request muss so oft wiederholt werden, bis der Auftrag fertig gestellt ist und das Ergebnisdokument erstellt wurde.
4.RaptorXML+XBRL Server gibt das Ergebnisdokument im JSON-Format zurück. Das Ergebnisdokument kann die URIs von Fehler- oder Ausgabedokumenten, die von RaptorXML+XBRL Server beim Verarbeiten des ursprünglichen Request erzeugt wurden, enthalten. So werden z.B. Fehlerprotokolle zurückgegeben, wenn bei einer Validierung Fehler ausgegeben wurden. Die primären Ausgabedokumente, wie z.B. das Ergebnis einer XSLT-Transformation werden zurückgegeben, wenn der Auftrag zur Erzeugung einer Ausgabe erfolgreich ausgeführt wurde.
5.Der Client sendet die URIs der in Schritt 4 erhaltenen Ausgabedokumente über eine HTTP GET-Methode an den Server. Jeder Request wird in einer separaten GET-Methode gesendet.
6.RaptorXML+XBRL Server gibt die angeforderten Dokumente in Antwort auf die in Schritt 5 gesendeten GET-Requests zurück.
7.Der Client kann nicht benötigte Dokumente, die als Ergebnis eines Auftrags-Request auf dem Server generiert wurden, löschen. Zu diesem Zweck sendet er die URI des entsprechenden Ergebnisdokuments in einer HTTP DELETE-Methode. Daraufhin werden alle im Zusammenhang mit diesem Auftrag generierten Dateien von der Festplatte gelöscht. Dazu gehören das Ergebnisdokument, alle temporären Dateien sowie alle Fehler- und Ausgabedokumentdateien. Dadurch schaffen Sie Platz auf der Festplatte des Servers.
In den Unterabschnitten dieses Abschnitts werden die einzelnen Schritte näher beschrieben.