Vorbereiten von Dateien für die Server-Ausführung
Ein Mit MapForce erstelltes Mapping, das auch in der MapForce-Vorschau angezeigt wird, kann Ressourcen (z.B. Datenbanken) referenzieren, die sich nicht auf dem aktuellen Rechner und Betriebssystem befinden. Außerdem entsprechen in MapForce alle Mapping-Pfade standardmäßig den Windows-Konventionen. Zudem unterstützt der Rechner, auf dem MapForce Server läuft, nicht notwendigerweise dieselben Datenbankverbindungen wie der Rechner, auf dem das Mapping erstellt wurde. Aus diesem Grund, müssen Sie ein Mapping entsprechend vorbereiten, bevor Sie es in einer Server-Umgebung ausführen, vor allem dann, wenn der Zielrechner nicht derselbe wie der Quellrechner ist.
| Anmerkung: | Mit "Quellrechner" wird der Computer bezeichnet, auf dem MapForce installiert ist und mit "Zielrechner" wird der Computer bezeichnet, auf dem MapForce Server oder FlowForce Server installiert ist. Im einfachsten Szenario handelt es sich hierbei um denselben Computer. In einem komplexeren Szenario läuft MapForce auf einem Windows-Rechner, während MapForce Server auf einem Linux- oder macOS-Rechner ausgeführt wird. |
Stellen Sie am besten immer sicher, dass sich das Mapping in MapForce erfolgreich validieren lässt, bevor Sie es auf FlowForce Server bereitstellen oder zu einer MapForce Server-Ausführungsdatei kompilieren.
Wenn MapForce Server alleine (ohne FlowForce Server) ausgeführt wird, werden die folgenden Lizenzen benötigt:
•Auf dem Quellrechner benötigen Sie zur Erstellung des Mappings und zum Kompilieren zu einer Server-Ausführungsdatei (.mfx) die MapForce Enterprise oder Professional Edition.
•Auf dem Zielrechner benötigen Sie zur Ausführung des Mappings MapForce Server oder MapForce Server Advanced Edition.
Wenn MapForce Server unter Verwaltung von FlowForce Server ausgeführt wird, gelten die folgenden Voraussetzungen:
•Auf dem Quellrechner benötigen Sie zur Erstellung des Mappings und für die Bereitstellung des Mappings auf einem Zielrechner die MapForce Enterprise oder Professional Edition.
•Sowohl MapForce Server als auch FlowForce Server müssen auf dem Zielrechner lizenziert sein. Die Aufgabe von MapForce Server ist die Ausführung des Mappings; die Aufgabe von FlowForce ist es, das Mapping in Form eines Auftrags bereitzustellen, wodurch Funktionen wie Ausführung nach einem Zeitplan oder auf Wunsch, die Ausführung als Webservice, Fehlerbehandlung, Ausführung auf Basis von Bedingungen, E-Mail-Benachrichtigungen usw. zur Verfügung stehen.
•FlowForce Server muss an der konfigurierten Netzwerkadresse und am konfigurierten Port gestartet sein. Dabei muss der "FlowForce Web Server"-Dienst gestartet sein und so konfiguriert sein, dass er Verbindungen von HTTP-Clients (oder bei Bedarf von HTTPS-Clients) zulässt und er darf nicht durch die Firewall blockiert werden. Auch der "FlowForce Server"-Dienst muss unter der vorgesehenen Adresse und am angegebenen Port gestartet und verfügbar sein.
•Sie haben ein FlowForce Server-Benutzerkonto und Zugriff auf einen der Container (standardmäßig steht der Container /public jedem authentifizierten Benutzer zur Verfügung).
Allgemeine Überlegungen
•Wenn Sie beabsichtigen, das Mapping mit MapForce Server alleine auf einem Zielrechner auszuführen, müssen alle vom Mapping referenzierten Input-Dateien ebenfalls auf den Zielrechner kopiert werden. Wenn MapForce Server unter Verwaltung von FlowForce Server ausgeführt wird, müssen die Dateien nicht manuell kopiert werden. In diesem Fall sind die Instanz- und Schema-Dateien in dem auf dem Zielrechner bereitgestellten Paket inkludiert.
•Wenn das Mapping Datenbankkomponenten enthält, für die spezielle Datenbanktreiber benötigt werden, müssen diese Treiber auch auf dem Zielrechner installiert werden. Wenn in Ihrem Mapping z.B. Daten aus einer Microsoft Access-Datenbank ausgelesen werden, so muss Microsoft Access oder Microsoft Access Runtime (https://www.microsoft.com/en-us/download/details.aspx?id=50040) auch auf dem Zielrechner installiert sein.
•Wenn Sie ein Mapping auf Nicht-Windows-Plattformen bereitstellen, werden ADO-, ADO.NET- und ODBC-Datenbankverbindungen automatisch in JDBC konvertiert. Native SQLite- und PostgreSQL-Verbindungen werden als solche beibehalten und müssen nicht zusätzlich konfiguriert werden. Siehe auch "Datenbankverbindungen" weiter unten.
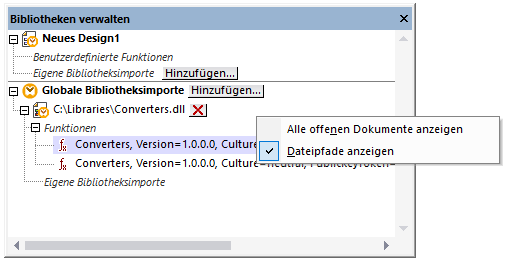
•Wenn das Mapping benutzerdefinierte Funktionsaufrufe enthält (z.B. Aufrufe von .dll- oder .class-Dateien), werden diese Abhängigkeiten nicht zusammen mit dem Mapping bereitgestellt, da sie vor der Laufzeit nicht bekannt sind. Kopieren Sie diese in diesem Fall manuell auf den Zielrechner. Der Pfad der .dll- oder .class-Datei auf dem Server muss derselbe sein, der in MapForce im Dialogfeld "Bibliotheken verwalten" definiert wurde, z.B.:
•In einigen Mappings werden mehrere Input-Dateien über einen Platzhalter-Pfad ausgelesen . In diesem Fall sind die Namen der Input-Dateien vor der Laufzeit noch nicht bekannt und können daher nicht bereitgestellt werden. Damit das Mapping erfolgreich ausgeführt werden kann, muss die Input-Datei auf dem Zielrechner vorhanden sein.
•Wenn der Mapping-Ausgabepfad Verzeichnisse enthält, müssen diese auf dem Zielrechner vorhanden sein, da sonst bei Ausführung des Mappings ein Fehler generiert wird. Im Gegensatz dazu werden in MapForce nicht vorhandene Verzeichnisse automatisch generiert, wenn die Option Output-Datei als temporäre Datei generieren aktiviert ist.
•Wenn im Mapping ein Webservice aufgerufen wird, für den eine HTTPS-Authentifizierung mit einem Client-Zertifikat erforderlich ist, muss das Zertifikat ebenfalls an den Zielrechner übertragen werden (siehe .
•Wenn im Mapping eine Verbindung zu dateibasierten Datenbanken wie Microsoft Access und SQLite hergestellt wird, muss die Datenbank manuell auf den Zielrechner transferiert werden oder in einem freigegebenen, sowohl Quell- als auch Zielrechner zugänglichen Verzeichnis gespeichert werden und von dort aus referenziert werden, siehe "Dateibasierte Datenbanken", weiter unten.
Übertragbarmachen von Pfaden
Wenn Sie beabsichtigen, das Mapping auf einem Server auszuführen, müssen Sie sicherstellen, dass es den jeweils geltenden Pfadkonventionen entspricht und dass eine unterstützte Datenbankverbindung verwendet wird.
Um Pfade auf Nicht-Windows-Betriebssysteme übertragen zu können, verwenden Sie beim Erstellen des Mappings in MapForce relative anstelle von absoluten Pfaden:
1.Öffnen Sie die gewünschte Mapping-Design-Datei (.mfd) mit MapForce unter Windows.
2.Wählen Sie im Menü Datei den Befehl Mapping-Einstellungen und deaktivieren Sie das Kontrollkästchen Pfade im generierten Code absolut machen, falls es aktiviert ist.
3.Öffnen Sie für jede Mapping-Komponente das Dialogfeld Eigenschaften (z.B. durch Doppelklick auf die Titelleiste) und ändern Sie alle Dateipfade von absoluten in relative um. Aktivieren Sie außerdem das Kontrollkästchen Alle Dateipfade relativ zur MFD-Datei speichern. Sie können alle Input-Dateien und Schemas aus praktischen Gründen in denselben Ordner wie das Mapping kopieren und diese einfach über den Dateinamen referenzieren.
Nähere Informationen zum Arbeiten mit relativen und absoluten Pfaden bei der Erstellung eines Mappings finden Sie in der Dokumentation zu MapForce,.
Beachten Sie, dass sowohl MapForce Server als auch FlowForce Server ein so genanntes Arbeitsverzeichnis ("working directory") unterstützen, anhand dessen alle relativen Pfade aufgelöst werden. Das Arbeitsverzeichnis wird zur Mapping-Laufzeit folgendermaßen definiert:
•in FlowForce Server durch Bearbeitung des Auftragsparameters "Working-directory".
•in der MapForce Server API über die Eigenschaft WorkingDirectory der COM und der .NET API oder über die Methode setWorkingDirectory der Java API.
•in der MapForce Server-Befehlszeile ist das Arbeitsverzeichnis das aktuelle Verzeichnis der Befehlszeile.
Datenbankverbindungen
Beachten Sie, dass ADO-, ADO.NET- und ODBC-Verbindungen auf Linux- und macOS-Rechnern nicht unterstützt werden. Wenn es sich beim Zielrechner daher um einen Linux- oder macOS-Rechner handelt, werden diese Verbindungen in JDBC konvertiert, wenn Sie das Mapping auf FlowForce Server bereitstellen oder das Mapping zu einer MapForce Server-Ausführungsdatei kompilieren. In diesem Fall haben Sie die folgenden Möglichkeiten, bevor Sie das Mapping bereitstellen oder es zu einer Server-Ausführungsdatei kompilieren:
•Erstellen Sie in MapForce eine JDBC-Verbindung zur Datenbank, bevor Sie das Mapping bereitstellen
•Füllen Sie in MapForce die JDBC-Datenbankverbindungsinformationen im Abschnitt "JDBC-spezifische Einstellungen" der Datenbankkomponente aus .
Wenn im Mapping eine native Verbindung zu einer PostgreSQL- oder SQLite-Datenbank verwendet wird, wird die native Verbindung beibehalten und es wird keine JDBC-Konvertierung durchgeführt. Wenn im Mapping eine Verbindung zu einer dateibasierten Datenbank wie Microsoft Access und SQLite hergestellt wird, müssen zusätzliche Konfigurationsschritte durchgeführt werden, siehe "Dateibasierte Datenbanken" weiter unten.
Für die Ausführung von Mappings mit JDBC-Verbindungen muss Java Runtime Environment oder Java Development Kit auf dem Server-Rechner installiert sein. Dabei kann es sich entweder um Oracle JDK oder einen Open Source Build wie z.B. Oracle OpenJDK handeln.
•Die JAVA_HOME-Umgebungsvariable muss auf das JDK-Installationsverzeichnis verweisen. •Unter Windows hat ein Java Virtual Machine-Pfad aus der Windows Registry Vorrang vor der JAVA_HOME-Variablen. •Die JDK-Plattform (64-Bit, 32-Bit) muss mit der von MapForce Server identisch sein, da Sie sonst eventuell einen Fehler erhalten, weil "kein Zugriff auf JVM besteht". |
So richten Sie unter Linux oder macOS eine JDBC-Verbindung ein:
1.Laden Sie den vom Datenbankanbieter bereitgestellten JDBC-Treiber herunter und installieren Sie ihn auf dem Betriebssystem. Wählen Sie die 32-Bit-Version aus, wenn Ihr Betriebssystem mit 32 Bit ausgeführt wird, und die 64-Bit-Version, wenn Ihr Betriebssystem mit 64 Bit ausgeführt wird.
2.Definieren Sie für die Umgebungsvariablen den Pfad, unter dem der JDBC-Treiber installiert ist. Normalerweise müssen Sie die CLASSPATH-Variable und eventuell noch einige weitere Variablen definieren. Nähere Informationen dazu, welche Umgebungsvariablen konfiguriert werden müssen, finden Sie in der mit dem JDBC-Treiber mitgelieferten Dokumentation.
| Anmerkung: | Unter macOS werden die installierten JDBC-Bibliotheken im Verzeichnis /Library/Java/Extensions gesucht. Es wird daher empfohlen, den JDBC-Treiber unter diesem Pfad zu entpacken; andernfalls müssen Sie das System so konfigurieren, dass es die JDBC-Bibliothek unter dem Pfad sucht, unter dem Sie den JDBC-Treiber installiert haben. |
Oracle Instant Client-Verbindungen auf macOS
Wenn Sie über den Oracle Database Instant Client eine Verbindung zu einer Oracle-Datenbank herstellen, gelten auf macOS die folgenden Voraussetzungen: Voraussetzungen:
•Es muss Java 8.0 oder höher installiert sein. Sie können auch über die JDBC Thin for All Platforms-Bibliothek eine Verbindung herstellen, wenn auf dem Mac-Rechner eine Java-Version älter als Version 8 läuft. In diesem Fall können Sie die unten stehende Anleitung ignorieren.
•Oracle Instant Client muss installiert sein. Sie können den Oracle Instant Client von der offiziellen Oracle Download-Seite herunterladen. Beachten Sie, dass auf dieser Seite mehrere Instant Client-Pakete zum Download zur Verfügung stehen. Stellen Sie sicher, dass Sie ein Paket mit Oracle Call Interface (OCI)-Unterstützung (z.B. Instant Client Basic) auswählen. Stellen Sie außerdem sicher, dass Sie die 32-Bit-Version auswählen, falls Ihr Betriebssystem auf 32 Bit läuft, und die 64-Bit-Version, falls Ihr Betriebssystem auf 64 Bit läuft.
Nachdem Sie den Oracle Instant Client heruntergeladen und entpackt haben, bearbeiten Sie die mit dem Installer mitgelieferte Eigenschaftsliste (plist-Datei), sodass die folgenden Umgebungsvariablen auf den entsprechenden Treiberpfad verweisen, z.B.:
Variable | Beispielwert |
CLASSPATH | /opt/oracle/instantclient_11_2/ojdbc6.jar:/opt/oracle/instantclient_11_2/ojdbc5.jar |
TNS_ADMIN | /opt/oracle/NETWORK_ADMIN |
ORACLE_HOME | /opt/oracle/instantclient_11_2 |
DYLD_LIBRARY_PATH | /opt/oracle/instantclient_11_2 |
PATH | $PATH:/opt/oracle/instantclient_11_2 |
| Anmerkung: | Bearbeiten Sie die obigen Beispielwerte, sodass sie auf die Pfade verweisen, unter denen die Oracle Instant Client-Dateien auf Ihrem Betriebssystem installiert sind. |
Dateibasierte Datenbanken
Dateibasierte Datenbanken wie Microsoft Access und SQLite sind in dem auf FlowForce Server bereitgestellten Paket oder in der kompilierten MapForce Server-Ausführungsdatei nicht enthalten. Wenn der Quellrechner daher nicht derselbe wie der Zielrechner ist, gehen Sie folgendermaßen vor:
1.Klicken Sie in MapForce mit der rechten Maustaste auf das Mapping und deaktivieren Sie das Kontrollkästchen Pfade im generierten Code absolut machen .
2.Klicken Sie mit der rechten Maustaste im Mapping auf die Datenbankkomponente und fügen Sie eine Verbindung zu einer Datenbankdatei über einen relativen Pfad hinzu. Eine einfache Methode, um Pfadprobleme zu vermeiden, ist, das Mapping-Design (die .mfd-Datei) im selben Verzeichnis wie die Datenbankdatei zu speichern und letztere vom Mapping aus nur über den Dateinamen (d.h. über einen relativen Pfad) zu referenzieren.
3.Kopieren Sie die Datenbankdatei in ein Verzeichnis auf dem Zielrechner (nennen wir es das "Arbeitsverzeichnis"). Dieses Verzeichnis benötigen Sie später, um das Mapping auf dem Server auszuführen (siehe unten).
Um ein solches Mapping auf dem Server auszuführen, wählen Sie eine der folgenden Methoden:
•Wenn das Mapping unter Verwaltung von FlowForce Server mit MapForce Server ausgeführt wird, konfigurieren Sie den FlowForce Server-Auftrag so, dass das zuvor erstellte Arbeitsverzeichnis verwendet wird. Die Datenbankdatei muss sich in diesem Arbeitsverzeichnis befinden. Ein Beispiel dazu finden Sie unter Bereitstellen eines Auftrags als Web-Dienst.
•Wenn das Mapping von MapForce Server alleine über die Befehlszeile ausgeführt wird, ändern Sie das aktuelle Verzeichnis in das Arbeitsverzeichnis (z.B. cd pfad\zum\arbeitsverzeichnis), bevor Sie den MapForce Server-Befehl run aufrufen.
•Wenn das Mapping über die MapForce Server API ausgeführt wird, definieren Sie das Arbeitsverzeichnis programmatisch, bevor Sie das Mapping ausführen. Zu diesem Zweck steht für das MapForce Server-Objekt in der COM und .NET API die Eigenschaft WorkingDirectory zur Verfügung. In der Java API steht dafür die Methode setWorkingDirectory zur Verfügung.
Wenn es sich sowohl beim Quell- als auch beim Zielrechner um Windows-Rechner im lokalen Netzwerk handelt, wäre eine alternative Methode, das Mapping so zu konfigurieren, dass die Datenbankdatei folgendermaßen aus einem gemeinsamen, freigegebenen Verzeichnis gelesen wird:
1.Speichern Sie die Datenbankdatei in einem gemeinsamen freigegebenen Verzeichnis, auf das sowohl der Quell- als auch der Zielrechner Zugriff hat.
2.Klicken Sie mit der rechten Maustaste im Mapping auf die Datenbankkomponente und fügen Sie über einen absoluten Pfad eine Verbindung zur Datenbankdatei hinzu.
Globale Ressourcen
Wenn ein Mapping anstelle von direkten Pfaden oder Datenbankverbindungen Referenzen auf globale Ressourcen enthält, können Sie auch serverseitig globale Ressourcen verwenden. Wenn Sie ein Mapping zu einer MapForce Server-Ausführungsdatei (.mfx) kompilieren, bleiben die Referenzen auf globale Ressourcen intakt, so dass Sie diese zur Mapping-Laufzeit auf Seite des Servers bereitstellen können. Wenn Sie ein Mapping auf FlowForce Server bereitstellen, können Sie optional auswählen, ob darin die Ressourcen auf dem Server verwendet werden sollen.
Damit Mappings (oder, im Fall von FlowForce Server, Mapping-Funktionen) erfolgreich ausgeführt werden können, muss die eigentliche Datei, der eigentliche Ordner bzw. die Datenbankverbindungsinformationen, die Sie als globale Ressourcen bereitstellen mit der Server-Umgebung kompatibel sein. So muss z.B. bei Ausführung des Mappings auf einem Linux-Server bei Datei- und Ordnerpfaden die Linux-Pfadkonvention verwendet werden. Ebenso müssen als Datenbankverbindungen definierte globale Ressourcen auf dem Server-Rechner möglich sein.
Nähere Informationen dazu finden Sie unter Ressourcen.
XBRL-Taxonomiepakete
Wenn Sie ein Mapping bereitstellen, in dem XBRL-Taxonomiepakete referenziert werden, sammelt MapForce alle externen Referenzen aus dem Mapping und löst diese dann unter Verwendung der aktuellen Konfiguration und der aktuell installierten Taxonomiepakete auf. Falls es aufgelöste externe Referenzen gibt, die auf ein Taxonomiepaket verweisen, so wird das Taxonomiepaket zusammen mit dem Mapping bereitgestellt. FlowForce Server verwendet dieses Paket in dem Zustand, in dem es sich bei der Bereitstellung befand, um das Mapping auszuführen. Um das von FlowForce Server verwendete Taxonomiepaket zu aktualisieren, müssen Sie es in MapForce ändern und das Mapping erneut bereitstellen.
Beachten Sie, dass der Root-Katalog von MapForce Server einen Einfluss darauf hat, wie Taxonomien auf dem Zielrechner aufgelöst werden. Der Root-Katalog befindet sich unter dem folgenden Pfad relativ zum MapForce Server-Installationsverzeichnis: etc/RootCatalog.xml.
Mit einem Mapping bereitgestellte Taxonomiepakete werden verwendet, wenn der Root-Katalog von MapForce Server nicht bereits ein solches Paket enthält oder kein Paket enthält, das für dasselbe URL-Präfix definiert ist. Der Root-Katalog von MapForce Server hat Vorrang vor einer bereitgestellten Taxonomie.
Wenn MapForce Server alleine (ohne FlowForce Server) ausgeführt wird, kann der für das Mapping zu verwendende Root-Katalog folgendermaßen definiert werden:
•in der Befehlszeile durch Hinzufügen der Option -catalog zum Befehl run.
•in der MapForce Server API durch Aufruf der Methode SetOption und Bereitstellen des String "catalog" als erstes Argument und des Pfads zum Root-Katalog als zweites Argument.
Wenn in einem Mapping XBRL-Komponenten mit Tabellen-Linkbases verwendet werden, muss das Taxonomiepaket oder die Taxonomiepaketkonfigurationsdatei dem Mapping folgendermaßen zur Laufzeit zur Verfügung gestellt werden:
•Fügen Sie in der MapForce Server-Befehlszeile die Option --taxonomy-package oder --taxonomy-packages-config-file zum Befehl run hinzu.
•Rufen Sie über die MapForce Server API die Methode SetOption auf. Das erste Argument muss entweder "taxonomy-package" oder "taxonomy-packages-config-file" sein. Das zweite Argument muss der eigentliche Pfad zum Taxonomiepaket (oder zur Taxonomiepaketkonfigurationsdatei) sein.