Beispiel: Gruppieren und Filtern von Nodes nach Namen
In diesem Beispiel wird gezeigt, wie Sie ein Mapping erstellen, das Schlüssel-Wert-Paare aus einer Liste von XML-Eigenschaften (oder XML plist) ausliest und diese in eine CSV-Datei schreibt. (Die XML-Eigenschaftsliste stellte eine Methode zum Speichern von macOS- und iOS-Objektinformationen im XML-Format dar, siehe https://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/PropertyLists/UnderstandXMLPlist/UnderstandXMLPlist.html.) Die Mapping-Beispieldatei hierzu finden Sie unter dem folgenden Pfad: <Dokumente>\Altova\MapForce2025\MapForceExamples\ReadPropertyList.mfd.
Das unten gezeigte Codefragment bildet die XML-Quelldatei.
<?xml version="1.0" encoding="UTF-8"?> |
Ziel des Mappings ist es, anhand bestimmter Schlüssel-Wert-Paare aus dem Node <dict> (in der Eigenschaftslistendatei) eine neue Zeile in der CSV-Datei zu erstellen. Dabei soll das Mapping nur <key> - <string>-Paare filtern. Andere Schlüssel-Wert-Paare (wie z.B. <key> - <integer>) sollen ignoriert werden. In der CSV-Datei soll der Name der Eigenschaft, der durch ein Komma vom Wert der Eigenschaft getrennt ist, in einer Zeile gespeichert werden. Die Ausgabe sollte also folgendermaßen aussehen:
First Name,William Last Name,Shakespeare Profession,Playwright |
Zu diesem Zweck wird ein dynamischer Zugriff auf alle Child-Nodes des Node dict im Mapping verwendet. Des Weiteren wird die Funktion group-starting-with verwendet, um die aus der XML-Datei abgerufenen Schlüssel-Wert-Paare zu gruppieren. Schließlich wird ein Filter verwendet, um nur die Nodes zu filtern, deren Node-Name "string" ist.
In den folgenden Schritten wird gezeigt, wie das Mapping erstellt wird.
Schritt 1: Hinzufügen der XML-Quellkomponente zum Mapping
1.Setzen Sie die Mapping-Transformationssprache auf BUILT-IN.
2.Klicken Sie im Menü Einfügen auf XML-Schema/Datei und navigieren Sie zur folgenden Datei: <Dokumente>\Altova\MapForce2025\MapForceExamples\plist.xml. Diese XML-Datei verweist auf das Schema plist.dtd im selben Ordner.
Schritt 2: Hinzufügen der CSV-Zielkomponente zum Mapping
1.Klicken Sie im Menü Einfügen auf Textdatei. Wenn Sie dazu aufgefordert werden, wählen Sie die Option Einfache Verarbeitung für Standard-CSV verwenden... .
2.Fügen Sie ein CSV-Feld zur Komponente hinzu, indem Sie auf Feld anhängen klicken.
3.Doppelklicken Sie auf die Namen der einzelnen Felder und geben Sie als Namen des ersten Felds "Schüssel" und als Namen des zweiten Felds "Wert" ein. Im Feld "Schlüssel" wird der Name der Eigenschaft und im Feld "Wert" der Wert der Eigenschaft gespeichert. Nähere Informationen zu CSV-Komponenten finden Sie unter CSV- und Textdateien.
Schritt 3: Hinzufügen des Filters und der Funktionen
1.Ziehen Sie die Funktionen equal, exists und group-starting-with aus dem Fenster "Bibliotheken" in das Mapping. Nähere Informationen zu Funktionen finden Sie unter Funktionen.
2.Um den Filter hinzuzufügen, klicken Sie auf das Menü Einfügen und anschließend auf Filter: Nodes/Zeilen. Allgemeine Informationen zu Filtern finden Sie unter Filter und Bedingungen.
3.Klicken Sie im Menü Einfügen auf Konstante und geben Sie anschließend den Text "string" ein.
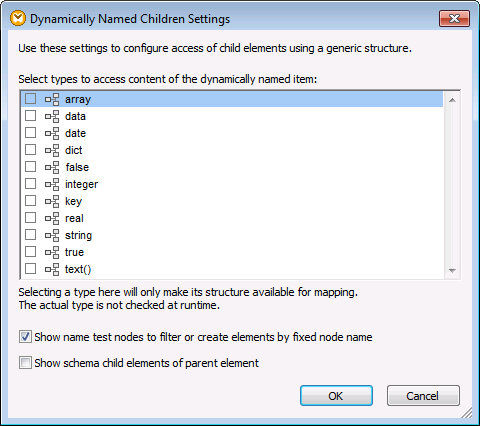
4.Klicken sie mit der rechten Maustaste in der Quellkomponente auf den Node dict und wählen Sie im Kontextmenü den Befehl Child-Elemente mit dynamischem Namen anzeigen. Stellen Sie sicher, dass im Dialogfeld "Einstellungen für dynamisch benannte Child-Elemente" das Kontrollkästchen Name-Test-Nodes zum Filtern oder Erstellen von Elementen nach festgelegtem Node-Namen anzeigen aktivert ist.
5.Ziehen Sie die Verbindungen wie unten gezeigt.
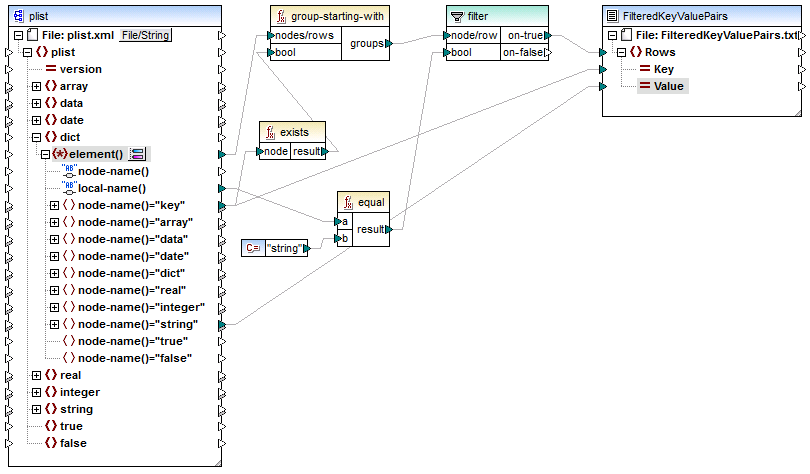
ReadPropertyList.mfd
Erläuterung zum Mapping
Das Datenelement element() der Quellkomponente liefert alle Children des Node dict als Sequenz an die Funktion group-starting-with. Die Funktion group-starting-with erstellt jedes Mal, wenn sie auf einen Node mit dem Namen key stößt, eine neue Gruppe. Die Funktion exists überprüft diese Bedingung und gibt das Ergebnis als Booleschen true/false-Wert an die Gruppierungsfunktion zurück.
Der Filter überprüft mit Hilfe der Funktion equal für jede Gruppe, ob der Name des aktuellen Node gleich "string" ist. Der Name selbst wird aus dem Node local-name(), der den Namen des Node als String bereitstellt, gelesen.
Die Verbindungen zur Zielkomponente haben die folgende Aufgabe:
•Nur wenn die Filterbedingung "true" ist, wird in der CSV-Zieldatei eine neue Zeile erstellt.
•Key (Eigenschaftsname) stammt aus dem Wert des key-Elements in der Quelldatei.
•Value (Eigenschaftswert) stammt aus dem Namensüberprüfungs-Node string.