Diagrammdatenauswahl: Flexibel
Im Dialogfeld Diagrammkonfiguration im Bereich "Diagrammdatenauswahl" (Abbildung unten) können Sie mit der Option "Flexibel" die Daten für die Datenreihenachse (Z-Achse), die X-Achse und die Y-Achse frei mit Hilfe eines XPath-Ausdrucks auswählen. Der XPath-Ausdruck für eine Achse gibt die Sequenz an Einträgen zurück, die auf dieser Achse abgebildet werden sollen. Diese Sequenzen für die Achsen werden anschließend miteinander vereinigt, um das Diagramm zu generieren.

Beachten Sie die folgenden Punkte:
•Als Datenreihe wird eine Reihe von Werten bezeichnet, die für eine Gruppe von Skalenstrichen auf der X-Achse (Kategorieachse) abgebildet wird. Mit einer zweiten Datenreihe würde eine zweite Gruppe von Werten auf denselben X-Achsen-Skalenstrichen dargestellt. Wenn z.B. auf der X-Achse die Jahre 2008, 2009 und 2010 und auf der Y-Achse die Umsätze dargestellt würden, dann könnte die Datenreihe 1 für Amerika stehen (Umsätze in Amerika für diese drei Jahre), während die Datenreihe 2 für Europa stehen könnte (Umsätze in Europa für diese drei Jahre). Wenn diese Daten in einem Balkendiagramm dargestellt würden, gäbe es für jedes Jahr (2008, 2009, 2010) auf der X-Achse zwei Balken (Amerika und Europa), einen für jede Datenreihe. Bei Kreis- und Einzelwert-Balkendiagrammen kann nur eine Datenreihe dargestellt werden. Nähere Informationen zu den einzelnen Diagrammtypen finden Sie in der Diagrammtyptabelle.
•Jede Zeile im Bereich "Diagrammdatenauswahl" repräsentiert eine Datenreihe.
•Der XPath-Ausdruck in der For-Each-Spalte liefert den Kontext für die Auswertung jedes der drei anderen XPath-Ausdrücke. Der For-Each XPath-Ausdruck selbst wird im Kontext des Node im Design ausgewertet, in den er eingefügt wurde.
Anhand des folgenden Beispiels werden die wichtigsten Punkte erläutert, die bei Auswahl der Daten für die Achsen berücksichtigt werden müssen. Wir verwenden für das Beispiel das unten gezeigte XML-Dokument.

<?xml version="1.0" encoding="UTF-8"?>
<Data xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="YearlySales.xsd">
<ChartType>Pie Chart 2D</ChartType>
<Region id="Americas">
<Year id="2005">30000</Year>
<Year id="2006">90000</Year>
<Year id="2007">120000</Year>
<Year id="2008">180000</Year>
<Year id="2009">140000</Year>
<Year id="2010">100000</Year>
</Region>
<Region id="Europe">
<Year id="2005">50000</Year>
<Year id="2006">60000</Year>
<Year id="2007">80000</Year>
<Year id="2008">100000</Year>
<Year id="2009">95000</Year>
<Year id="2010">80000</Year>
</Region>
<Region id="Asia">
<Year id="2005">10000</Year>
<Year id="2006">25000</Year>
<Year id="2007">70000</Year>
<Year id="2008">110000</Year>
<Year id="2009">125000</Year>
<Year id="2010">150000</Year>
</Region>
</Data>
Eine Zeile, eine Datenreihe
Angenommen, wir wollen ein 2-D-Balkendiagramm für jedes Region Element generieren (Es gibt drei dieser Elemente: für Amerika, Europa und Asien). Wir wollen das Diagramm im Design innerhalb des Region Element-Nodes erstellen. Als Kontext-Node für die For-Each-XPath-Ausdrücke in der Diagrammdatenauswahl wird also das Element Region verwendet.
In der in der Abbildung oben gezeigten Diagrammdatenauswahl gibt der For-Each-Ausdruck den aktuellen Node zurück (also das Element Region), daher bildet das Element Region den Kontext-Node für alle drei anderen XPath-Ausdrücke (Datenreihe, X-Achse und Y-Achse). Da es nur eine Datenreihe in diesem Diagramm gibt, wird kein Datenreihenname benötigt und wir lassen diese Spalte leer. Die Auswahl für die X-Achse gibt sechs Werte zurück. Auf der X-Achse werden daher sechs Skalenstriche dargestellt und die sechs Einträge der Sequenz werden als die entsprechenden Beschriftungen für diese Skalenstriche verwendet. Die Auswahl für die Y-Achse gibt ebenfalls sechs Einträge zurück, von denen jeder für den entsprechenden X-Achsen-Skalenstrich auf der Y-Achse abgebildet wird. Da das Diagramm innerhalb des Elements Region erstellt wurde, iteriert der XSLT-Prozessor durch die drei Region Elemente, um drei Diagramme zu erzeugen, für jedes Region Element eines. Für jedes Diagramm werden die untergeordneten Nodes des jeweiligen Region Elements verwendet.
Das Diagramm für die Region Americas würde in der Ausgabe in etwa folgendermaßen aussehen:

Drei Zeilen, drei Datenreihen, Kategoriewerte nicht zusammengeführt
Um mehrere Datenreihen zu erstellen, können zusätzliche Zeilen zur Diagrammdatenauswahl hinzugefügt werden, wie in der Abbildung unten gezeigt.

Beachten Sie bei der obigen Datenauswahl die folgenden wichtigen Punkte:
•Jede Zeile definiert eine Datenreihe und alle Zeilen haben das Element Data als Kontext-Node (da sich das Diagramm innerhalb eines Data Node befindet).
•Die erste Zeile wurde als die Datenreihe "Americas" definiert. Sie erhält einen String-Ausdruck als Namen der Datenreihe. Als Werte für die X-Achse werden die Year/@id Werte der Region "Europe" ausgewählt (Es macht keinen Unterschied, welche Region ausgewählt wird, da alle Regionen, dieselben Year/@id Werte haben). Mittels eines Prädikatfilters werden die Y-Achsenwerte der ersten Datenreihe (Americas) für die Region "Americas"ausgewählt.
•Bei der zweiten und dritten Datenreihe wird nach derselben Methode wie bei der erste Datenreihe vorgegangen. Beachten Sie allerdings, dass die Auswahl für die X-Achse bei jeder Datenreihe identisch ist. Da aber das Kontrollkästchen Kategoriewerte zusammenführen nicht aktiv ist, werden der zweite und der dritte Ausdruck ignoriert. (Selbst wenn die Werte zusammengeführt würden, würde dies keinen Unterschied machen, da die Werte der einzelnen Datenreihen identisch sind; nur neue unterschiedliche Werte würden zu den Kategoriewerten hinzugefügt.)
Das mit den oben ausgewählten Daten generierte Diagramm würde in etwa folgendermaßen aussehen:

Drei Zeilen, drei Datenreihen, Kategoriewerte zusammengeführt
Die Datenauswahl in diesem Beispiel (siehe Abbildung unten) unterschiedet sich in dreierlei Hinsicht vom vorherigen Beispiel: (i) die Datenauswahl für die X-Achse weist für die dritte Datenreihe einen zusätzlichen Eintrag (2011) auf, (ii) das Kontrollkästchen Kategoriewerte zusammenführen wurde aktiviert und (iii) das Intervall für die Skalenstriche der Y-Achse wurde manuell auf 20000 gesetzt.

Als Resultat dieser Änderung wurde zur Ergebnissequenz für die X-Achse ein zusätzlicher neuer Eintrag (2011) hinzugefügt. Das Diagramm würde in etwa folgendermaßen aussehen:

Eine Zeile, drei Datenreihen
Das Diagramm in diesem Beispiel wird im Data-Node (siehe XML-Dokument weiter oben) erstellt. Für die Datenauswahl wird nur eine Zeile verwendet, es werden aber drei Datenreihen generiert. Dies liegt daran, dass der XPath-Ausdruck in der For-Each-Spalte eine Sequenz von drei Einträgen zurückgibt, wodurch diese drei Datenreihen implizit erstellt werden.
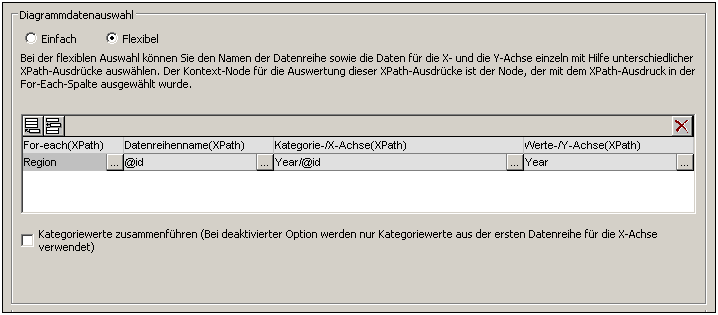
Der Datenreihenname, die Auswahl für die X- und die Y-Achse entsprechen für jede Datenreihe den unterschiedlichen Regionen, da jede Datenreihe ein anderes Region Element als Kontext-Node hat. Das Diagramm für diese Datenauswahl würde in etwa folgendermaßen aussehen:
Regeln für die Diagrammdatenauswahl
Beachten Sie bei Verwendung der Diagrammdatenauswahl zur Auswahl der Daten für die verschiedenen Diagrammachsen bitte Folgendes:
1.Die Anzahl der Balken (bzw. der Kreisdiagrammsegmente, usw.) entspricht der Anzahl der Einträge in der größeren der X- bzw. Y-Achsen-Sequenz einer einzelnen Datenzeilenauswahl. Wenn also die X-Achse (die die Beschriftungen enthält) fünf Einträge und die Y-Achse (mit den Werten) sechs Einträge hat, so werden sechs Balken gezeichnet, wobei der letzte keine Beschriftung erhält. Wenn die X-Achse sechs Einträge hat und die Y-Achse fünf, so werden sechs Balken gezeichnet, wobei der letzte zwar beschriftet ist, aber den Wert Null erhält.
2.Die Anzahl der Datenreihen entspricht der Gesamtanzahl der Einträge in den Sequenzen, die von Ausdrücken in der For-Each-Spalte zurückgegeben werden.
3.Der Name der Datenreihe wird mit dem XPath-Ausdruck der Z-Achse (oder Datenreihennamenachse) ausgewählt. Wenn dieser XPath-Ausdruck in einer Datenauswahlzeile leer bleibt, so wird eine Datenreihe ohne Namen erstellt. Wenn außerdem der XPath-Ausdruck eine Sequenz zurückgibt, deren Anzahl der Einträge geringer ist als die der Datenreihen, dann hat eine oder mehrere Datenreihen keinen Namen.
Weitere Beispiele zur Auswahl von Daten mit der Option "flexibel" finden Sie in den folgenden Abschnitten zu folgenden Themen:
•Verwendung editierbarer Authentic-Variablen zur Datenauswahl, auch in Einzelwertdiagrammen
•XPath-Ausdrücke zur Auswahl komplexer Daten
•Verwendung der Datenreihenachse zur Generierung gruppierter Balken
•Verwendung der Datenreihenachse zur Generierung von Liniendiagrammen
•Verwendung von Literalsequenzen aus einem XPath-Ausdruck als Werte
•Verwendung von Java- und .NET-Funktionen