Client Requests
After RaptorXML+XBRL Server has been started as a service, its functionality can be accessed by any HTTP client which can:
•use the HTTP methods GET, PUT, POST, and DELETE
•set the Content-Type header field
An easy-to-use HTTP clientThere are a number of web clients available for download from the Internet. An easy-to-use and reliable web client we found was Mozilla's RESTClient, which can be added as a Firefox plugin. It's easy to install, supports the HTTP methods required by RaptorXML, and provides sufficiently good JSON syntax coloring. If you have no previous experience with HTTP clients, you might want to try RESTClient. Note, however, that installation and usage of RESTClient is at your own risk. |
A typical client request would consist of a series of steps as shown in the diagram below.
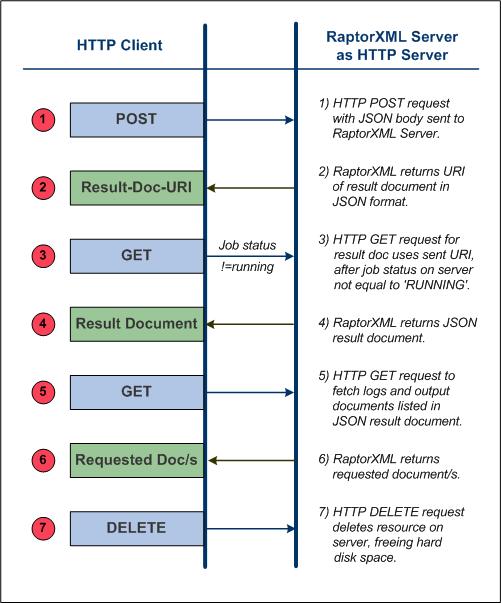
The important points about each step are noted below. Key terms are in bold.
1.An HTTP POST method is used to make a request, with the body of the request being in JSON format. The request could be for any functionality of RaptorXML+XBRL Server. For example, the request could be for a validation, or for an XSLT transformation. The commands, arguments, and options used in the request are the same as those used on the command line. The request is posted to: http://localhost:8087/v1/queue, assuming localhost:8087 is the address of RaptorXML+XBRL Server (the initial address of the server). Such a request is termed a RaptorXML+XBRL Server job.
2.If the request is received and accepted for processing by RaptorXML+XBRL Server, a result document containing the results of the server action will be created after the job has been processed. The URI of this result document (the Result-Doc-URI in the diagram above), is returned to the client. Note that the URI will be returned immediately after the job has been accepted (queued) for processing and even if processing has not been completed.
3.The client sends a request for the result document (using the result document URI) in a GET method to the server. If processing of the job has not yet started or has not yet been completed at the time the request is received, the server returns a status of Running. The GET request must be repeated till such time that job processing has been completed and the result document been created.
4.RaptorXML+XBRL Server returns the result document in JSON format. The result document might contain the URIs of error or output documents produced by RaptorXML+XBRL Server processing the original request. Error logs are returned, for example, if a validation returned errors. Primary output documents, such as the result of an XSLT transformation, are returned if an output-producing job is completed successfully.
5.The client sends the URIs of the output documents received in Step 4 via an HTTP GET method to the server. Each request is sent in a separate GET method.
6.RaptorXML+XBRL Server returns the requested documents in response to the GET requests made in Step 5.
7.The client can delete unwanted documents on the server that were generated as a result of a job request. This is done by submitting, in an HTTP DELETE method, the URI of the result document in question. All files on disk related to that job are deleted. This includes the result document file, any temporary files, and error and output document files. This step is useful for freeing up space on the server's hard disk.
The details of each step are described in the sub-sections of this section.