Integration with RaptorXML Server
When you integrate RaptorXML Server and FlowForce Server, RaptorXML Server's functions become available as built-in FlowForce Server functions. This means that you can create jobs that validate and check the well-formedness of XML and JSON documents, XBRL taxonomies and instance files. You can also perform XSLT transformations and execute XQuery documents. For more information about the RaptorXML functionality, see the RaptorXML Server documentation.
Information about compatibility
RaptorXML Server and FlowForce Server of the same release are guaranteed to be compatible. However, there might be compatibility issues if you use different versions of these products. You can check compatibility by running the integration script (as described in Integration below).
Generic vs release-specific RaptorXML functions
When you integrate the RaptorXML functionality with FlowForce Server, you will get two sets of functions: generic and release-specific functions.
Generic functions
The generic functions from the /RaptorXML container support a basic feature set that may not provide all the features of the latest installed RaptorXML Server (e.g., a generic function may support only one parameter, whereas the same function of the latest release may have multiple parameters). These functions never change and behave identically for every version of RaptorXML Server.
Release-specific functions
The release-specific functions from the /RaptorXML/{Release} container have all the latest features of that RaptorXML release.
Integration
After you have installed RaptorXML Server, together with FlowForce Server (available on Windows) or as a standalone product (available on any platform), you will need to integrate the RaptorXML functionality into FlowForce Server. The possible integration options are listed below:
•Via the FlowForce Server Setup page
•Via several CLI commands
•Via the integration script
For details, see the subsections below.
Integration via the Setup page
This is the fastest and most convenient way to integrate the RaptorXML functionality into FlowForce Server. Proceed as follows:
1.Open the Setup page. Depending on your platform, the instructions vary:
2.On the Setup page, click the Integrate Tools button for the relevant server instance.
3.In the dialog that opens, click Integrate. The log will display integration details, as shown in the screenshot below.
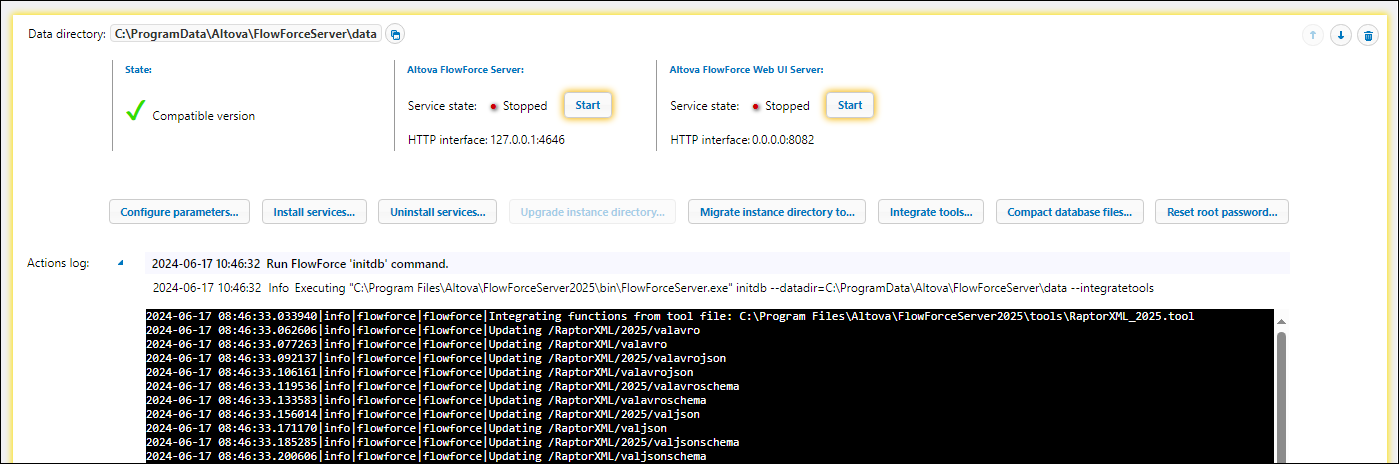
It is recommended to integrate RaptorXML Server before installing the FlowForce Server and FlowForce Web Server services. You can also integrate RaptorXML at a later stage. Note, however, that you must stop the services before being able to click the Integrate Tools button.
Integration via the CLI
You can use several CLI commands with the --integratetools options to integrate RaptorXML functions into a new (with createdb, initdb or migratedb) or into an existing (with initdb or upgradedb) FlowForce instance.
Integration via the script
Another way to integrate RaptorXML is to run the script available at the following path:
{RaptorXML installation directory}\etc\functions\integrate.bat
Note: On Unix systems, the script's name is integrate.cs. Superuser privileges (sudo) are required to run this script.
This script takes two arguments: the path to the FlowForce Server installation directory and the path to the FlowForce Server instance-data directory. When you run the script, the following will happen:
•All the release-specific functions of the integrated RaptorXML Server version will become available in FlowForce Server. The release-specific functions will have all the latest features of that release.
•The generic RaptorXML functions will be updated in such a way that they will map to the newly integrated version. This means that the generic functions will use the new RaptorXML version to provide the generic functionality, but they will not support a feature set beyond the generic one.
For details about release-specific and generic RaptorXML functions, see Generic vs Release-specific RaptorXML Functions above.
If the script returns errors, the function definitions of the integrated RaptorXML version are not compatible with FlowForce Server. In the unlikely event that this happens, please contact support.
How to call RaptorXML functions
After you have integrated RaptorXML into FlowForce, all the RaptorXML Server functions become available in the /RaptorXML container of FlowForce (screenshot below). In the case of RaptorXML+XBRL Server, the container's name is /RaptorXMLXBRL.
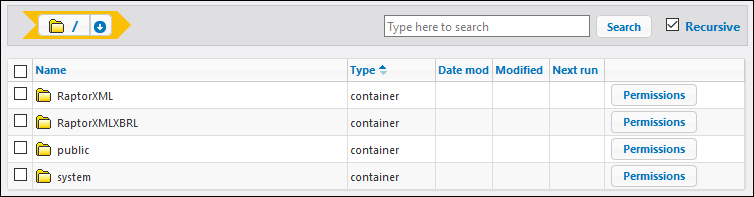
You can call RaptorXML's functions in one of the following ways:
•By navigating to the /RaptorXML (or /RaptorXMLXBRL) container, opening a function of interest, and then clicking Create Job. You can select generic functions such as /RaptorXML/valjson or release-specific functions such as /RaptorXML/2025/valjson. The differences between the two are described above.
•By creating a new execution step in a job and calling the desired RaptorXML function from this step. For example, the step below calls the valjson function:
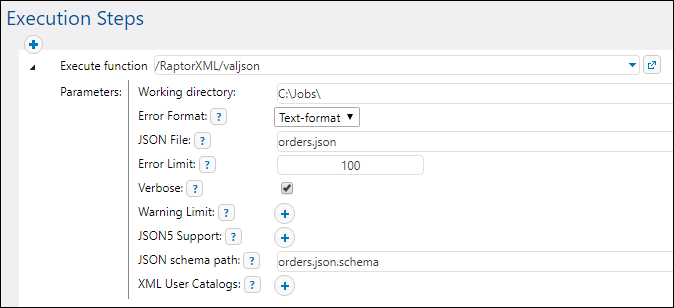
For examples of jobs that call RaptorXML Server, see:
•Validate a Document with RaptorXML
•Validate XML with Error Logging
•Use RaptorXML to Pass Key/Value Parameter Pairs
For information about the available RaptorXML functions, see the RaptorXML Server documentation.
How to upgrade release-specific RaptorXML functions to a newer version
If your jobs refer to release-specific functions of older versions (e.g., 2022), and you have integrated a newer version of RaptorXML Server (e.g., 2024), the older release-specific functions will not be updated automatically in your jobs. To upgrade to a newer version of RaptorXML functions, you can use any of the following methods:
•You can go through each job and manually replace RaptorXML functions of older versions with the newer ones.
•Alternatively, you can copy the RaptorXML_<release>.tool file from {INSTALLDIR}\etc directory of RaptorXML Server of the latest installed release to the {INSTANCEDIR}\tools directory of FlowForce Server. After that, you will need to rename the file to match the version of the release your jobs refer to. For example, if the old release is RaptorXML Server 2022, then name the file RaptorXML_2022.tool. All the existing jobs will continue to look as if they called RaptorXML 2022 functions, whereas the new .tool file will map in fact to the RaptorXML Server 2024 executable.
If your jobs reference generic RaptorXML functions, you do not need to take any actions.
Information about .tool files
FlowForce Server uses .tool files to locate other Altova server products that run under its management. Tool files are a crucial part of RaptorXML integration, because they enable FlowForce Server to find the relevant RaptorXML Server executable and locate different RaptorXML versions. These files can also be used to set environment variables. A separate .tool file exists for each RaptorXML Server release. For more information about .tool files, see Tool Files.