Text Search for Precise PDF Data Extraction
PDF documents are used at many stages of modern business workflows, often serving as the format of choice for invoices, reports, legal contracts, and other critical documents. While PDFs are ideal for preserving content integrity and a particular visual layout, their structure makes automated data extraction challenging. For organizations engaged in data integration and ETL, unlocking information contained in PDFs is a necessity—and this is where the MapForce PDF Extractor comes in.
The MapForce PDF Extractor includes multiple tools for visually defining extraction rules to map PDF data to other formats. One that is particularly useful for zeroing in on specific content is text search. Here’s how it works – including a video demo.

Access PDF Data for ETL
Though they often contain critical data, PDFs are not inherently designed for data processing. Unlike structured formats such as XML or JSON, PDFs prioritize presentation over content accessibility.
This can create bottlenecks, forcing organizations to rely on time-consuming manual processes to get the data they need from PDFs. Automating data extraction eliminates manual data entry, reducing human error while freeing resources for higher-value tasks.
The MapForce PDF Extractor makes this easy, offering a straightforward way to define the structure of a PDF document in order to extract data from it in an automated way. As you define extraction rules, the utility builds a tree model that represents the data structure. Using this, the extracted data can be mapped to other formats like databases, JSON, and XML in MapForce.
Using visual tools and drag-and-drop functionality, you can extract only portions of the content, mix and match pieces of content from different pages, split tables into rows, group content, and more. In addition to point and click functionality for adding document sections to your template manually, MapForce includes a suggestion engine that identifies tables so they can be extracted automatically. Then, the PDF data extraction rules can be further refined as necessary.
In PDFs with many tables, it can be helpful to define extraction rules using a text search.
Search for Text to Extract PDF Data
The MapForce PDF Extractor includes the option to search for text in a document in the interface as well as at runtime.
This is especially useful in large PDF documents with numerous tables where you may only need to extract some of the data or when you need to define rules for recurring elements. For instance, when creating a template to extract data from yearly financial reports, you could search for “Expenditures” and process the table of figures following that text accordingly.
Granular search options such as case sensitivity, format filtering (font, font weight, etc.), and whole or partial word searches, allow for precise targeting.
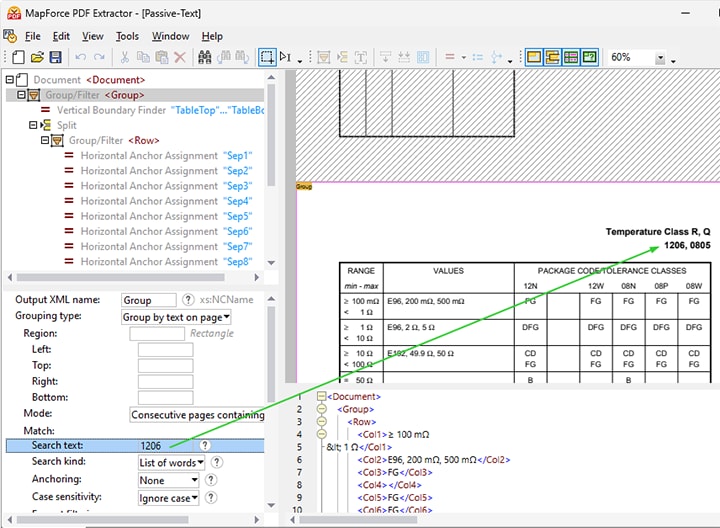
The search functionality lets you define rules for processing data relative to the search term. These include:
- Split a region based on a search term (e.g., “article number” in the demo video below)
- Group data by text that is found on a page (e.g., “article details” in the video)
The ability to pinpoint and extract only the relevant tables and snippets based on a text search streamlines template creation, saving time and increasing accuracy.
Here’s a look at the text search functionality of the MapForce PDF Extractor in action. In this tutorial, you’ll learn to use text search for creating a template to map PDF data to JSON, a common requirement in data integration and ETL processes.
Once your PDF extraction template is defined, you can add it to a MapForce data mapping project to convert it to another format or process it for storage in a database.
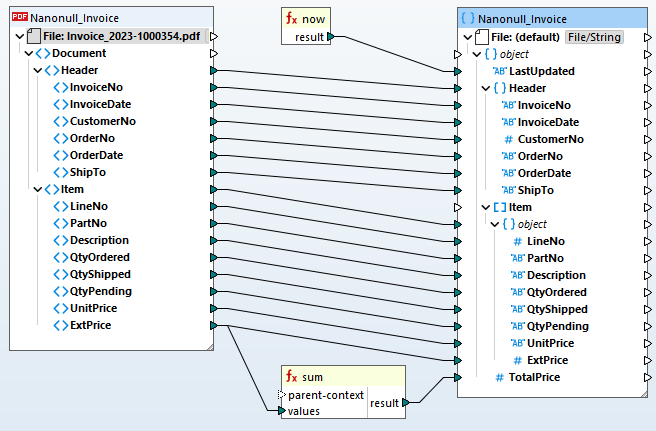
For automating PDF ETL pipelines, MapForce Server supports PDF extraction rules defined in MapForce.
Try this for yourself with a free, 30-day trial of MapForce.