The following post is written by Peter Reynolds, CEO and translation management consultant at TM-Global and Executive Director of Kilgray Translation Technologies. An Irish national based in Warsaw, he holds a BSc and an MBA degree from Open University and is a localization and translation industry veteran. Peter previously worked at Idiom Technologies Inc. — now SDL PLC. As director of the LSP Partner Program at Idiom, Peter was responsible for making its global LSP partners program a successful and innovative venture. Before Idiom, he worked on language technology development for several global localization companies: Lionbridge, Bowne Global Solutions and Berlitz GlobalNET. He managed the Dublin development team responsible for BerlitzIT, Elcano, Freeway 2.0 technology solutions, and internal project and vendor management tools. Peter has been actively involved in the development and promotion of standards (notably XLIFF) for more than ten years, mostly at OASIS. Until 2008 when XLIFF was published, he was secretary of the XLIFF Technical Committee at OASIS and chaired the Translation Web Services TC. He is currently involved in OASIS, TILP as well as being the Irish expert to ISO SC2 and SC4 and training auditors for the EN 15038 standard.
Introduction
Every developer wants his or her applications to be used and hopes they will be very popular. A web application developed in rural Maine USA could easily be used by someone living in the next township or in Malaysia, New Zealand, Germany or Poland. Even if the application is not translated (localized), there are some important differences between how data is represented from one locale to another. The W3C definition of internationalization is “the design and development of a product that is enabled for target audiences that vary in culture, region, or language”. This does not mean that the product has to be translated into the language of the target audience but that it is designed in such a way that the target audience can use the application and understands the way data is presented. The reason for internationalization is to ensure the widest possible audience for your application and to make its translation easier and less costly. This article will introduce you to internationalization and demonstrate how applications can be internationalized using the Altova MissionKit, an integrated suite of XML, database, and UML tools including XMLSpy, StyleVision, MapForce, and others. If you are using tools such as XMLSpy and StyleVision it is very likely that you are already creating internationalized XML applications. The strategy which I suggest is that you try and figure out what target audience your applications are intended for beforehand and implement internationalization accordingly. In this article I will first discuss a strategy for internationalizing XML. I will then introduce the Internationalization Tag Set and examine issues relating to XML internationalization.
Strategy for Internationalizing XML
The first step in planning internationalization is to make an informed decision as to the level of internationalization you require. There may be people in your organization who can help you make this decision, and it would be particularly useful to obtain input from people who live in different countries. The three-level approach presented below should help you decide on the level of internationalization you are going to implement. However, you should remember that you may encounter some problems if your documents or applications are not internationalized, but you will certainly not have the same problems if to ensure that they are fully internationalized. The three levels of internationalizations are:
- Level 1 – Your applications are likely to have a relatively small audience, which could grow, but the applications are unlikely to be translated or used internationally. In that case you should just follow the suggestions in this article and ensure that you use the functionality in Altova MissionKit to support internationalization.
- Level 2 – Your applications will have a wide audience and could be translated and used internationally. As well as using the Altova MissionKit functionality you should also use the Internationalization Tag Set. This is a schema released by the W3C for the purpose of internationalization.
- Level 3 – Your applications are most likely to be used internationally and translated into a number of different languages. You should consider how to improve the localization process by separating content from code and ensuring the translators can see the document or application as the end user would see it. This is beyond the scope of this article but you will find some relevant information on the subject in the references below.
The software tools in the Altova MissionKit have a lot of functionality which supports internationalization. If you are using these tools you have a very strong basis for creating internationalized XML documents. Unicode is the default encoding for applications created in the XMLSpy XML editor, and I would strongly recommend using this character set.
Internationalization Tag Set
The Internationalization Tag Set (ITS) is recommended by W3C and designed to create XML which is internationalized and can easily be localized. If you are working with XML documents which might be localized, I would recommend using ITS. With this technology you are able to specify which text requires translation, provide instructions for translators and specify the direction of the text. The seven data categories included in the ITS are:
- Translate: Defines which parts of a document are translatable.
- Localization Note: Provides notes and helpful information for translators.
- Terminology: Identifies terms in the documents.
- Directionality: Indicates the direction which the document or part of the document is written and should be read.
- Ruby: Indicates which parts of the document should be displayed as ruby text. (Ruby is a short run of text alongside a base text, typically used in South-East Asian language documents to indicate pronunciation or to provide a brief annotation).
- Language Information: Identifies language used for the different parts of the document.
- Elements Within Text: Indicates how elements should be treated with regard to linguistic segmentation.
W3C has published a best practices guide for internationalizing XML documents which details how to use ITS. It can be found on their web site at: http://www.w3.org/TR/2007/WD-xml-i18n-bp-20070427/ The specification can be found in this section: http://www.w3.org/TR/2007/REC-its-20070403/ I would strongly recommend you read these documents before proceeding with internationalization.
Internationalization Issues
The following table describes some of the internationalization issues you may come across. This will be followed by a more detailed explanation of these issues and suggestions for how they can be resolved using the Altova MissionKit. 
| ISSUE | DESCRIPTION |
| Encoding | Characters need to be supported by the code page being used. Unicode is an encoding which supports characters from all common language. |
| Date & Time | How dates and time are represented varies between countries. |
| Numbers | How decimal points and thousands are represented varies between different countries. |
| Currency | As well as difference with how the number is represented in some countries the currency symbol or word is written after the number while in most it is written before. |
| Salutation & Names | There are many differences in salutations between countries, and in some countries, such as Hungary, a person’s name is written with the family name first. No middle name is used in Japanese. |
| Address | There are a number of differences relating to address, such as the house number appearing before the street name in some countries and after in others. Also, some countries use a ZIP code vs. a postal code. |
| RTL | Text is many languages is read from left to right, but in some, such as Hebrew and Arabic, the text is read from right to left (bi-directional). |
| Sorting & Collation | There are differences in how alphabets are sorted. Some Scandinavian languages have an ‘aa’ character which is usually, but not always, sorted at the end of the alphabet. |
| Exclamation & Question Marks | In English questions and exclamation marks are always at the end of the sentence, while in Spanish there is a question mark at the beginning and end of a sentence. |
Encoding
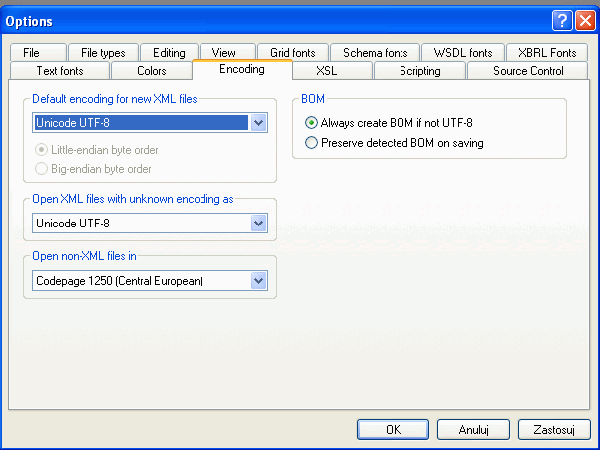
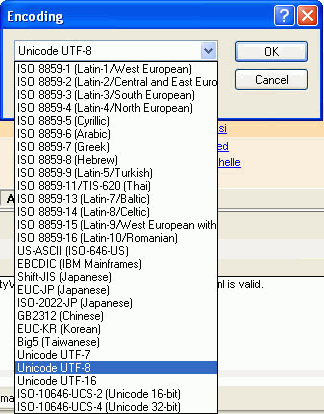
All electronic text uses a character coding system where the character is represented by a number. Before the widespread use of Unicode this was one of the most significant internationalization issues. When an application tries to show a character that is not represented in a code page it will appear as garbage text. There were not only problems between different languages but also with characters appearing incorrectly on computers running different operating system. Unicode has solved most of these problems by creating a single code page regardless of platform, program or language. XML uses Unicode as its default code page. Any XML documents you create in XMLSpy will by default have the declaration encoding="UTF-8” If the file has not been created in XMLSpy, you need to ensure that the file is saved as UTF-8. UTF is an acronym for Unicode transformation format, and UTF-8 is a flavor of Unicode that uses 1, 2 or 4 bytes to store characters. It is the most commonly used flavor and is very widely used for XML and the Web. The other versions of Unicode which XMLSpy supports are:
- UTF- 7. This is 7 bit version of Unicode. It should only be used in the context of 7 bit transports, such as email.
- ISO 1064 UCS – 2 and UTF – 16. UCS is an acronym for Universal Character Set and UCS-2 uses two bytes for each character. UTF-16 is an extension of UCS-2 which uses 2 or 4 bytes to represent a character. UTF-16 is often used by Windows and Java. You should use UTF – 16 rather than UCS – 2 for new documents.
- ISO 1064 UCS- 4. Uses 4 bytes for each character and is the same as UTF-32. UTF-32 is often used by Unix.
There may be reasons for using default encoding other than UTF-8. To set the default encoding in XMLSpy go to Tools | Options and select the encoding tab.  If you want to change the encoding for an individual XML document, open the document in XMLSpy and select File| Encoding.
If you want to change the encoding for an individual XML document, open the document in XMLSpy and select File| Encoding. 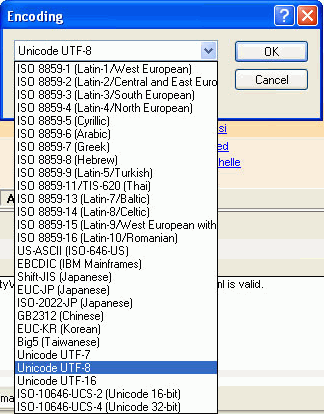
Language
The XML namespace defines xml:lang to identify the language of an XML document. The value for xml:lang must be an ISO language code (ISO 639- 2). If you have an XML document which is written in one language but has a segment in another language you can use xml:lang at the root element to identify the main language of the document and use it at the element where the text in another language is used to identify that language.
Dates
In different countries dates and time are represented in very different ways. Let’s take as an example the date 10/09/08:
In most European countries this means the 10th of September 2008.
In the United States this means the 9th of October 2008.
In Japan this means 8th of October 2009.
The way to deal with this is to use ISO 8601 for specifying date and time within your application. This is a standard way for representing date and time in the format YYYY-MM-DDTHH:MM:SS[±HH:MM] where
YYYY- represents year
MM- represents month
DD – represents day
T signifies that Time follows this
HH- represents hours
MM- represents minutes
SS- represents seconds.
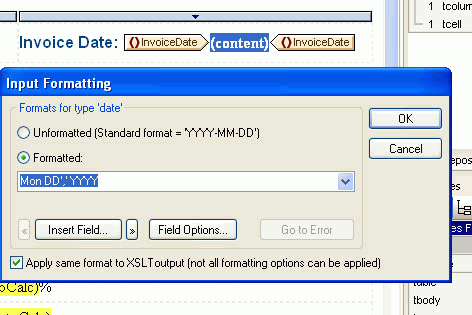
You can then use StyleVision to create a style sheet which formats the date in a way suitable to your target audience. StyleVision is a graphical stylesheet design tool that allows drag-and-drop design of XSLT and XSL:FO stylesheets to render XML data in HTML, Microsoft Word, PDF, and other formats. To use the date formatting functionality within StyleVision:
- Select the contents placeholder or input field of the node.
- In the Properties sidebar, select the content item, and then the Content group of properties.
- Click the Edit button of the Input Formatting property.
- The Input Formatting dialog will appear:
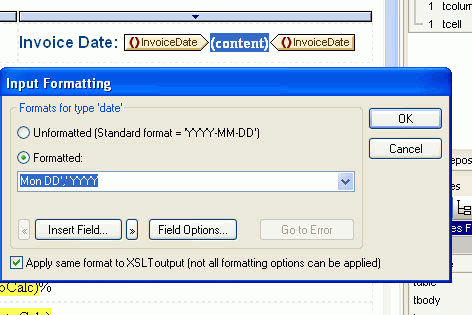
- Select the Formated radio button. This will allow you to choose which data type you would like to use, and if you have selected a date, you can then choose the format for the date.
You can also select other date and time formats here. I would strongly recommend using the date picker. In order to insert the date picker, the cursor must be between an xs:date or xs:dateTime node. You then go to Insert on the main menu and Select Insert Date Picker. If the cursor is not between xs:date or xs:dateTime node the Insert Date Picker menu item will be greyed out.
Numbers
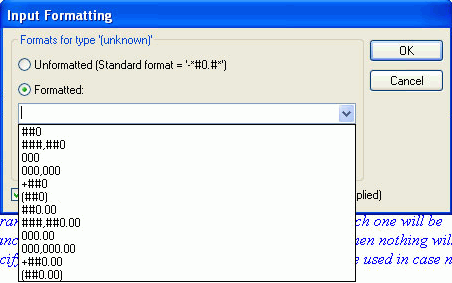
Decimals can be preceded by either a point or a comma depending on the locale. There are also differences for how thousands are represented. StyleVision provides functionality where you can format a number for your intended audience:
- Select the contents placeholder or input field of the node.
- In the Properties sidebar, select the content item, and then the Content group of properties.
- Click the Edit button of the Input Formatting property.
- The Input Formatting dialog will appear
- Select the Formatted radio button. This will allow you to choose the number format.
Money
The issues involving numbers also apply to money, but in addition to this there are different conventions for representing the currency symbol. Some currencies share the same name and symbol, such as the dollar, but the Australian, Canadian and Singaporean dollar are not the same currency, and this should be identifiable. You can deal with the numbers as shown above, but the issue of whether the currency name or symbol should go before or after the number is likely to be dealt with as part of the translation process.
Address
One of the problems faced by customers buying from a foreign company while making an online purchase is that the system does not allow them to enter their address properly. There are many differences, such as the house number being before or after the street name, the order the components of the address are placed and the format of the zip/postal code. CEN (The European Standards Institution) has developed a standard which lists the components of an address, and the UPU (Universal Postal Union) is further developing this to produce a comprehensive list of name and address elements. I would recommend that you ensure that you are getting the data you need for your main target markets but make sure that someone from another country can also enter their address. A drop-down list of countries could be used to ensure that there is error checking when you know certain components of an address are required but does not produce the error for other countries where you do not know the address structure.
Credit Cards
Some US-based web sites will not accept credit cards from outside the US. As a security check they insist on a valid US address. If you want to accept credit card payments and do business with people outside your country, you should check that foreign credit cards will be accepted.
RTL (bidi)
In many languages the text is being read from left to right but this is by no means universal. Arabic and Hebrew are written from right to left. In XML documents this causes further confusion as the XML elements are read from left to right but any text should be read from right to left. The ITS namespace has a direction attribute which can be used to identify which direction should be read. <its:span dir="rtl">متعة الأسماك!</its:span>
Sorting
There are differences in how alphabets are sorted. Some Scandinavian languages have an ‘aa’ character which is usually, but not always, sorted at the end of the alphabet. If you have set the language in your XML document and use xsl:sort for your XSL document then the sorting should work according to the sorting rules for that language. However, you should check that your processor does this as that is not always the case. The example files which come with StyleVision contain examples for sorting. Select StyleVision examples, then the tutorial folder, then sorting and open the file SortingOnTwoTextKeys.sps. To see how the sorting works go to the design view and right click on the member element. Then select the ‘sort by’ option on the context menu. Here you can control how the sorting works for this particular list.
Exclamation and Question Marks
In English, questions and exclamation marks are always at the end of the sentence, while in Spanish this punctuation occurs at the beginning and end of a sentence. This is something which will usually be corrected during the translation process.
Conclusions
Internationalization is an important step in ensuring the widest target audience for your application, and that translation is as cost effect and easy as possible. Your approach to this should be very pragmatic. Time spent up-front sorting out internationalization will result in huge benefits throughout the process and significantly increase marketing potential for your product. The purpose of this article was to present an overview and introduce you to internationalization. There is a lot more useful information available in the references listed below. Tools such as XMLSpy and StyleVision, both of which are included in the Altova MissionKit software suite, go a long way in making the internationalization process for XML documents much easier by providing a lot of in-built support for internationalization. The Internationalization Tag Set from W3C is a very significant innovation which is a great addition to the toolkit available to a developer who wants to build internationalized XML applications. XML is a technology which has had internationalization and translation in mind since its inception. The use of Unicode as the default encoding for XML is very significant and greatly facilitates dealing with any internationalization problems you may come across. The functionality available within the Altova MissionKit, ITS and Unicode are the basis for creating good internationalized applications. Reference The following is a list of useful web sites and other resources providing further information on internationalization: Leading XML tools provider – Altova https://www.altova.com/ . They also offer a free trial of the MissionKit: https://www.altova.com/download. Unicode web site http://www.unicode.org/ Internationalization Tag Set http://www.w3.org/TR/2007/REC-its-20070403/ W3C Best Practices for internationalization http://www.w3.org/TR/2007/WD-xml-i18n-bp-20070427/ Open Tag (Yves Savourel’s) http://www.opentag.com/ Yves Savourel, ‘XML Internationalization and Localization’, a book which is an excellent source of information. More information can be found at: http://www.opentag.com/xmli18nbook.htm The TM-Global research and resource web site publishes a lot of useful articles, opinions and surveys on translation, localization and industry standards http://www.tm-global.com/ Web sites of internationalization guru Tex Texin http://www.xencraft.com/ and http://www.i18nguy.com/ Localization Flow – web site of internationalization experts http://www.locflowtech.com/ Value for money XML-based TEnTs and translation tools are available from companies such as Kilgray Translation Technologies http://www.kilgray.com/

















































 Or, to go in the other direction, it’s just as easy to
Or, to go in the other direction, it’s just as easy to 















 Let’s take a look at how we created this XSLT code.
Let’s take a look at how we created this XSLT code.









 You can also verify signature(s) on files received. If the file changed at all since it was signed, verification will fail.
You can also verify signature(s) on files received. If the file changed at all since it was signed, verification will fail. 





 XMLSpy 2011r2 also ships with several useful documentation templates that can be used as is or customized further in StyleVision:
XMLSpy 2011r2 also ships with several useful documentation templates that can be used as is or customized further in StyleVision:















 We recently blogged about the
We recently blogged about the 
 To create a new chart, simply highlight a range of data in Text View or Grid View, right click, and select New Chart. You can also specify the data to chart via XPath expression. Once you’ve used the Select Columns dialog to specify which data you want displayed, either via XPath or by highlighting it in the window, and how you want to display it….
To create a new chart, simply highlight a range of data in Text View or Grid View, right click, and select New Chart. You can also specify the data to chart via XPath expression. Once you’ve used the Select Columns dialog to specify which data you want displayed, either via XPath or by highlighting it in the window, and how you want to display it….  …you can choose the type if chart you require, and the appearance of the chart, from colors to fonts and more. You can
…you can choose the type if chart you require, and the appearance of the chart, from colors to fonts and more. You can 
 Read about all the
Read about all the 








































 When we
When we 


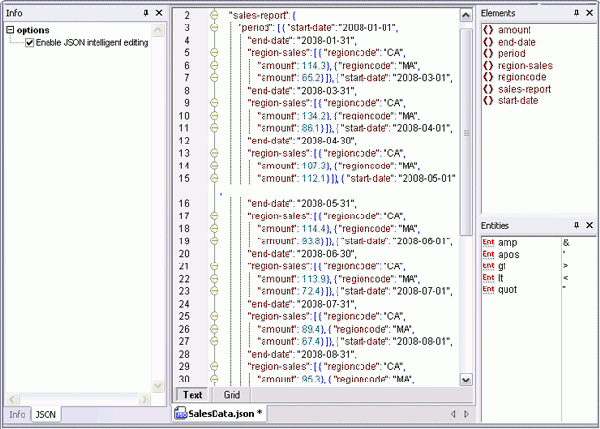
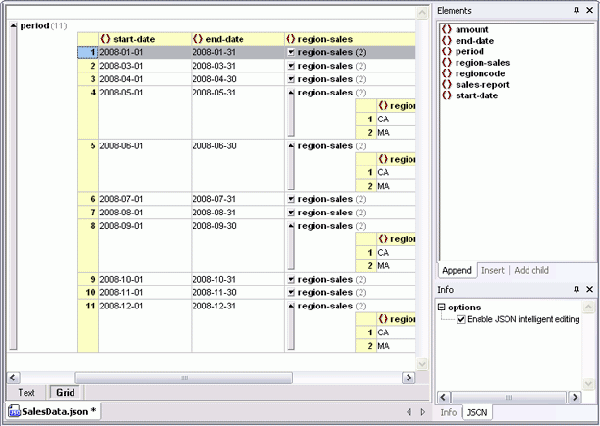 A final must-have feature for working with JSON is the JSON <=> XML converter in XMLSpy 2010. One click lets you, for example,
A final must-have feature for working with JSON is the JSON <=> XML converter in XMLSpy 2010. One click lets you, for example, 







 Of course let’s not forget that the XMLSpy
Of course let’s not forget that the XMLSpy 



 MapForce 2009 –
MapForce 2009 – 

 and a small snippet of the same piece translated to MusicXML:
and a small snippet of the same piece translated to MusicXML:  The MusicXML-based Dolet 4 plugins for Finale and Sibelius provide a more accurate and usable representation of sheet music than Standard MIDI translation. For example, the images below show the same piece of music. On the left is a Finale 2009 rendering of a MIDI file exported from Sibelius, and on the right is the same application’s interpretation of a MusicXML 2.0 file exported from the same version of Sibelius.
The MusicXML-based Dolet 4 plugins for Finale and Sibelius provide a more accurate and usable representation of sheet music than Standard MIDI translation. For example, the images below show the same piece of music. On the left is a Finale 2009 rendering of a MIDI file exported from Sibelius, and on the right is the same application’s interpretation of a MusicXML 2.0 file exported from the same version of Sibelius. 
 In the MIDI rendition, vital information like chord symbols, lyrics, slurs, articulations, and even title and composer are omitted from the translation. In addition to providing native support for MusicXML, the recently released Dolet 4 for Finale and Dolet 4 for Sibelius plugins enhance the capabilities of these programs by adding advanced features like:
In the MIDI rendition, vital information like chord symbols, lyrics, slurs, articulations, and even title and composer are omitted from the translation. In addition to providing native support for MusicXML, the recently released Dolet 4 for Finale and Dolet 4 for Sibelius plugins enhance the capabilities of these programs by adding advanced features like: Recordare has used Altova’s XMLSpy
Recordare has used Altova’s XMLSpy 



 This WSDL serves as the basis for the eIDverifier application, defining the ports and messages that make up the communication infrastructure of the Web service.
This WSDL serves as the basis for the eIDverifier application, defining the ports and messages that make up the communication infrastructure of the Web service. XMLSpy enabled the Equifax team to quickly and easily create a graphical schema representation and the matching documentation to serve as the basis for the Web service. It also allowed the development team to focus on their Java code, rather than the intricacies of XML Schema and WSDL design. The Altova MissionKit provides numerous tools for advanced Web services development, from the graphical XML Schema and WSDL editing discussed here, to SOAP debugging, and even graphical Web services generation and data mapping.
XMLSpy enabled the Equifax team to quickly and easily create a graphical schema representation and the matching documentation to serve as the basis for the Web service. It also allowed the development team to focus on their Java code, rather than the intricacies of XML Schema and WSDL design. The Altova MissionKit provides numerous tools for advanced Web services development, from the graphical XML Schema and WSDL editing discussed here, to SOAP debugging, and even graphical Web services generation and data mapping.