The hardships affecting today’s economy present new challenges for organizations. Interdepartmental budgets are being cut, and large purchases are being carefully scrutinized. Costly enterprise software and mainframe computing systems that once held promise are being reconsidered on a global scale in favor of more agile, component-based systems that cut costs and increase efficiency with forward-thinking concepts like Service-oriented Architecture (SOA) and cloud computing. These architectural concepts incorporate modern technologies and object-oriented approaches to solve real-world technology issues in complex environments while decreasing maintenance, integration, and deployment costs with modular design and component re-use. The Altova MissionKit is a highly affordable toolset uniquely suited to address this shift toward more flexible and lightweight infrastructure. With strong support for XML, UML, databases, and data integration technologies, the MissionKit offers all of the tools necessary to build agile architectures replete with repeatable services, reusable components, and scalable resources.
SOA & Cloud Computing
SOA and Web/cloud services are two of the strongest buzzwords in technology today. Though they have some clear differences, both of these concepts represent a paradigm shift from large-scale enterprise systems to service-based architectures built on modular components and reusable functionality. The SOA approach aims to help organizations respond more quickly to business requirements by packaging processes as a network of interoperable and repeatable services. This modularity creates system flexibility and gives developers the agility required to build new capabilities into the current system as needed – without reinventing the proverbial wheel. SOA is essentially a series of interconnected and self-contained services, the functionality of which is dynamically located and invoked based on certain criteria, communicated in messages. At the heart of SOA is a high level of component reuse that drives down costs and increases efficiency in a fully scalable architecture. Cloud services build upon the concept of interoperable services, adding a virtualization component to help relieve internal servers from being overtaxed by the constant reuse of these services within the system. This paradigm uses the Internet and Internet-enabled technologies to increase performance and processing speed by storing information permanently in the "cloud" and caching it only temporarily on client machines. Cloud computing implementation is a powerful option for increasing system capacity and capabilities by leveraging next-generation data centers in combination with the World Wide Web. Both SOA and cloud computing seek to alleviate problems created by inflexible architectures that rely heavily on tightly coupled enterprise application infrastructure. This focus on interoperability and independent software services reveals a distributed solution that is event-driven, flexible, and cost conscious in almost any setting.
Anatomy of a Service-based Architecture
Since their inception, XML and Web services have been continuously gaining notoriety as the standards of choice for secure, efficient, and platform-independent data exchange between software applications and over the Internet. XML provides the foundation for the protocols that power Web services infrastructure: WSDL (Web Services Description Language) and SOAP, an XML-based messaging standard. Web services are hardware, programming language, and operating system independent, meaning that they are duly amenable to the seamless and interoperable exchange of data over a network and uniquely suited to component-based systems. Web services architecture  Both SOA and cloud-based architectures generally rely on WSDL to describe interaction and functionality and locate operating components within the system. WSDL works hand-in-hand with SOAP, a messaging protocol used by the client application to invoke the methods and functions defined in the WSDL description. The example below is the stock quote example used in the W3C WSDL specification and describes a simple, single operation service that retrieves real-time stock prices based on ticker symbol input. Of course, most services that exist within enterprise architectures are far more complex.
Both SOA and cloud-based architectures generally rely on WSDL to describe interaction and functionality and locate operating components within the system. WSDL works hand-in-hand with SOAP, a messaging protocol used by the client application to invoke the methods and functions defined in the WSDL description. The example below is the stock quote example used in the W3C WSDL specification and describes a simple, single operation service that retrieves real-time stock prices based on ticker symbol input. Of course, most services that exist within enterprise architectures are far more complex. 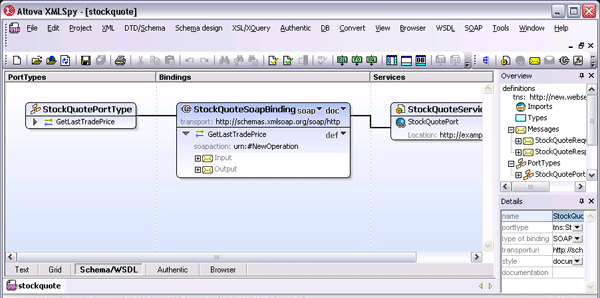 Take, for example, the publicly available Amazon Web services, which provide accessible Cloud services and infrastructure to a growing number of companies worldwide, including Twitter, SmugMug, and WordPress.com. These services essentially allow independent organizations to rent some of the immense power built into the Amazon distributed computing environment and add the same scalability, reliability, and scalability to their online presence at a fraction of the price. The much anticipated Windows Azure from Microsoft® operates on a similar model, giving developers the opportunity to build and deploy cloud-based applications with minimal on-site resources. Amazon provides a WSDL file that contains the definition of the Web service, the requests that the service accepts, and so on. Developers can then write a SOAP-based client application that invokes the Amazon Web service for the functionality it provides. (At this time Amazon provides a number of Cloud-based services for application hosting, backup and storage, content delivery, e-commerce, search, and high-performance computing.)
Take, for example, the publicly available Amazon Web services, which provide accessible Cloud services and infrastructure to a growing number of companies worldwide, including Twitter, SmugMug, and WordPress.com. These services essentially allow independent organizations to rent some of the immense power built into the Amazon distributed computing environment and add the same scalability, reliability, and scalability to their online presence at a fraction of the price. The much anticipated Windows Azure from Microsoft® operates on a similar model, giving developers the opportunity to build and deploy cloud-based applications with minimal on-site resources. Amazon provides a WSDL file that contains the definition of the Web service, the requests that the service accepts, and so on. Developers can then write a SOAP-based client application that invokes the Amazon Web service for the functionality it provides. (At this time Amazon provides a number of Cloud-based services for application hosting, backup and storage, content delivery, e-commerce, search, and high-performance computing.)
Altova MissionKit
Recently named "Best Development Environment" in the Jolt Product Excellence Awards, the Altova MissionKit is a diverse set of software tools that provides scalable options for leveraging your current software assets in an SOA or cloud-enabled environment. Strong support for XML, Web services, data integration, process automation, and databases, as well as accessibility to powerful APIs give developers flexible options for creating service-based solutions and an affordable alternative to costly consultant fees, extract/transform/load (ETL) tools, and/or enterprise service bus (ESB) products. The Altova MissionKit* supports end-to-end Web services development and includes a graphical WSDL editor, visual Web services builder, advanced capabilities for managing WSDL and other XML file relationships, a SOAP client and debugger, WSDL data integration, code generation, and more. Together, all of these features provide a robust solution for integrating disparate services and systems in a distributed computing environment, whether the components be in-house, network, or Cloud-based.
WSDL Editor
The XMLSpy XML editor provides a graphical interface (GUI) for designing and editing WSDL documents. The structure and components of the WSDL are created in the main design window using graphical design mechanisms (with tabs allowing users to toggle back and forth between text view), and additional editing capabilities are enabled from comprehensive entry helper windows. Users can easily create and edit messages, types, operations, portTypes, bindings, etc., inline. In addition, publicly maintained WSDL files like the Amazon Simple Storage Service, or Amazon S3, (below) can be opened instantly using the Open URL command in XMLSpy. 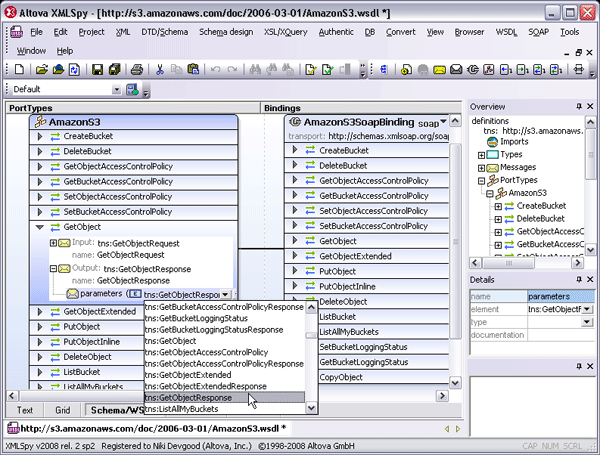 XMLSpy’s WSDL editor gives developers a sophisticated environment for rapid Web services development, managing WSDL syntax and validation through an intuitive, drag and drop graphical interface. The addition of a documentation generation feature makes it possible to share the complete details of a Web service interface with non-technical stakeholders in HTML or Microsoft Word.
XMLSpy’s WSDL editor gives developers a sophisticated environment for rapid Web services development, managing WSDL syntax and validation through an intuitive, drag and drop graphical interface. The addition of a documentation generation feature makes it possible to share the complete details of a Web service interface with non-technical stakeholders in HTML or Microsoft Word.
SOAP Client
SOAP requests can be manually created in XMLSpy’s SOAP client based on the operations defined in the WSDL. Once an operation is selected, XMLSpy initiates the request based on the connections provided in the WSDL and displays the XML syntax of the SOAP envelope in the main window. The message can then be sent directly to the server for an immediate response. 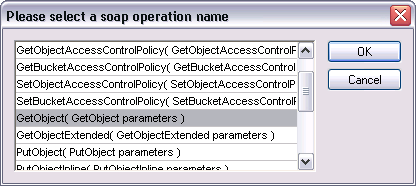
SOAP Debugger
XMLSpy also includes a SOAP debugger, which acts as Web services proxy between client and server, enabling developers to analyze WSDL files and their SOAP message components, single-step through transactions, set breakpoints on SOAP functions, and even define conditional breakpoints that are triggered by a stated XPath query. 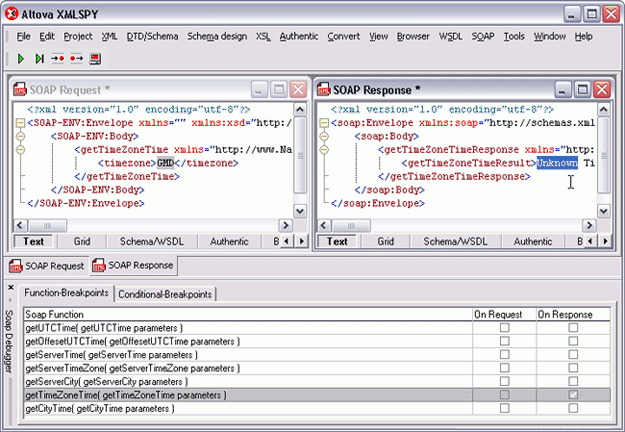
Building Web Services
Once a WSDL definition is complete, it can also be visually implemented using MapForce, Altova’s any-to-any data integration tool. MapForce gives users the ability to map data to or from WSDL operations and then autogenerate program code in Java or C#. Tight integration with Visual Studio and Eclipse makes it possible to then compile the code within either of these IDEs and deploy the service on the client machine. When you create a new Web service project by specifying a Web services definition file (WSDL), MapForce automatically generates mapping files for each individual SOAP operation. 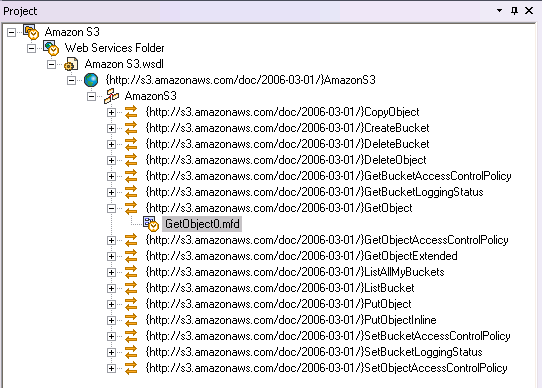 The SOAP input and output messages can then be easily mapped to other source data components (XML, databases, flat files, EDI, XBRL, Excel 2007) to create a complete Web services operation. Data processing functions, filters, and constants can also be inserted to convert the data on the fly.
The SOAP input and output messages can then be easily mapped to other source data components (XML, databases, flat files, EDI, XBRL, Excel 2007) to create a complete Web services operation. Data processing functions, filters, and constants can also be inserted to convert the data on the fly. 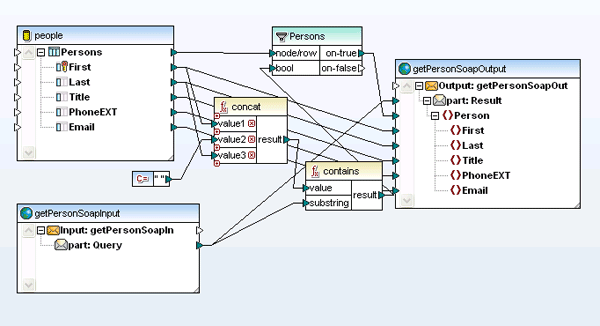 MapForce can autogenerate Web services implementation code in Java or C# for server-side implementation, and it is also accessible for automation via the command line.
MapForce can autogenerate Web services implementation code in Java or C# for server-side implementation, and it is also accessible for automation via the command line.
File Relationship Management
For complex Web-based applications that include a large number of disparate files and project stakeholders, the MissionKit offers an advanced graphical XML file relationship management tool in SchemaAgent. SchemaAgent can analyze and manage relationships among XML Schemas, XML instance documents (SOAP), WSDL, and XSLT files. The client/server option enables any changes to be visualized in real time across a workgroup. 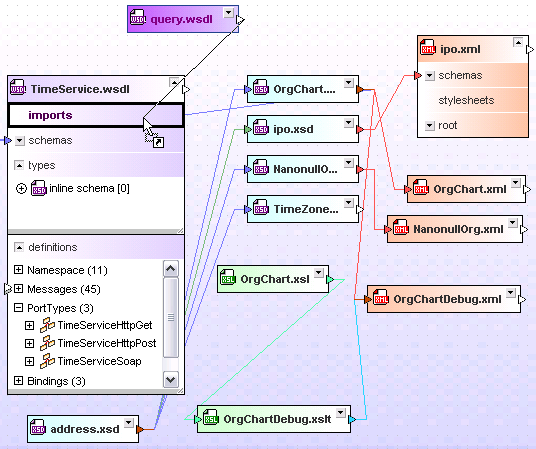 This gives organizations the ability to track and manage their mission critical SOA files as reusable individual components, reducing development time and the occurrence of errors.
This gives organizations the ability to track and manage their mission critical SOA files as reusable individual components, reducing development time and the occurrence of errors.
Data Integration
A key factor of any SOA is the ability for disparate systems to communicate seamlessly via automated processes. As an any-to-any graphical data integration and Web services implementation tool, MapForce facilitates this undertaking with support for a wide variety of data formats including XML, databases, flat files (which can be easily parsed for integration with legacy systems with the help of the unique FlexText™ utility), EDI, XBRL, Excel 2007, and Web services. 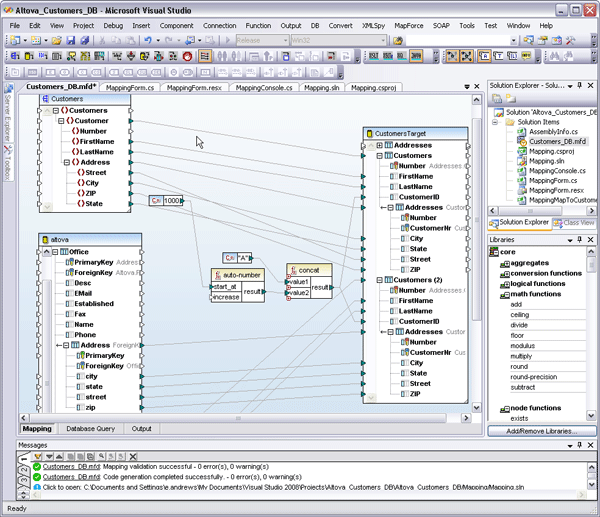 MapForce supports complex data mapping scenarios with multiple sources and targets and advanced data processing functions. Transformations can easily be automated via code generation in C#, C++, or Java, or the command line. Full integration with Visual Studio and Eclipse also makes this an ideal development tool for working in large-scale enterprise projects – without the heavy price tag. This gives developers a flexible and agile middleware component that can work in virtually any service-based architecture. The ability to integrate disparate data in on-the-fly is a key requirement in real-world enterprise and cross-enterprise systems where legacy systems and other less flexible formats co-exist with XML and other modern, interoperable standards.
MapForce supports complex data mapping scenarios with multiple sources and targets and advanced data processing functions. Transformations can easily be automated via code generation in C#, C++, or Java, or the command line. Full integration with Visual Studio and Eclipse also makes this an ideal development tool for working in large-scale enterprise projects – without the heavy price tag. This gives developers a flexible and agile middleware component that can work in virtually any service-based architecture. The ability to integrate disparate data in on-the-fly is a key requirement in real-world enterprise and cross-enterprise systems where legacy systems and other less flexible formats co-exist with XML and other modern, interoperable standards.
Database Management
Even in the rapidly evolving semantics-driven macrocosm that is Web 2.0, most companies still use one or more relational databases to store and manage their internal data assets. The Altova MissionKit supports working with the most prevalent of these systems (see listing below) in a wide variety of different ways. Database support is offered in XMLSpy, MapForce, StyleVision, and, of course, DatabaseSpy.
- Microsoft® SQL Server® 2000, 2005, 2008
- IBM DB2® 8, 9
- IBM DB2 for iSeries® v5.4
- IBM DB2 for zSeries® 8, 9
- Oracle® 9i, 10g, 11g
- Sybase® 12
- MySQL® 4, 5
- PostgreSQL 8
- Microsoft Access™ 2003, 2007
DatabaseSpy is a multi-database query, editing, design, and comparison tool that allows users to connect directly to all major databases and edit data and design structure in a graphical user interface with features like table browsing, data editing, SQL auto-completion entry helpers, visual table design, content diff/merging, and multiple export formats. In a service-based architecture, the ability to compare and merge data directly in its native database format is an enormous asset to developers who need to locate changes, migrate differences, or synchronize versions of database tables across test and live environments. 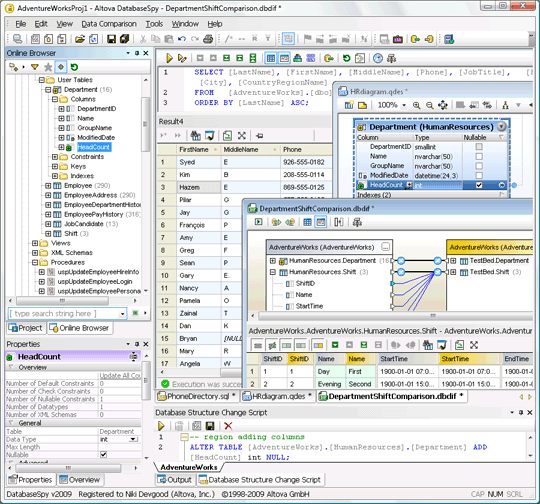 As a component of the MissionKit, DatabaseSpy gives disparate groups within organizations the flexibility to work with data from multiple databases in one central interface simultaneously. Whether this data is eventually integrated into other systems or applications or lives permanently in the database, DatabaseSpy provides a simple and flexible solution to managing and maintaining massive data stores.
As a component of the MissionKit, DatabaseSpy gives disparate groups within organizations the flexibility to work with data from multiple databases in one central interface simultaneously. Whether this data is eventually integrated into other systems or applications or lives permanently in the database, DatabaseSpy provides a simple and flexible solution to managing and maintaining massive data stores.
Single Source Publishing
In today’s world of highly automated data transfer and management, it is still necessary for human readers to ultimately consume the data in some format or other. Of course, the problem that organizations often run into is what format to publish to. XML and single source publishing have revolutionized content management, document exchange, and even multilingual communications by separating content structure from appearance. An XML-based documentation system can greatly reduce costs through facilitating ease of conversion for delivery to many different data formats and types of applications. The single source concept ensures that workflow processes (i.e., conversion, edits, etc.) do not have to be repeated or reworked – that all content in the repository requires only minimal restructuring and promotion before being loaded to respective applications for delivery. Altova StyleVision is a graphical stylesheet design tool that enables users to easily apply single source publishing to XML, XBRL, and database content, without having any affect on the source data. In this way, companies can create reusable template designs for data that can then be rendered automatically in HTML, RTF, PDF, Microsoft Word 2007, and even an Authentic e-Form for immediate publication to any conceivable medium without any process disruption – resulting in the presentation of accurate, consistent, and standardized information in real-time. 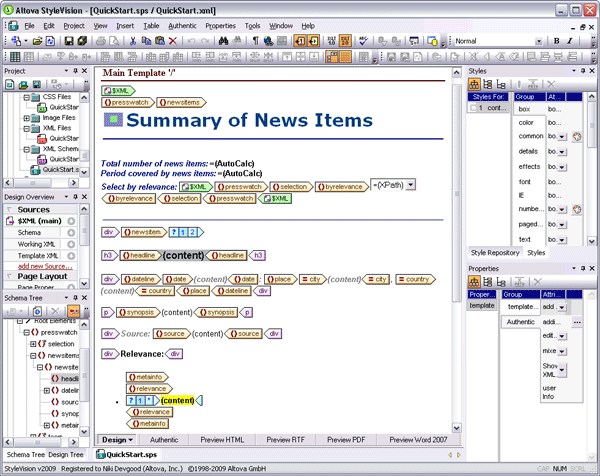 Single source publishing gives organizations the ability to add a human component to their highly automated data processing workflows, enabling them to view transmission reports at any stage. For example, in a world where compliance management plays such a large role in day to day enterprise operations, StyleVision can be integrated into any SOA to provide a sort of visual audit trail for manually reviewing XML, XBRL, and database transactions. StyleVision’s template-based approach to stylesheet design makes it an ideal addition to a distributed development environment, where repeatable processes are an integral part of the system’s overall efficiency.
Single source publishing gives organizations the ability to add a human component to their highly automated data processing workflows, enabling them to view transmission reports at any stage. For example, in a world where compliance management plays such a large role in day to day enterprise operations, StyleVision can be integrated into any SOA to provide a sort of visual audit trail for manually reviewing XML, XBRL, and database transactions. StyleVision’s template-based approach to stylesheet design makes it an ideal addition to a distributed development environment, where repeatable processes are an integral part of the system’s overall efficiency.
Conclusions
Financial downturns can make investing in technology a difficult decision. However, forward-thinking organizations will find that focusing on restructuring the legacy assets they already have in place, automating internal processes, and adding virtualization layer to their application infrastructure can lead to increases in efficiency, speed, and potentially enormous ROI. The Altova MissionKit gives businesses all of the tools that they need to augment their enterprise architecture with iterative, process-driven solutions that will recover costs through the reuse of current assets and the ability to deliver Web-driven automation within and across organizations on a global scale. The MissionKit is a highly affordable solution that offers developers, software architects, and IT users all of the tools they need to build flexible and powerful technology solutions and efficiencies that advance component-based service-oriented infrastructure – without breaking the budget.
Visit Altova at Oracle OpenWorld
HubKey Case Study
Overview HubKey is a technology company offering e-commerce solutions and services to small and mid-sized organizations. Their flagship product, ILXA, is a hosted application that uses the document and workflow management capabilities of Microsoft Sharepoint, combined with the power and flexibility of Altova MapForce and XMLSpy, to deliver a scalable, end-to-end, business-to-business (B2B) solution for outsourced EDI. ILXA builds an intuitive user interface and superior content management controls and functionality around e-commerce/EDI data sources, giving customers the freedom to quickly and accurately process electronic transactions without the need for costly software and hardware systems. The Challenge The HubKey team wanted to build a comprehensive EDI management and translation system that would give their clients the ability to track their EDI transactions across a customized workflow and also transform the messages into virtually any other data format. EDI systems are required to handle a large and constant flow of transactions going back and forth between trading partners. While the actual volume of the data being transmitted is often very small, the amount of individual communications can be overwhelming. HubKey ILXA contains the chaos of EDI automation by giving organizations the ability to view and manage tasks and processes in batches or on-the-fly. Recognizing an increasing demand for B2B integration systems that comply with both EDI and XML, HubKey decided to build a platform that had powerful support for both data formats and could generate application code to automate these translations. Complex EDI-XML and XML-EDI mappings would run behind-the-scenes, but users would be able to access these mappings, as well as the raw data, for quality assurance and error fixing. The Solution HubKey ILXA is a hosted e-commerce solution that gives non-technical end users the ability to seamlessly manage their EDI transactions without being exposed to complex data syntax. To easily manage the document workflow, HubKey chose to build their system on top of the Sharepoint platform, creating a customizable .NET application with advanced functionality for a collaborative workflow environment. The ILXA system draws upon the versatility and quality control capabilities of XML, with EDI-XML conversion powered by Altova MapForce. The end result is sophisticated translation software combined with validation and workflow management capabilities, all in one easy-to-use system.
The Results ILXA breaks down the barriers to costly EDI implementation, giving organizations an affordable, flexible, and reliable alternative to fully outsourced solutions through a modern, Web-enabled, component-based application. By combining content management functionality with age-old e-commerce business process requirements, HubKey is able to offer its customers a centralized EDI management application with resources and personalized services customized to meet any level of e-commerce data expertise. Altova MapForce and XMLSpy provide the translation and XML structure behind-the-scenes, but are also available to more technical users to make adjustments and confirmations at the source. This gives HubKey the ability to offer a flexible and changeable solution to their end users, giving them the power to decide upon hands-on EDI management, or an assisted solution that still falls within their budget. Find out how MapForce and XMLSpy can add functionality to your business applications. Download a fully functional free trial of the Altova MissionKit today!
NYC & Company Case Study
Overview NYC & Company is the official marketing, tourism and partnership organization for the five boroughs of New York City. Its mission is to maximize travel and tourism opportunities, build economic prosperity, and spread the dynamic image of New York City around the world. In 2008-2009, the company initiated a major rebranding, redefining their Web presence and launching an interactive multi-media center in Midtown Manhattan. At the center of this transformation, NYC & Company used development tools from the Altova MissionKit – UModel, DiffDog, DatabaseSpy, and XMLSpy. The NYC & Company Web site and Information Center was created together with online powerhouses as Google and Travelocity, reservation sites like Open Table, content providers Time Out, Greenopia.com, the New York City Department of Cultural Affairs, and more. The Challenge As the single organization responsible for meeting the marketing and tourism needs of the city of New York, NYC & Company has been tasked with meeting Mayor Bloomberg’s January 2006 State of the City goal of luring 50 million visitors by the year 2015 – up from an estimated 43 million in 2006. A large part of the effort behind this push would be manifested in a general Web site rebrand/redesign coupled with the creation of an interactive visitor center. NYC & Company chose to use existing tools and technologies as much as possible, leveraging their ColdFusion Web site architecture, the Eclipse software development platform, a SQL Server 2005 backend, and the Altova MissionKit. A new content management system was also implemented to manage the large amounts of data and associated workflow. The Solution The NYC & Company Web site redesign included a migration from nycvisit.com, which followed a typical convention and visitor bureau site structure, to the much more animated and multi-faceted nycgo.com, a design that promotes the dynamic nature of the resources available and of the city itself. nycvisit.com on 26 February 2008
nycvisit.com on 26 February 2008  nycgo.com on 22 May 2009 UML Modeling The new design components were drawn out as a UML class diagram, expanding on the data model that was created for the live Web site. NYC & Company used Altova UModel to map out the physical structure of nycgo.com, importing their XML Schema definition to ensure adherence to formatting rules. The class diagram was used to represent the new Web site structure at a high level, and to model the objects that needed to be built into NYC & Company’s content management system (CMS). UML design in UModel also enabled the company to generate documentation so that the developers could share the UI design with those not familiar with the intricacies of UML.
nycgo.com on 22 May 2009 UML Modeling The new design components were drawn out as a UML class diagram, expanding on the data model that was created for the live Web site. NYC & Company used Altova UModel to map out the physical structure of nycgo.com, importing their XML Schema definition to ensure adherence to formatting rules. The class diagram was used to represent the new Web site structure at a high level, and to model the objects that needed to be built into NYC & Company’s content management system (CMS). UML design in UModel also enabled the company to generate documentation so that the developers could share the UI design with those not familiar with the intricacies of UML.  UModel UML Class Diagram of the nycgo Web site NYC & Company then worked with third party design vendor, HUGE, Inc., to further analyze the UML wire frames and predict user interaction scenarios for the nycgo Web site. Dynamic code was then delivered in JSP, implemented on JRun then subsequently converted to ColdFusion. Code Differencing NYC & Company chose to migrate their JSP templates to ColdFusion 8 for its rapid application development capabilities, rich feature set, and intrinsic simplicity. DiffDog, Altova’s diff/merge tool, was an integral part of the development process, helping the development team to ensure that the ColdFusion code was in line with the original JSP. NYC & Company could easily recognize and reconcile any crucial differences using DiffDog’s straightforward text comparison interface.
UModel UML Class Diagram of the nycgo Web site NYC & Company then worked with third party design vendor, HUGE, Inc., to further analyze the UML wire frames and predict user interaction scenarios for the nycgo Web site. Dynamic code was then delivered in JSP, implemented on JRun then subsequently converted to ColdFusion. Code Differencing NYC & Company chose to migrate their JSP templates to ColdFusion 8 for its rapid application development capabilities, rich feature set, and intrinsic simplicity. DiffDog, Altova’s diff/merge tool, was an integral part of the development process, helping the development team to ensure that the ColdFusion code was in line with the original JSP. NYC & Company could easily recognize and reconcile any crucial differences using DiffDog’s straightforward text comparison interface.  JSP/CFM code differencing in DiffDog Database Migration As part of their rebranding effort, NYC & Company successfully migrated their data from SQL Server 2000 to SQL Server 2005. NYC & Company used Altova DatabaseSpy to connect to the database, structure queries, and for database analysis. They also use the integrated SQL Editor to test their more complex SQL queries. This enabled them to do their database management and testing in-house, with non-technical and even non-DBA team members assembling complex SQL scripts with features such as auto-completion, syntax color coding, automatic formatting, and refactoring. Building Out the Content Management System NYC & Company used a third party CMS to manage workflow and collaboration for newly designed the Web site. The CMS was also modified to output XML feeds. Additionally, content sourced from NYC & Company’s partners was validated against an XML Schema and then imported into the CMS. Every night, a scheduled task is initiated that delivers the formatted XML feeds to the interactive data center. XMLSpy, Altova’s XML editor, provides NYC & Company with all of its XML editing needs – from validating and saving content, to managing and manipulating it as part of an integrated workflow. Real-time XML Feeds The XML feeds that are available on the nycgo Web site, and the interactive wall kiosks and tables at the Information Center are taken from data submitted by NYC & Company’s numerous content partners and provide real-time information about attractions and events all around the city. Once accessed, the information can be transferred to any mobile device via SMS. The walls display touch-screen FAQ stations that inform visitors about top New York City attractions and provide other useful information like how to tip a doorman, places to exchange currency, etc. in English and nine other languages. Users can also buy MetroCards and tickets to exhibits and other popular events.
JSP/CFM code differencing in DiffDog Database Migration As part of their rebranding effort, NYC & Company successfully migrated their data from SQL Server 2000 to SQL Server 2005. NYC & Company used Altova DatabaseSpy to connect to the database, structure queries, and for database analysis. They also use the integrated SQL Editor to test their more complex SQL queries. This enabled them to do their database management and testing in-house, with non-technical and even non-DBA team members assembling complex SQL scripts with features such as auto-completion, syntax color coding, automatic formatting, and refactoring. Building Out the Content Management System NYC & Company used a third party CMS to manage workflow and collaboration for newly designed the Web site. The CMS was also modified to output XML feeds. Additionally, content sourced from NYC & Company’s partners was validated against an XML Schema and then imported into the CMS. Every night, a scheduled task is initiated that delivers the formatted XML feeds to the interactive data center. XMLSpy, Altova’s XML editor, provides NYC & Company with all of its XML editing needs – from validating and saving content, to managing and manipulating it as part of an integrated workflow. Real-time XML Feeds The XML feeds that are available on the nycgo Web site, and the interactive wall kiosks and tables at the Information Center are taken from data submitted by NYC & Company’s numerous content partners and provide real-time information about attractions and events all around the city. Once accessed, the information can be transferred to any mobile device via SMS. The walls display touch-screen FAQ stations that inform visitors about top New York City attractions and provide other useful information like how to tip a doorman, places to exchange currency, etc. in English and nine other languages. Users can also buy MetroCards and tickets to exhibits and other popular events.  The same real-time data is also fed to interactive tables, where visitors place a “puck” on a Google map of the city to select their area of interest. They then click on a category (e.g., dining, entertainment, etc.) to get more information.
The same real-time data is also fed to interactive tables, where visitors place a “puck” on a Google map of the city to select their area of interest. They then click on a category (e.g., dining, entertainment, etc.) to get more information.  The Results NYC & Company offers the latest in travel and tourism to New York City’s visitors, which number well over 40 million in any given year and offers a wealth of new experiences and up-to-date information to adventurous locals. The innovative new Web site design and interactive exploration center pulls together the latest in hardware, software, and data management technologies to showcase every aspect of this multi-faceted city to tourists from all walks of life and with all sorts of interests. NYC & Company was able to leverage the Altova MissionKit to manage large amounts of disparate data from a variety of different sources -from the preliminary UML modeling, to code differencing, database management, and XML editing. Find out how the Altova MissionKit can help with the end-to-end management of all of your data assets. Download a fully functional free trial of the Altova MissionKit today!
The Results NYC & Company offers the latest in travel and tourism to New York City’s visitors, which number well over 40 million in any given year and offers a wealth of new experiences and up-to-date information to adventurous locals. The innovative new Web site design and interactive exploration center pulls together the latest in hardware, software, and data management technologies to showcase every aspect of this multi-faceted city to tourists from all walks of life and with all sorts of interests. NYC & Company was able to leverage the Altova MissionKit to manage large amounts of disparate data from a variety of different sources -from the preliminary UML modeling, to code differencing, database management, and XML editing. Find out how the Altova MissionKit can help with the end-to-end management of all of your data assets. Download a fully functional free trial of the Altova MissionKit today!
New Online Training – XMLSpy XML Editor
The Altova Online Training team is very excited to have just launched the much-anticipated first module in the XMLSpy training course! XMLSpy Module 1* provides an introduction to XML and the XMLSpy XML editor: In this beginner-level module, students start with an overview of XML, including the anatomy of XML documents and schemas. After a brief tour of the XMLSpy user interface, you’ll create an XML Schema and walk through the steps of defining a namespace, creating a content model, adding elements, configuring schema views, and generating sample XML files and schema documentation. Then it’s time to create an XML document based on the schema. By the end of this module, you will be able to enter data in XMLSpy’s grid view and text view, perform well-formedness and validity checks, add new elements, and modify your schema while working on our XML document. Detailed tutorials walk you step-by-step through each task, and you can test what you’ve learned using the interactive quizzes for each chapter. Check out the free XMLSpy training module* now, or visit the Altova Online Training page for a complete list of available training topics, including MapForce, StyleVision, XBRL, and more. All Altova Online Training courses are available on-demand and free-of-charge. *See Altova Online Training System Requirements for supported browsers, etc.
In this beginner-level module, students start with an overview of XML, including the anatomy of XML documents and schemas. After a brief tour of the XMLSpy user interface, you’ll create an XML Schema and walk through the steps of defining a namespace, creating a content model, adding elements, configuring schema views, and generating sample XML files and schema documentation. Then it’s time to create an XML document based on the schema. By the end of this module, you will be able to enter data in XMLSpy’s grid view and text view, perform well-formedness and validity checks, add new elements, and modify your schema while working on our XML document. Detailed tutorials walk you step-by-step through each task, and you can test what you’ve learned using the interactive quizzes for each chapter. Check out the free XMLSpy training module* now, or visit the Altova Online Training page for a complete list of available training topics, including MapForce, StyleVision, XBRL, and more. All Altova Online Training courses are available on-demand and free-of-charge. *See Altova Online Training System Requirements for supported browsers, etc.
XML & Digital Textbooks
Last Sunday’s New York Times had an interesting article on the front page about digital textbooks for the K-12 market. The piece was undoubtedly partially inspired by Governor Arnold Schwarzenegger’s (he’s from California by the way) recently announced initiative that will replace some high school textbooks with digital versions. In fact, compared to standard printed texts, digital textbooks:
And so XML will finally have a chance to truly demonstrate its power in the K-12 market. For my part, I cannot think of a better example of the efficiencies of XML publishing than for education. Certainly most, if not all, of the major educational publishers are already using XML workflows internally because of benefits like validation, single source publishing, amenability to standards and metadata tagging, etc. XML also gives publishers the ability to easily manage multi-dimensional educational content. Educational content, like textbooks and other learning materials, is usually structured around a fairly simple content model using word forms such as titles, paragraphs, quotes, etc. The second dimension of the content is contextual information – footnotes, glossary terms, highlighting items – anything that may be necessary to target a specific audience. For instance, if a piece of content is to be included in a sixth grade textbook it would have different markup than if it were to be used for an eighth grade classroom. The third dimension of K-12 educational content is the standards dimension. Standards are in most cases on the state level and are used to ensure that teachers know exactly what topics they are teaching in a particular piece of the content, ensuring they are covering the complete set of standards for state aptitude tests, like the MCAS. The standards dimension itself has the potential for further layering as content producers adopt their own standards to guide teachers to other relevant standards and topics that the content is aligned to. XML is particularly well-suited to digital publishing of educational content for its ability to easily separate or layer these dimensions and repurpose it in nearly unlimited ways without the need for rekeying information. For example, one company in the article, CK-12 Foundation, develops free “flexbooks” that can be customized to correlate with state standards. Without XML, this would be a nearly (if not completely) impossible undertaking – with XML you can use many of the existing XML content creation tools to streamline the process. So what has taken so long for the K-12 market to embrace XML-enabled digital learning materials? Well, it appears that the issue is an economical one. We still live in a country where many students do not have access to a computer, and few school districts have the means to provide them. Perhaps in the near future there will be a solution for this problem – and perhaps, just perhaps, California has just taken the first steps to lead us in the right direction. So, where does Altova fit into this equation? Well, the Altova MissionKit offers support for intelligent XML content creation and editing for both technical and non-technical users. These tools give educational publishers and other content contributors the ability to work with structured XML content in a comfortable atmosphere, with easy-to-use interfaces, entry-helpers, drag and drop functionality, and a wide variety of options that make working in a team environment a flexible and even seamless process. Visit the Altova website to read more about the MissionKit – or download a free 30-day trial today!
Recent Industry Awards
The Industry Has Spoken… For us at Altova, being recognized by our industry peers is an honor and something we are proud of and want to share with all of you – our current and future customers. This summer Altova was named to both the 2009 SD Times 100 and Visual Studio Magazine Readers’ Choice Awards. Altova was named to the SD Times 100 list in the ‘Tools & IDEs’ category as a leader and innovator in the software development industry. Alan Zeichick, editorial director of SD Times magazine, said, “The software development industry has always been led by innovation, and that’s true even in today’s challenging economic climate. When choosing the 2009 SD Times 100 winners, we carefully considered each organization’s products and services, reputation with enterprise development managers, and the new ideas and thought leadership that it has brought to the industry. Thanks to companies like Altova, the art of software development continues to advance at a rapid pace.”
Altova was named to the SD Times 100 list in the ‘Tools & IDEs’ category as a leader and innovator in the software development industry. Alan Zeichick, editorial director of SD Times magazine, said, “The software development industry has always been led by innovation, and that’s true even in today’s challenging economic climate. When choosing the 2009 SD Times 100 winners, we carefully considered each organization’s products and services, reputation with enterprise development managers, and the new ideas and thought leadership that it has brought to the industry. Thanks to companies like Altova, the art of software development continues to advance at a rapid pace.”  And it was the Altova XMLSpy 2009 XML editor that was recognized for excellence with a 2009 Readers’ Choice Award from Visual Studio Magazine. The winners were chosen by Visual Studio Magazine’s readers and honor excellent software in 23 development categories. Altova XMLSpy was named in the category of ‘Web Design and Development Tools’. Michael Desmond, Visual Studio Magazine editor-in-chief and editorial director of the developer media group at 1105 Media, said, "When it comes to judging the value and capability of developer tools, you won’t find a savvier audience than Visual Studio Magazine readers. These are committed developers — demanding professionals who work with code every day and have a deep appreciation for the tools they rely on. "This isn’t a popularity contest," Desmond continued. "A product that earns a VSM Readers’ Choice Award has earned the respect and loyalty, over time, of VSM readers, some of the most demanding users on the planet. I commend all the Readers’ Choice Award winners. Visual Studio Magazine readers have put your product on top.” Check out what the industry is buzzing about and download a free 30-day trial of the Altova MissionKit that includes our full line of XML, database, and UML tools!
And it was the Altova XMLSpy 2009 XML editor that was recognized for excellence with a 2009 Readers’ Choice Award from Visual Studio Magazine. The winners were chosen by Visual Studio Magazine’s readers and honor excellent software in 23 development categories. Altova XMLSpy was named in the category of ‘Web Design and Development Tools’. Michael Desmond, Visual Studio Magazine editor-in-chief and editorial director of the developer media group at 1105 Media, said, "When it comes to judging the value and capability of developer tools, you won’t find a savvier audience than Visual Studio Magazine readers. These are committed developers — demanding professionals who work with code every day and have a deep appreciation for the tools they rely on. "This isn’t a popularity contest," Desmond continued. "A product that earns a VSM Readers’ Choice Award has earned the respect and loyalty, over time, of VSM readers, some of the most demanding users on the planet. I commend all the Readers’ Choice Award winners. Visual Studio Magazine readers have put your product on top.” Check out what the industry is buzzing about and download a free 30-day trial of the Altova MissionKit that includes our full line of XML, database, and UML tools!
Altova's Commitment to Renewable Energy
XBRL Glossary
The biggest hurdle for a lot of people (myself included) when they first start looking at XBRL is the vocabulary used in the specification. There is, of course, some overlap with terminology from the XML and business reporting worlds – handy for the handful of you with a background in both – but some of the terms are entirely new and sometimes even a little cryptic (if you don’t believe me, try looking up hypercube on Wolfram for a bit of fun). Altova has published a comprehensive XBRL glossary (many thanks to Neal Hannon and Eric Cohen for their comments/suggestions) that we hope will clear some of the fog. So hopefully the next time you run headlong into a hypercube, you will feel safe knowing that has, at least in the context of XBRL, nothing to do with it.
has, at least in the context of XBRL, nothing to do with it.
New XBRL Video
We recently posted a new, five-minute XBRL Overview video on YouTube! Please check it out and let us know what you think!
DiffDog Reports for Service
A recent message on Twitter asked whether DiffDog can create a differences report. The short answer is yes! In addition to its renowned directory compare and merge, file compare and merge, database compare and merge, and XML diff merge functionality, Altova DiffDog can create differences reports for directory comparisons and for file comparisons. After you select the directories or files and the compare options you want to apply, you can create a report file by choosing Export differences from the DiffDog File menu. This opens a Save File dialog that lets you choose to create the diff report in text format or as an XML file. Text format reports follow the well-accepted Unix diff style. In the directory comparison example report below, the < character indicates a file that exists only on the left side, > indicates a file exists only on the right, and ! signifies file names that occur in both directories with unequal content.
This opens a Save File dialog that lets you choose to create the diff report in text format or as an XML file. Text format reports follow the well-accepted Unix diff style. In the directory comparison example report below, the < character indicates a file that exists only on the left side, > indicates a file exists only on the right, and ! signifies file names that occur in both directories with unequal content.  Report files in XML format are human-readable with descriptive element names and record the the comparison mode and the paths of the directories compared:
Report files in XML format are human-readable with descriptive element names and record the the comparison mode and the paths of the directories compared:  You can also use the DiffDog directory report functionality to create diff report files for comparisons of Zip archives or OOXML documents. Developers and other project stakeholders often want to keep a record of changes to source code files in a software project. DiffDog can create diff reports for all comparisons of text-based files, including source code files. DiffDog can even create detailed XML-aware reports for XML file comparisons. The illustration below shows two versions of a Java source code file:
You can also use the DiffDog directory report functionality to create diff report files for comparisons of Zip archives or OOXML documents. Developers and other project stakeholders often want to keep a record of changes to source code files in a software project. DiffDog can create diff reports for all comparisons of text-based files, including source code files. DiffDog can even create detailed XML-aware reports for XML file comparisons. The illustration below shows two versions of a Java source code file:  If you read our earlier series on Reverse Engineering an Existing App with Altova UModel, you may recognize this code. Lines 8 and 9 on the left introduce a new class property called fee that is set to an initial value of 2. Here is the file compare report for the differences shown above in text format:
If you read our earlier series on Reverse Engineering an Existing App with Altova UModel, you may recognize this code. Lines 8 and 9 on the left introduce a new class property called fee that is set to an initial value of 2. Here is the file compare report for the differences shown above in text format:  And the XML version of the report for the same portion of the files:
And the XML version of the report for the same portion of the files:  You can even execute DiffDog from a command line to create differences reports automatically. Here is an example of a short batch file that compares the same two directories from our GUI example and writes the output in XML in a file named diff_1.xml:
You can even execute DiffDog from a command line to create differences reports automatically. Here is an example of a short batch file that compares the same two directories from our GUI example and writes the output in XML in a file named diff_1.xml:  The DiffDog Help system includes extensive documentation on all the command line options, including specific instructions on how to integrate DiffDog with 19 popular source control systems. If DiffDog report files get your tail wagging, don’t just Twitter about it! Click here to download a free 30-day trial of Altova DiffDog.
The DiffDog Help system includes extensive documentation on all the command line options, including specific instructions on how to integrate DiffDog with 19 popular source control systems. If DiffDog report files get your tail wagging, don’t just Twitter about it! Click here to download a free 30-day trial of Altova DiffDog.
Adding z-segments to HL7 Mapping Components
When mapping HL7 EDI components, it is often necessary to add locally-defined information, or z-segments, to accommodate additional fields not included in the standard. Following is a simple walkthrough that will demonstrate how to add z-segments to the HL7 configuration files that are available as a free download with MapForce. In the example below we will be adding a ZLR segment to an HL7 2.3 Observation Results Unsolicited (ORU) message. The ZLR segment is commonly used for adding additional information for legacy laboratory-based reporting. ZLR attributes are provided below:
The ZLR segment must follow each OBR (Observation Request) segment, and there can only be one ZLR per OBR. 1. Go to C:Program FilesAltovaMapForce2009MapForceEDIHL7.v230 to access the MapForce configuration files for HL7 version 2.3. 2. First, locate the message configuration file in question, ORU_R01, and open it in XMLSpy – or any text editor.[i] Add a ZLR just below OBR. 3. Save this file as ORU_R01_ZLR (or any unique name you choose). 4. Now open the EDI collection file and add the new message to the list.[i]
3. Save this file as ORU_R01_ZLR (or any unique name you choose). 4. Now open the EDI collection file and add the new message to the list.[i]  5. Next, simply open the HL7 SEGMENT file to add the segment details to the GENERATE DATA section as provided above.[i]
5. Next, simply open the HL7 SEGMENT file to add the segment details to the GENERATE DATA section as provided above.[i]  6. Finally, scroll down to the GENERATE SEGMENTS section and add the following:
6. Finally, scroll down to the GENERATE SEGMENTS section and add the following:  7. Now, let’s access our newly customized HL7 EDI mapping component in MapForce. Open MapForce and choose Insert > EDI. In the Browse EDI collections dialog, select HL7.v230 and scroll down to select ORU_R01_ZLR.
7. Now, let’s access our newly customized HL7 EDI mapping component in MapForce. Open MapForce and choose Insert > EDI. In the Browse EDI collections dialog, select HL7.v230 and scroll down to select ORU_R01_ZLR.  Press OK to insert. 8. Your new mapping component will appear in the MapForce design pane with the new ZLR segment included.
Press OK to insert. 8. Your new mapping component will appear in the MapForce design pane with the new ZLR segment included.  Now you can complete your data integration design by inserting another source or target data structure(s) and dragging lines to connect nodes. MapForce supports mapping to/from XML, databases, flat files, EDI, XBRL, and Web services. [i] If you are working in XP, you will have to unclick “read-only” in the Properties dialog. Vista users will need to copy the file to another location before editing – you can then copy the file back to the appropriate HL7 collection directory. For more information about mapping HL7 and other EDI formats, please see the MapForce feature pages – or download a 30-day free trial of MapForce today!
Now you can complete your data integration design by inserting another source or target data structure(s) and dragging lines to connect nodes. MapForce supports mapping to/from XML, databases, flat files, EDI, XBRL, and Web services. [i] If you are working in XP, you will have to unclick “read-only” in the Properties dialog. Vista users will need to copy the file to another location before editing – you can then copy the file back to the appropriate HL7 collection directory. For more information about mapping HL7 and other EDI formats, please see the MapForce feature pages – or download a 30-day free trial of MapForce today!
XBRL Training Course Updated
We have recently updated Altova’s MissionKit XBRL online training course, which debuted in May, to make the XBRL filing process as accessible to accountants and financial professionals as it is to more technical users. The new course includes easily identifiable “Accountant’s Notes” to make key XBRL concepts more transferable for those with an accounting background. An updated glossary also includes more accounting-friendly definitions of XBRL concepts to help you ease into the XBRL filing process. Access Altova’s MissionKit XBRL course now. (Yes, it’s free!)
XBRL… so much more than compliance
Having recently returned from a short visit to the 19th XBRL International Conference in Paris, I can’t help but think that many organizations are simply missing the point – and that perhaps the SEC mandate is partly to blame for this. One would think (well, I thought, anyway) that in the year following the issuance of XBRL reporting requirements by the world’s largest economy, that this conference would be overflowing with company representatives eager to learn more about how, and best of all, why they should mark up their financial data in XBRL. But alas, this was not the case. I can only guess that the meager attendee numbers – especially from the United States – have to do with the fact that organizations are still viewing XBRL as singularly a compliance issue and are continuing to outsource the “tagging” of their financial statements to financial printers or other EDGAR filing entities. So, is XBRL a compliance issue? Well, of course it is, but it is much more than that. I can tell you this for certain because I work for Altova and we simply do not focus on compliance software. We build tools that help businesses to maximize the efficiency of their internal processes with an eye toward reducing the overall time and cost of the data management workflow. And this is well within the realm of possibility for any company using XBRL – but it means taking a proactive look at the way you manage your data. “Tagging” implies that financial statements are drawn up in the traditional manner in a spreadsheet or accounting program and then retroactively and meticulously marked up with XBRL tags to make them compliant. Ugh… no wonder compliance has such an ugly ring to it! Haven’t we all got enough work to do? And wait, isn’t this just adding one manual task on top of another – doubling the chances of human error? I’m not sure exactly when this word “tagging” became so popular for describing XBRL implementation, but all it has done is succeeded in oversimplifying something that was not very complicated in the first place (admittedly, it was probably coined by someone in the marketing tribe – of which I’m a member). Anyway, let’s put this idea of tagging aside and see if we can come up with something a little more dangerous. Let’s say that all of your company financial data resides in some sort of backend repository, a database, accounting/ERP system, XML, or even some combination of these. What if you could simply map your data to XBRL in-house instead of having external consultants comb through reports and tag each line item? What if you could even reuse this mapping the next time you had to produce a similar financial report? And what if you could even have your IT department automate your XBRL filing processes?
So, here we have a very quick example of generating XBRL directly from an accounting system – no need for re-keying information, no need to create a set of traditional financial statements, and certainly no need for “tagging”. And best of all, all of this can easily be done in-house and at a fraction of the cost. Now don’t get me wrong, outsourcing could very well have a place in your company’s XBRL implementation. Building an XBRL extension taxonomy, for example, could very well be something that you feel more comfortable leaving to those who have years of experience working with XBRL syntax and other complexities. But putting your organization’s financial data into XBRL… shouldn’t that be left to those who know the data best? For more information on the Altova MissionKit tools for XBRL – which includes support for XBRL mapping and automation, XBRL validation and taxonomy creation, and XBRL rendering – please visit https://www.altova.com/solutions/xbrl-tools.html …or download the Altova MissionKit today!
Altova Tools for IT Professionals – Tell Us Your Story
Part 5 – Analyzing a Legacy Application with Altova UModel
Previously in Part 1, Part 2, Part 3, and Part 4 of this series we applied Altova UModel reverse-engineering functionality to create UML diagrams for an ATM banking simulation application. After analyzing the existing architecture, we planned and implemented a new feature, the withdrawal fee. Even in a reduced size, our updated sequence diagram for the withdrawal transaction clearly represents in graphical form the nested logic structure of the source code.") This morning we happened to run into the ATM product manager at the coffee machine. “You’ve been working on that ATM code for over a month now,” he said. “When am I going to see what you’ve accomplished?” We can take advantage of the UModel Generate Documentation feature to satisfy this request. UModel will automatically create customized documentation for our project in HTML, Microsoft Word, or RTF formats. The Include tab in the Generate Documentation dialog box lets us choose which diagram types to include, and to specify the level of detail for our report by allowing us to expand each diagram element type.
This morning we happened to run into the ATM product manager at the coffee machine. “You’ve been working on that ATM code for over a month now,” he said. “When am I going to see what you’ve accomplished?” We can take advantage of the UModel Generate Documentation feature to satisfy this request. UModel will automatically create customized documentation for our project in HTML, Microsoft Word, or RTF formats. The Include tab in the Generate Documentation dialog box lets us choose which diagram types to include, and to specify the level of detail for our report by allowing us to expand each diagram element type.  For an overview report, we can select all diagram types. We’ll also select class from the Elements list to show further information about the classes in our application. UModel helpfully asks if we want to add elements derived from class as well.
For an overview report, we can select all diagram types. We’ll also select class from the Elements list to show further information about the classes in our application. UModel helpfully asks if we want to add elements derived from class as well.  After we have selected or adjusted other document parameters, including fonts and sizes, UModel generates the report in just a few seconds. At the top of the first page, the report begins with an index of diagrams and a separate index of elements. Each indexed item is hyperlinked to a bookmark in the document.
After we have selected or adjusted other document parameters, including fonts and sizes, UModel generates the report in just a few seconds. At the top of the first page, the report begins with an index of diagrams and a separate index of elements. Each indexed item is hyperlinked to a bookmark in the document.  Regardless which format you choose, the resulting report is fully editable. For instance, we can add a footer that includes page numbers and a tag line recording the document creation date. We can grab the tag line UModel created to create our footer.
Regardless which format you choose, the resulting report is fully editable. For instance, we can add a footer that includes page numbers and a tag line recording the document creation date. We can grab the tag line UModel created to create our footer.  Our completed report contains all the UML diagrams that describe the legacy ATM application, with detailed class diagrams that show the class properties and operations. Additionally, the illustration of each class is accompanied by a hierarchy diagram to show the class relationships, and a list of all the class associations. Later on as our project evolves further, we can easily generate an updated version of the report. We could even take advantage of the UModel command line functionality or the UModel API to automate creation of project documentation, or we could attach the .html version of the report to our developer team wiki. But for now all we have to do is email the report to the ATM product manager. Conclusion We hope you’ve enjoyed following along with this exercise in Analyzing a Legacy Application with Altova UModel. Although we are ending the series here, in the real world there is much more work to do on our ATM application. For instance, the feature to permit users to accept the fee or cancel a withdrawal remains to be implemented. Or, we could update the legacy code with newer Java language constructs such as generics, annotations, and enumerations. If you’re already experienced with UML we hope we’ve shown you a new trick or two. If you are a developer who’s never tried UML, we wanted to give you some of the flavor and benefits of visual software modeling. Either way, if you’re ready to go further on your own project, click here to download a fully-functional free trial of Altova UModel.
Our completed report contains all the UML diagrams that describe the legacy ATM application, with detailed class diagrams that show the class properties and operations. Additionally, the illustration of each class is accompanied by a hierarchy diagram to show the class relationships, and a list of all the class associations. Later on as our project evolves further, we can easily generate an updated version of the report. We could even take advantage of the UModel command line functionality or the UModel API to automate creation of project documentation, or we could attach the .html version of the report to our developer team wiki. But for now all we have to do is email the report to the ATM product manager. Conclusion We hope you’ve enjoyed following along with this exercise in Analyzing a Legacy Application with Altova UModel. Although we are ending the series here, in the real world there is much more work to do on our ATM application. For instance, the feature to permit users to accept the fee or cancel a withdrawal remains to be implemented. Or, we could update the legacy code with newer Java language constructs such as generics, annotations, and enumerations. If you’re already experienced with UML we hope we’ve shown you a new trick or two. If you are a developer who’s never tried UML, we wanted to give you some of the flavor and benefits of visual software modeling. Either way, if you’re ready to go further on your own project, click here to download a fully-functional free trial of Altova UModel.
Java Utopia
Java-powered robots, Java mobile phone apps, Java in the cloud, Java running Neil Young’s ’59 Lincoln, a new T-shirt, and photos with Duke! It can only mean the annual pilgrimage to the Moscone Center in San Francisco for JavaOne. XMLSpy and MapForce feature Java code generation and UModel can both generate and reverse engineer Java code. Of course you can use all the Java code you generate with Altova tools royalty free! Check out this YouTube video:
to see and hear a few highlights of JavaOne 2009 and Altova’s presence there.You can also click here to see an interview with Altova’s Technical Marketing Manager filmed at JavaOne by TechTarget.
Wrycan / NAVSEA Case Study
Overview
The Portsmouth Naval Shipyard in Kittery, Maine, is a division of Naval Sea Systems Command (NAVSEA), the largest of the United States Navy’s five systems commands. They approached Wrycan, an Altova partner focused on content-centric XML expertise, for help converting some of their legacy format technical manuals to XML based on the Navy ETM XML DTD and recreating them as PDFs. The shipyard had been given a mandate to start utilizing XML as their primary data and storage format and needed a low cost and reliable publishing solution that could be easily maintained by their in-house workforce. Wrycan had some experience working with the Altova MissionKit for XML development, as well as a broad expertise in XML technologies including XML, XSL:FO, and DTD. They chose to use XMLSpy, StyleVision, and Authentic as the development tools for this implementation because of their intuitiveness, ease-of-use, and low price tag.
The Challenge
The Portsmouth Naval Shipyard needed to convert about 10,000 pages of content from a legacy format into XML that was conformant to their DTD. This included an automated conversion, manual review and cleanup, and a command line tool to publish the XML back into its original PDF format. As with any large publishing and conversion operation, the project required heavy QA review post-conversion, much of which could be done by non-technical shipyard employees if they had a mechanism to help them interpret and access the XML markup. In addition, because of the relative complexity of the documentation format, which included complicated page layout details such as a variable number of columns per page and different margin widths, callouts interspersed with sections and enumerated lists, as well as many large schematic models, some of which were on foldout pages, the XSL:FO coding promised to present a formidable challenge.
The Solution
Wrycan performed the bulk of the content conversion in-house using custom scripts and some manual processes, along with some technical QA. After the content was converted, Wrycan used StyleVision’s drag and drop design interface to create Authentic e-Forms for editing using the Navy ETM XML DTD as the structural component. Advanced stylesheet functions such as conditional templates and auto-calculations were inserted to facilitate QA and editing workflows. After the content conversion, Wrycan implemented a command line processing tool that includes multiple steps such as:
After the content conversion, Wrycan implemented a command line processing tool that includes multiple steps such as:
For greater flexibility and usability, the Navy technical manuals were divided up into sections including Front Matter, Chapters, Back Matter, and image files. This enabled Wrycan to make certain parts of these files available for reuse. Components that appeared identically in more than one place within the manuals could be segmented so that changes made in one place would iterate throughout the documentation.
Wrycan used XMLSpy, Altova’s full-featured XML editor , to hand-code the advanced XSL:FO that was needed for the manuals. The complexity of the XML and PDF output can be seen in the following examples: Volume source, Front Matter source, Chapter source, and Final document (3.8 MB PDF).
This project required various page sizes within one document, such as a portrait page followed by a foldout 11″ x 17″ landscape page. There are Naval documentation requirements specifying that different page formats have different printing requirements. For example, foldout pages are printed on one side only while other pages are double-sided.
There were also page numbering requirements, such as every chapter must start on an odd numbered page. If this causes a page to be blank, a message indicating that the page was intentionally left blank is placed on the page. These requirements are automatically satisfied by Wrycan’s processing tool.
Wrycan integrated RenderX’s XEP software into the processing pipeline to convert the XSL:FO output, including all images and common content, into one PDF file.
The editing of the content is done with Authentic via Stylevision, which was recently upgraded to the most recent release for more advanced table support and authoring options. Below is a sample screenshot of one of the Authentic e-Forms for WYSIWYG XML editing that was generated for NAVSEA based on the StyleVision stylesheet design.
The Results
The Portsmouth Naval Shipyard now has an XML publishing solution with native XML editing capabilities. They can reproduce their technical manuals in PDF using XML as the content source. They are now ready to move onto the next step, which is implementing a full scale content management system with workflow and custom publishing capabilities. Find out how Altova tools can help with your documentation and publishing challenges. Download a fully functional free trial of the Altova MissionKit today!
Internationalization with the Altova MissionKit
The following post is written by Peter Reynolds, CEO and translation management consultant at TM-Global and Executive Director of Kilgray Translation Technologies. An Irish national based in Warsaw, he holds a BSc and an MBA degree from Open University and is a localization and translation industry veteran. Peter previously worked at Idiom Technologies Inc. — now SDL PLC. As director of the LSP Partner Program at Idiom, Peter was responsible for making its global LSP partners program a successful and innovative venture. Before Idiom, he worked on language technology development for several global localization companies: Lionbridge, Bowne Global Solutions and Berlitz GlobalNET. He managed the Dublin development team responsible for BerlitzIT, Elcano, Freeway 2.0 technology solutions, and internal project and vendor management tools. Peter has been actively involved in the development and promotion of standards (notably XLIFF) for more than ten years, mostly at OASIS. Until 2008 when XLIFF was published, he was secretary of the XLIFF Technical Committee at OASIS and chaired the Translation Web Services TC. He is currently involved in OASIS, TILP as well as being the Irish expert to ISO SC2 and SC4 and training auditors for the EN 15038 standard.
Introduction
Every developer wants his or her applications to be used and hopes they will be very popular. A web application developed in rural Maine USA could easily be used by someone living in the next township or in Malaysia, New Zealand, Germany or Poland. Even if the application is not translated (localized), there are some important differences between how data is represented from one locale to another. The W3C definition of internationalization is “the design and development of a product that is enabled for target audiences that vary in culture, region, or language”. This does not mean that the product has to be translated into the language of the target audience but that it is designed in such a way that the target audience can use the application and understands the way data is presented. The reason for internationalization is to ensure the widest possible audience for your application and to make its translation easier and less costly. This article will introduce you to internationalization and demonstrate how applications can be internationalized using the Altova MissionKit, an integrated suite of XML, database, and UML tools including XMLSpy, StyleVision, MapForce, and others. If you are using tools such as XMLSpy and StyleVision it is very likely that you are already creating internationalized XML applications. The strategy which I suggest is that you try and figure out what target audience your applications are intended for beforehand and implement internationalization accordingly. In this article I will first discuss a strategy for internationalizing XML. I will then introduce the Internationalization Tag Set and examine issues relating to XML internationalization.
Strategy for Internationalizing XML
The first step in planning internationalization is to make an informed decision as to the level of internationalization you require. There may be people in your organization who can help you make this decision, and it would be particularly useful to obtain input from people who live in different countries. The three-level approach presented below should help you decide on the level of internationalization you are going to implement. However, you should remember that you may encounter some problems if your documents or applications are not internationalized, but you will certainly not have the same problems if to ensure that they are fully internationalized. The three levels of internationalizations are:
The software tools in the Altova MissionKit have a lot of functionality which supports internationalization. If you are using these tools you have a very strong basis for creating internationalized XML documents. Unicode is the default encoding for applications created in the XMLSpy XML editor, and I would strongly recommend using this character set.
Internationalization Tag Set
The Internationalization Tag Set (ITS) is recommended by W3C and designed to create XML which is internationalized and can easily be localized. If you are working with XML documents which might be localized, I would recommend using ITS. With this technology you are able to specify which text requires translation, provide instructions for translators and specify the direction of the text. The seven data categories included in the ITS are:
W3C has published a best practices guide for internationalizing XML documents which details how to use ITS. It can be found on their web site at: http://www.w3.org/TR/2007/WD-xml-i18n-bp-20070427/ The specification can be found in this section: http://www.w3.org/TR/2007/REC-its-20070403/ I would strongly recommend you read these documents before proceeding with internationalization.
Internationalization Issues
The following table describes some of the internationalization issues you may come across. This will be followed by a more detailed explanation of these issues and suggestions for how they can be resolved using the Altova MissionKit.
Encoding
All electronic text uses a character coding system where the character is represented by a number. Before the widespread use of Unicode this was one of the most significant internationalization issues. When an application tries to show a character that is not represented in a code page it will appear as garbage text. There were not only problems between different languages but also with characters appearing incorrectly on computers running different operating system. Unicode has solved most of these problems by creating a single code page regardless of platform, program or language. XML uses Unicode as its default code page. Any XML documents you create in XMLSpy will by default have the declaration encoding="UTF-8” If the file has not been created in XMLSpy, you need to ensure that the file is saved as UTF-8. UTF is an acronym for Unicode transformation format, and UTF-8 is a flavor of Unicode that uses 1, 2 or 4 bytes to store characters. It is the most commonly used flavor and is very widely used for XML and the Web. The other versions of Unicode which XMLSpy supports are:
There may be reasons for using default encoding other than UTF-8. To set the default encoding in XMLSpy go to Tools | Options and select the encoding tab.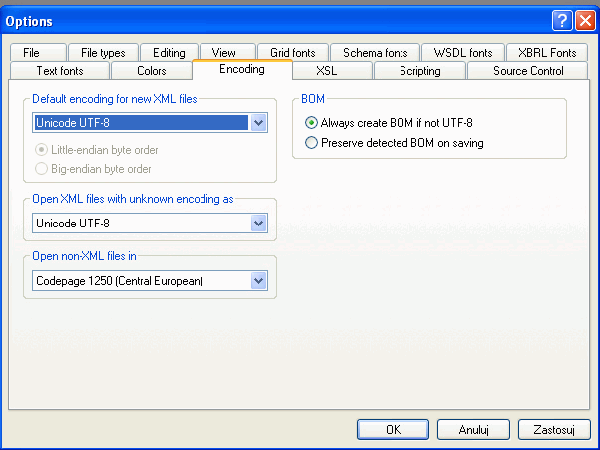 If you want to change the encoding for an individual XML document, open the document in XMLSpy and select File| Encoding.
If you want to change the encoding for an individual XML document, open the document in XMLSpy and select File| Encoding. 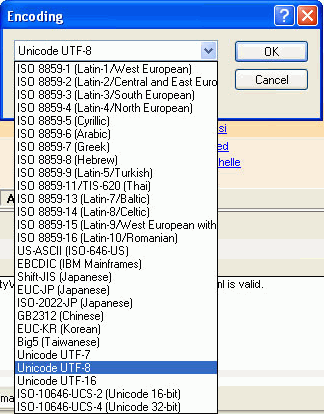
Language
The XML namespace defines xml:lang to identify the language of an XML document. The value for xml:lang must be an ISO language code (ISO 639- 2). If you have an XML document which is written in one language but has a segment in another language you can use xml:lang at the root element to identify the main language of the document and use it at the element where the text in another language is used to identify that language.
Dates
In different countries dates and time are represented in very different ways. Let’s take as an example the date 10/09/08:
The way to deal with this is to use ISO 8601 for specifying date and time within your application. This is a standard way for representing date and time in the format YYYY-MM-DDTHH:MM:SS[±HH:MM] where
You can then use StyleVision to create a style sheet which formats the date in a way suitable to your target audience. StyleVision is a graphical stylesheet design tool that allows drag-and-drop design of XSLT and XSL:FO stylesheets to render XML data in HTML, Microsoft Word, PDF, and other formats. To use the date formatting functionality within StyleVision:
You can also select other date and time formats here. I would strongly recommend using the date picker. In order to insert the date picker, the cursor must be between an xs:date or xs:dateTime node. You then go to Insert on the main menu and Select Insert Date Picker. If the cursor is not between xs:date or xs:dateTime node the Insert Date Picker menu item will be greyed out.
Numbers
Decimals can be preceded by either a point or a comma depending on the locale. There are also differences for how thousands are represented. StyleVision provides functionality where you can format a number for your intended audience:
Money
The issues involving numbers also apply to money, but in addition to this there are different conventions for representing the currency symbol. Some currencies share the same name and symbol, such as the dollar, but the Australian, Canadian and Singaporean dollar are not the same currency, and this should be identifiable. You can deal with the numbers as shown above, but the issue of whether the currency name or symbol should go before or after the number is likely to be dealt with as part of the translation process.
Address
One of the problems faced by customers buying from a foreign company while making an online purchase is that the system does not allow them to enter their address properly. There are many differences, such as the house number being before or after the street name, the order the components of the address are placed and the format of the zip/postal code. CEN (The European Standards Institution) has developed a standard which lists the components of an address, and the UPU (Universal Postal Union) is further developing this to produce a comprehensive list of name and address elements. I would recommend that you ensure that you are getting the data you need for your main target markets but make sure that someone from another country can also enter their address. A drop-down list of countries could be used to ensure that there is error checking when you know certain components of an address are required but does not produce the error for other countries where you do not know the address structure.
Credit Cards
Some US-based web sites will not accept credit cards from outside the US. As a security check they insist on a valid US address. If you want to accept credit card payments and do business with people outside your country, you should check that foreign credit cards will be accepted.
RTL (bidi)
In many languages the text is being read from left to right but this is by no means universal. Arabic and Hebrew are written from right to left. In XML documents this causes further confusion as the XML elements are read from left to right but any text should be read from right to left. The ITS namespace has a direction attribute which can be used to identify which direction should be read. <its:span dir="rtl">متعة الأسماك!</its:span>
Sorting
There are differences in how alphabets are sorted. Some Scandinavian languages have an ‘aa’ character which is usually, but not always, sorted at the end of the alphabet. If you have set the language in your XML document and use xsl:sort for your XSL document then the sorting should work according to the sorting rules for that language. However, you should check that your processor does this as that is not always the case. The example files which come with StyleVision contain examples for sorting. Select StyleVision examples, then the tutorial folder, then sorting and open the file SortingOnTwoTextKeys.sps. To see how the sorting works go to the design view and right click on the member element. Then select the ‘sort by’ option on the context menu. Here you can control how the sorting works for this particular list.
Exclamation and Question Marks
In English, questions and exclamation marks are always at the end of the sentence, while in Spanish this punctuation occurs at the beginning and end of a sentence. This is something which will usually be corrected during the translation process.
Conclusions
Internationalization is an important step in ensuring the widest target audience for your application, and that translation is as cost effect and easy as possible. Your approach to this should be very pragmatic. Time spent up-front sorting out internationalization will result in huge benefits throughout the process and significantly increase marketing potential for your product. The purpose of this article was to present an overview and introduce you to internationalization. There is a lot more useful information available in the references listed below. Tools such as XMLSpy and StyleVision, both of which are included in the Altova MissionKit software suite, go a long way in making the internationalization process for XML documents much easier by providing a lot of in-built support for internationalization. The Internationalization Tag Set from W3C is a very significant innovation which is a great addition to the toolkit available to a developer who wants to build internationalized XML applications. XML is a technology which has had internationalization and translation in mind since its inception. The use of Unicode as the default encoding for XML is very significant and greatly facilitates dealing with any internationalization problems you may come across. The functionality available within the Altova MissionKit, ITS and Unicode are the basis for creating good internationalized applications. Reference The following is a list of useful web sites and other resources providing further information on internationalization: Leading XML tools provider – Altova https://www.altova.com/ . They also offer a free trial of the MissionKit: https://www.altova.com/download. Unicode web site http://www.unicode.org/ Internationalization Tag Set http://www.w3.org/TR/2007/REC-its-20070403/ W3C Best Practices for internationalization http://www.w3.org/TR/2007/WD-xml-i18n-bp-20070427/ Open Tag (Yves Savourel’s) http://www.opentag.com/ Yves Savourel, ‘XML Internationalization and Localization’, a book which is an excellent source of information. More information can be found at: http://www.opentag.com/xmli18nbook.htm The TM-Global research and resource web site publishes a lot of useful articles, opinions and surveys on translation, localization and industry standards http://www.tm-global.com/ Web sites of internationalization guru Tex Texin http://www.xencraft.com/ and http://www.i18nguy.com/ Localization Flow – web site of internationalization experts http://www.locflowtech.com/ Value for money XML-based TEnTs and translation tools are available from companies such as Kilgray Translation Technologies http://www.kilgray.com/
Visit Altova at JavaOne
New XBRL Training Now Available
We’re very excited to have just launched the next free Altova Online Training course: MissionKit XBRL! This comprehensive, five-module course provides an overview of XBRL and the Altova MissionKit for beginning and advanced technical users. After an introduction to XBRL and the XBRL filing process, you will learn to create an extension taxonomy in the XMLSpy XML editor. Then you’ll learn how to get your company’s back-end data into compliant XBRL filing documents using MapForce’s graphical data mapping interface, and explore how to automate this process by generating code in Java, C#, or C++. The final module completes the process and focuses on StyleVision and XBRL report generation. You’ll see how easy it is to create a straightforward XBRL report with drag-and-drop functionality to render XBRL in human-readable formats: HTML, PDF, and MS Word. The XBRL training course includes over 30 instructional videos, and the training is now delivered through Amazon’s S3 cloud services to ensure fast downloads and smooth video. You can even test what you’ve learned using the interactive quizzes for each module. Like all Altova Online Training courses, MissionKit XBRL is available on-demand, so that you can complete the courses as your schedule allows. And did I mention that it’s free? This course is currently in beta, and we’d appreciate your feedback to improve it. Please feel free to comment here or by completing the Altova Training Survey at the end of the course.
Then you’ll learn how to get your company’s back-end data into compliant XBRL filing documents using MapForce’s graphical data mapping interface, and explore how to automate this process by generating code in Java, C#, or C++. The final module completes the process and focuses on StyleVision and XBRL report generation. You’ll see how easy it is to create a straightforward XBRL report with drag-and-drop functionality to render XBRL in human-readable formats: HTML, PDF, and MS Word. The XBRL training course includes over 30 instructional videos, and the training is now delivered through Amazon’s S3 cloud services to ensure fast downloads and smooth video. You can even test what you’ve learned using the interactive quizzes for each module. Like all Altova Online Training courses, MissionKit XBRL is available on-demand, so that you can complete the courses as your schedule allows. And did I mention that it’s free? This course is currently in beta, and we’d appreciate your feedback to improve it. Please feel free to comment here or by completing the Altova Training Survey at the end of the course.
Altova at Microsoft Tech Ed 2009
If you missed Microsoft Tech Ed in Los Angeles last week, check out our latest YouTube video for a quick trip to catch up on some of the sights and sounds of the Partner Exhibition. Our team on the scene reported a strong positive response to the XBRL and HL7 functionality in Version 2009 of the Altova MissionKit and many shout-outs from the floor for individual Altova tools — XMLSpy, MapForce, StyleVision, and UModel are all popular in the developer community. IT professionals commonly use DatabaseSpy and DiffDog to efficiently complete everyday database and differencing tasks.
You can also see a video clip reporting on Altova at Tech Ed at the TechTarget site. Check out the Altova Events page to follow our upcoming show schedule and see where you can meet us live!
New Table Design in StyleVision
v2009 brought a lot of exciting new features to StyleVision, Altova’s graphical stylesheet design tool. Some, like an all-new design for tables and XPath filtering, are welcome byproducts of our support for XBRL and XBRL Dimensions, but still have far reaching uses for working with XML and databases. Let’s take a quick look at StyleVision’s new table design to illustrate what I’m talking about. If you’re already a seasoned StyleVision user, it’s probably already obvious to you that we’ve changed things up a bit. You can now very easily select entire columns or rows for editing. Rearrange, delete, add styles, and even resize using the drag and drop UI or common Windows shortcuts on your keyboard. Of course, any of the designs that you’ve created in a previous version of StyleVision will inherit this functionality as well. For any of you not familiar with StyleVision, it is an award-winning stylesheet design tool and report builder with support for XML, database, and XBRL source content. Using the drag and drop GUI and style entry helpers, you create reusable design templates for output to HTML, RTF, PDF, Word 2007 (OOXML), and Authentic e-Forms. If you chose to take advantage of the cost savings in the Altova MissionKit, you will find that you already have StyleVision on your hard drive and just need to open it up for a test drive. Visit the new features index to view all of the functionality that has been added to StyleVision since your last upgrade or download a free trial of StyleVision 2009 today!
If you’re already a seasoned StyleVision user, it’s probably already obvious to you that we’ve changed things up a bit. You can now very easily select entire columns or rows for editing. Rearrange, delete, add styles, and even resize using the drag and drop UI or common Windows shortcuts on your keyboard. Of course, any of the designs that you’ve created in a previous version of StyleVision will inherit this functionality as well. For any of you not familiar with StyleVision, it is an award-winning stylesheet design tool and report builder with support for XML, database, and XBRL source content. Using the drag and drop GUI and style entry helpers, you create reusable design templates for output to HTML, RTF, PDF, Word 2007 (OOXML), and Authentic e-Forms. If you chose to take advantage of the cost savings in the Altova MissionKit, you will find that you already have StyleVision on your hard drive and just need to open it up for a test drive. Visit the new features index to view all of the functionality that has been added to StyleVision since your last upgrade or download a free trial of StyleVision 2009 today!
Visit Altova at TechEd
Part 4 – Analyzing a Legacy Application with Altova UModel
In Part 1 of this series we imported source code into Altova UModel to create a UML project and we examined a class diagram of our legacy ATM application. In Part 2 we created a series of UML use case diagrams to describe user interactions with the system and we planned an application enhancement to implement a withdrawal fee. In Part 3 we designed a UML state machine diagram to further analyze and document the operation of our system. In this installment we will return to our planned enhancement. We’ve been assigned to implement an ATM withdrawal fee of $2 for withdrawals less than $100 and $4 for withdrawals of $100 or more. In Part 2 we drew a use case diagram to show how users will interact with the new feature: From our original analysis of the object-oriented classes in Part 1, we know our system contains a Withdrawal class, which is the logical place to implement our new feature. We can display a new class diagram for the Withdrawal class by selecting it in the Model Tree and choosing from the right-click context menu to create a new diagram.
From our original analysis of the object-oriented classes in Part 1, we know our system contains a Withdrawal class, which is the logical place to implement our new feature. We can display a new class diagram for the Withdrawal class by selecting it in the Model Tree and choosing from the right-click context menu to create a new diagram. 
 We chose to create a hierarchy diagram so all the properties of the Withdrawal class are visible, including inherited properties from the Transaction class. Before implementing the fee feature, we have a related leftover question to investigate. We wanted to verify that the current code includes a test to make sure a withdrawal amount requested by the user does not exceed the current account balance. A UML sequence diagram will let us trace the execution flow of a withdrawal. UModel can automatically generate sequence diagrams from the operations of reverse-engineered classes. We can select the execute operation in our class diagram and choose Generate Sequence Diagram from the UModel right-click context menu to create the diagram we need.
We chose to create a hierarchy diagram so all the properties of the Withdrawal class are visible, including inherited properties from the Transaction class. Before implementing the fee feature, we have a related leftover question to investigate. We wanted to verify that the current code includes a test to make sure a withdrawal amount requested by the user does not exceed the current account balance. A UML sequence diagram will let us trace the execution flow of a withdrawal. UModel can automatically generate sequence diagrams from the operations of reverse-engineered classes. We can select the execute operation in our class diagram and choose Generate Sequence Diagram from the UModel right-click context menu to create the diagram we need.  The UModel Sequence Diagram Generation dialog offers several options that will assist with our implementation of the new feature. We selected Automatically update because we will want to update the diagram later after we modify the code, and showing the code in a separate layer can help us focus on the withdrawal logic.
The UModel Sequence Diagram Generation dialog offers several options that will assist with our implementation of the new feature. We selected Automatically update because we will want to update the diagram later after we modify the code, and showing the code in a separate layer can help us focus on the withdrawal logic.  The size of the scroll handles indicates we are only seeing a small portion of the sequence diagram in the current window. We can shrink the view to fit the window, but the text will probably be illegible. Instead, let’s take advantage the flexible UModel user interface to auto-hide the Diagram tree and Properties windows, which allows us to enlarge the Overview helper window:
The size of the scroll handles indicates we are only seeing a small portion of the sequence diagram in the current window. We can shrink the view to fit the window, but the text will probably be illegible. Instead, let’s take advantage the flexible UModel user interface to auto-hide the Diagram tree and Properties windows, which allows us to enlarge the Overview helper window:  We can explore the sequence diagram by dragging the red square in the Overview window. This lets us quickly locate the comparison of the withdrawal amount and account balance.
We can explore the sequence diagram by dragging the red square in the Overview window. This lets us quickly locate the comparison of the withdrawal amount and account balance.  We can also see the error messages that display if the ATM does not contain enough cash or if the account balance is too low.
We can also see the error messages that display if the ATM does not contain enough cash or if the account balance is too low.  Returning to the Withdrawal class diagram, we can add the fee property and set its default value:
Returning to the Withdrawal class diagram, we can add the fee property and set its default value:  We’ll make a first pass through implementation of the fee logic without including the user cancel option. Updating the source code from our model adds the fee property to the Withdrawal class. Then we’ll jump into our favorite source code editor to implement the fee logic directly in the Withdrawal.java file. Testing our recompiled application shows the following:
We’ll make a first pass through implementation of the fee logic without including the user cancel option. Updating the source code from our model adds the fee property to the Withdrawal class. Then we’ll jump into our favorite source code editor to implement the fee logic directly in the Withdrawal.java file. Testing our recompiled application shows the following:  The starting balance was $147. After withdrawing $100, the new balance is $43. The fee is displayed in a new message, and the ending balance is correct. But now the sequence diagram in our UML model is inaccurate because it doesn’t include the fee feature. We can correct the sequence diagram by updating the UML project from the revised source code. The UModel Messages window indicates that changes in the Withdrawal.java file caused the sequence diagram to be regenerated. And, we can easily navigate the diagram to locate our new test of the withdrawal amount to see if the fee needs to be increased to $4.
The starting balance was $147. After withdrawing $100, the new balance is $43. The fee is displayed in a new message, and the ending balance is correct. But now the sequence diagram in our UML model is inaccurate because it doesn’t include the fee feature. We can correct the sequence diagram by updating the UML project from the revised source code. The UModel Messages window indicates that changes in the Withdrawal.java file caused the sequence diagram to be regenerated. And, we can easily navigate the diagram to locate our new test of the withdrawal amount to see if the fee needs to be increased to $4.  Now that our modified sequence diagram graphically represents updated operation of the ATM, we can be assured the harried driver we met in Part 3 of this series has enough cash to buy that ice cream cone! In our next installment we’ll take advantage of another UModel feature to generate rich project documentation for our work so far – one more advantage of keeping our UML model and application source code synchronized. If you’re ready to try Altova UModel on your own Java, C#, or Visual Basic legacy application, click here to download a free fully functional 30-day trial.
Now that our modified sequence diagram graphically represents updated operation of the ATM, we can be assured the harried driver we met in Part 3 of this series has enough cash to buy that ice cream cone! In our next installment we’ll take advantage of another UModel feature to generate rich project documentation for our work so far – one more advantage of keeping our UML model and application source code synchronized. If you’re ready to try Altova UModel on your own Java, C#, or Visual Basic legacy application, click here to download a free fully functional 30-day trial.
Part 3 – Analyzing a Legacy Application with Altova UModel
In Part 1 of this series we applied the reverse engineering functionality of Altova UModel to import source code from an existing ATM simulation application. We created a UML class diagram to illustrate the application’s class hierarchy and class relationships. In Part 2 we drew a UML use case diagram to document user interactions with the system and we drew several additional use case diagrams to document interaction details and a planned enhancement. In this installment we’ll look at the ATM from another point of view. On a hot summer afternoon, a harried driver spots an ice cream stand with a drive through lane up ahead. Just one problem – no cash! So he turns in at the strip mall parking lot and parks by an ATM in a glass kiosk. Before he even gets out of the car, our overheated bank customer wonders about the state of the ATM. Is another customer with complicated banking business already using it? Even if no one is inside kiosk, could the ATM be out of service? A UML state machine diagram (also called a state diagram) will let us map the states of our simulated ATM and the triggers, events, and transitions between states so we can better understand how our legacy application operates. Let’s return again to our experience running the simulation to get started:
 When we launched the legacy application, our simulated ATM entered its idle state, awaiting the first customer:
When we launched the legacy application, our simulated ATM entered its idle state, awaiting the first customer:  Next, it can be helpful to identify and draw additional states in disconnected ovals. We’ll be able to move these ovals around like pieces of a puzzle to find the logical sequence without worrying about the transitions from one state to the next.
Next, it can be helpful to identify and draw additional states in disconnected ovals. We’ll be able to move these ovals around like pieces of a puzzle to find the logical sequence without worrying about the transitions from one state to the next.  This preliminary list of the ATM states is only our first rough draft. The state descriptions were suggested by our legacy application’s menu entries, and it’s obvious we can simplify: · There is no difference between Selecting First Transaction and Selecting Next Transaction, so these should be combined · Logging Out is probably not a state, but an instantaneous transition when our user presses 4 at the Transaction menu · We can assign user entry of a withdrawal amount or a deposit amount as sub-states within the Performing Transaction state The third item simplifies our diagram and would also be consistent with our treatment of user entry of the account number and PIN as part of Authenticating User. After we make these changes and add transitions, our diagram looks like this:
This preliminary list of the ATM states is only our first rough draft. The state descriptions were suggested by our legacy application’s menu entries, and it’s obvious we can simplify: · There is no difference between Selecting First Transaction and Selecting Next Transaction, so these should be combined · Logging Out is probably not a state, but an instantaneous transition when our user presses 4 at the Transaction menu · We can assign user entry of a withdrawal amount or a deposit amount as sub-states within the Performing Transaction state The third item simplifies our diagram and would also be consistent with our treatment of user entry of the account number and PIN as part of Authenticating User. After we make these changes and add transitions, our diagram looks like this:  The simple transitions we’ve added are triggers that cause the ATM to leave one state and enter the next. Also, notice every state has at least one entry and one exit – otherwise the legacy application could force our user into a dead end. The diamond element between Selecting Transaction and Performing Transaction is the UML symbol for a choice of flows. At first it may seem illogical for the application to allow the user to sign out before performing any transaction, but that is an option our legacy application offers in the Transaction menu. And users in the real world have been known to change their minds at the last minute! We were careful to use consistent language wherever possible for our element names and descriptions. The states are named with verbs in the present tense that end in -ing. Transitions are labeled to indicate completion of the action that causes the state to change. Consistent element naming enhances diagram clarity. Once we have a working overview state diagram like the one above, it’s worthwhile to consider what happens if a transition is attempted, but not completed successfully. The ATM user might enter an invalid account number/PIN combination, or an authenticated user could request a withdrawal amount that exceeds the account balance. We can enhance our state diagram to include these possibilities:
The simple transitions we’ve added are triggers that cause the ATM to leave one state and enter the next. Also, notice every state has at least one entry and one exit – otherwise the legacy application could force our user into a dead end. The diamond element between Selecting Transaction and Performing Transaction is the UML symbol for a choice of flows. At first it may seem illogical for the application to allow the user to sign out before performing any transaction, but that is an option our legacy application offers in the Transaction menu. And users in the real world have been known to change their minds at the last minute! We were careful to use consistent language wherever possible for our element names and descriptions. The states are named with verbs in the present tense that end in -ing. Transitions are labeled to indicate completion of the action that causes the state to change. Consistent element naming enhances diagram clarity. Once we have a working overview state diagram like the one above, it’s worthwhile to consider what happens if a transition is attempted, but not completed successfully. The ATM user might enter an invalid account number/PIN combination, or an authenticated user could request a withdrawal amount that exceeds the account balance. We can enhance our state diagram to include these possibilities:  Now our state machine diagram shows many alternate paths through the application execution, not just the single, all-successful “Happy Path.” We chose a vertical orientation for the layout of our diagram, but there is no rule dictating that form. Some applications will lend themselves to a horizontal layout, or maybe that is simply your personal preference. This illustration shows a small portion of our state machine diagram in horizontal form:
Now our state machine diagram shows many alternate paths through the application execution, not just the single, all-successful “Happy Path.” We chose a vertical orientation for the layout of our diagram, but there is no rule dictating that form. Some applications will lend themselves to a horizontal layout, or maybe that is simply your personal preference. This illustration shows a small portion of our state machine diagram in horizontal form:  Whichever state machine diagram layout you choose, you should not draw transition lines that intersect or overlap. Drawing a UML state machine diagram may seem like overkill for our ATM simulation, since the legacy application is small, and we are all familiar with the way ATMs work. However, these techniques can be very illuminating when you have to work on a much larger application operating in an unfamiliar or complex subject domain. If you are ready to create UML state machine diagrams for your own Java, C#, or Visual Basic legacy application, click here to download a free fully functional 30-day trial of Altova UModel. In our next installment we’ll look in detail at the withdrawal transaction and the new feature we planned in Part 2.
Whichever state machine diagram layout you choose, you should not draw transition lines that intersect or overlap. Drawing a UML state machine diagram may seem like overkill for our ATM simulation, since the legacy application is small, and we are all familiar with the way ATMs work. However, these techniques can be very illuminating when you have to work on a much larger application operating in an unfamiliar or complex subject domain. If you are ready to create UML state machine diagrams for your own Java, C#, or Visual Basic legacy application, click here to download a free fully functional 30-day trial of Altova UModel. In our next installment we’ll look in detail at the withdrawal transaction and the new feature we planned in Part 2.
Part 2 – Analyzing a Legacy Application with Altova UModel
In Part 1 of the Analyzing a Legacy Application series we introduced our ATM simulation app, imported the Java source code into a UModel project, and refined a class diagram to see an overview of the application classes and their relationships. In this entry we will create use case diagrams to document the current functionality of our ATM app and we’ll add to one use case diagram to plan a future enhancement. As we saw in Part 1, when a user runs our ATM simulation, he is asked to log in with an account number and PIN, then is presented with a transaction menu that summarizes all available interactions with the application: With the Transaction menu as a guide, we can create an overview use case diagram that documents user interactions with the ATM simulation:
With the Transaction menu as a guide, we can create an overview use case diagram that documents user interactions with the ATM simulation:  If you are familiar with UML notation, the first thing you may have noticed is the actor in our diagram doesn’t look like the typical UML stick figure. UModel lets software modelers assign any Windows .bmp image file to represent an actor in a use case diagram. We used the Properties helper window to assign an image from the library provided with UModel.
If you are familiar with UML notation, the first thing you may have noticed is the actor in our diagram doesn’t look like the typical UML stick figure. UModel lets software modelers assign any Windows .bmp image file to represent an actor in a use case diagram. We used the Properties helper window to assign an image from the library provided with UModel.  A use case diagram is not the appropriate place to define application flow or object-oriented classes, but simply to document how a user (an actor in UML terminology) interacts with the system. We can create additional use case diagrams to show more detail about each interaction. Expanding each interaction in a separate diagram improves clarity by keeping each layout simple and uncluttered and leaves plenty of space to try out different options.
A use case diagram is not the appropriate place to define application flow or object-oriented classes, but simply to document how a user (an actor in UML terminology) interacts with the system. We can create additional use case diagrams to show more detail about each interaction. Expanding each interaction in a separate diagram improves clarity by keeping each layout simple and uncluttered and leaves plenty of space to try out different options.  We added authentication of the account number and PIN in a note instead of a use case oval because the ATM user is not the actor who performs that step. From real-life ATM experience we can guess (because we haven’t looked at the code yet) that a withdrawal will be cancelled if the amount requested is larger than the account balance. But comparing the withdrawal amount and account balance is not done by the user, so that activity is also not drawn in a use case oval.
We added authentication of the account number and PIN in a note instead of a use case oval because the ATM user is not the actor who performs that step. From real-life ATM experience we can guess (because we haven’t looked at the code yet) that a withdrawal will be cancelled if the amount requested is larger than the account balance. But comparing the withdrawal amount and account balance is not done by the user, so that activity is also not drawn in a use case oval.  The arrow inside the Withdraw Cash use case indicates a hyperlink. UModel lets you can attach one or more hyperlinks to any element in your diagrams. A hyperlink can reference a URL, an external file, or another diagram. The hyperlink dialog even lets you define helper text for your hyperlinks.
The arrow inside the Withdraw Cash use case indicates a hyperlink. UModel lets you can attach one or more hyperlinks to any element in your diagrams. A hyperlink can reference a URL, an external file, or another diagram. The hyperlink dialog even lets you define helper text for your hyperlinks. 
 If you define more than one hyperlink, your helper text becomes a pop-up selection menu. Let’s say we’ve been assigned to modify the existing ATM Simulation to charge a fee for each withdrawal. If the withdrawal amount is less than $100, the fee will be $2. If the withdrawal amount is $100 or higher, the fee will be $4. Since the ATM is not stocked with one dollar bills, the fee must be charged against the account, not deducted from the cash withdrawal. The fee will be disclosed before any cash is dispensed and the user will be allowed to cancel the transaction. We can add the new requirement to our ATMWithdrawal use case diagram.
If you define more than one hyperlink, your helper text becomes a pop-up selection menu. Let’s say we’ve been assigned to modify the existing ATM Simulation to charge a fee for each withdrawal. If the withdrawal amount is less than $100, the fee will be $2. If the withdrawal amount is $100 or higher, the fee will be $4. Since the ATM is not stocked with one dollar bills, the fee must be charged against the account, not deducted from the cash withdrawal. The fee will be disclosed before any cash is dispensed and the user will be allowed to cancel the transaction. We can add the new requirement to our ATMWithdrawal use case diagram.  We changed the color of the Approve fee use case oval to indicate this is a planned feature that is not yet implemented. Some developers would argue that the note attached to the Approve fee oval is redundant, since the include notation alone signifies that Approve fee is a required component of Withdraw Cash. But lots of people are confused about the difference between include and extend and it’s best to be absolutely clear. We can also take advantage of the UModel Layers feature to place all elements related to the new feature on a separate layer.
We changed the color of the Approve fee use case oval to indicate this is a planned feature that is not yet implemented. Some developers would argue that the note attached to the Approve fee oval is redundant, since the include notation alone signifies that Approve fee is a required component of Withdraw Cash. But lots of people are confused about the difference between include and extend and it’s best to be absolutely clear. We can also take advantage of the UModel Layers feature to place all elements related to the new feature on a separate layer.  Now the Layers helper window allows us to show or hide the planned feature in our diagram view.
Now the Layers helper window allows us to show or hide the planned feature in our diagram view.  Real world ATM experience tells us a transaction is missing from the legacy ATM simulation. The transaction menu does not offer an option to transfer funds between accounts. From the diagrams we’ve already created, we can see the original application design will make a transfer operation difficult to implement. The user sign in is based on the account number, and it appears that the legacy application does not understand the concept of a single bank customer who has both a checking account and a savings account. If our manager requests the transfer funds feature, we’ll need to have a conversation with our company’s enterprise software architect. A user ID linked to multiple accounts will need to be implemented not only in our ATM Simulation app, but also in the bank database. The Jolt award-winning Altova MissionKit for Enterprise Architects is a collection of eight XML, database, and UML tools for the enterprise software architect who may require UML modeling and database management tools in addition to advanced XML, Web services, and data integration capabilities. Click here to download a fully-functional 30-day trial. In the next installment we’ll look at the legacy ATM simulation from a completely different perspective as we prepare to dive into the code. See ya later!
Real world ATM experience tells us a transaction is missing from the legacy ATM simulation. The transaction menu does not offer an option to transfer funds between accounts. From the diagrams we’ve already created, we can see the original application design will make a transfer operation difficult to implement. The user sign in is based on the account number, and it appears that the legacy application does not understand the concept of a single bank customer who has both a checking account and a savings account. If our manager requests the transfer funds feature, we’ll need to have a conversation with our company’s enterprise software architect. A user ID linked to multiple accounts will need to be implemented not only in our ATM Simulation app, but also in the bank database. The Jolt award-winning Altova MissionKit for Enterprise Architects is a collection of eight XML, database, and UML tools for the enterprise software architect who may require UML modeling and database management tools in addition to advanced XML, Web services, and data integration capabilities. Click here to download a fully-functional 30-day trial. In the next installment we’ll look at the legacy ATM simulation from a completely different perspective as we prepare to dive into the code. See ya later!
New DatabaseSpy Video: Exploring Databases
We’ve just launched the third video in the DatabaseSpy series. Exploring Databases is a tour of the DatabaseSpy Online Browser, a powerful tool for viewing, searching, and analyzing one or more connected databases. Exploring Databases builds on the preceding video, Database Connections, which demonstrated how easy it is to use DatabaseSpy to connect to one or more databases. You can even simultaneously connect to databases of different types. And DatabaseSpy supports the most popular databases in production today, including Microsoft SQL Server, IBM DB2, Oracle, Sybase, MySQL, and more. Once you’re connected, the DatabaseSpy Online Browser shows you an expandable hierarchy of the database structure. It’s a great place to start exploring an unfamiliar database or quickly navigate to any specific element you need to work with in a familiar one. The Altova Flash videos are proving to be a popular feature on our Web site, with close to 350,000 views in all. If you haven’t seen an Altova product video yet, you’re missing a great opportunity to get a flavor for components of the award-winning Altova MissionKit by seeing them in action. If you’re already a fan, check back again soon — we’re in the studio working on more videos right now.
Exploring Databases builds on the preceding video, Database Connections, which demonstrated how easy it is to use DatabaseSpy to connect to one or more databases. You can even simultaneously connect to databases of different types. And DatabaseSpy supports the most popular databases in production today, including Microsoft SQL Server, IBM DB2, Oracle, Sybase, MySQL, and more. Once you’re connected, the DatabaseSpy Online Browser shows you an expandable hierarchy of the database structure. It’s a great place to start exploring an unfamiliar database or quickly navigate to any specific element you need to work with in a familiar one. The Altova Flash videos are proving to be a popular feature on our Web site, with close to 350,000 views in all. If you haven’t seen an Altova product video yet, you’re missing a great opportunity to get a flavor for components of the award-winning Altova MissionKit by seeing them in action. If you’re already a fan, check back again soon — we’re in the studio working on more videos right now.
Analyzing a Legacy Application with Altova UModel – Part 1
Sooner or later nearly every professional developer will be assigned to debug or add features to an existing application the developer did not help create. In these situations, inaccurate or incomplete documentation and lack of access to the original development team can pose huge obstacles. Fortunately, Altova UModel can reverse-engineer existing software to create a visual model that accelerates analysis and improves comprehension of a legacy application. This is the first of a series in posts where we will apply UModel, Altova’s UML tool for software modeling and development, to analyze an ATM (Automatic Teller Machine) simulation written in Java. The application is based on several ATM examples from popular Java tutorials. Since it is small and the operation of an ATM is familiar, we will focus more on techniques you can apply to your own Java, C#, and Visual Basic projects, rather than the example code. Here is a view of the legacy application running in a command window: The original developer conveniently provided the sample account information, so we can log in. The application then presents a familiar ATM transaction menu:
The original developer conveniently provided the sample account information, so we can log in. The application then presents a familiar ATM transaction menu:  If we inspect the folder containing the application, we see Java source files and compiled .class files, but no project files.
If we inspect the folder containing the application, we see Java source files and compiled .class files, but no project files.  That’s not a problem. The UModel Project menu lets us import a project, a source directory, or even the binary files of a compiled application. Source code for very large projects is likely to be organized in multiple folders, so even when you have a project file, you may want to investigate one folder at a time.
That’s not a problem. The UModel Project menu lets us import a project, a source directory, or even the binary files of a compiled application. Source code for very large projects is likely to be organized in multiple folders, so even when you have a project file, you may want to investigate one folder at a time.  Before we start, we’ll want to make sure to set the UModel Options to automatically draw any class associations defined in the source code:
Before we start, we’ll want to make sure to set the UModel Options to automatically draw any class associations defined in the source code:  As we import the folder, we’ll also want to include any JavaDocs comments in the source code as Documentation for our UModel project:
As we import the folder, we’ll also want to include any JavaDocs comments in the source code as Documentation for our UModel project:  For our first look at the legacy application we’ll want a high-level overview, so we won’t open all the optional compartments:
For our first look at the legacy application we’ll want a high-level overview, so we won’t open all the optional compartments:  UModel imports the project in just a few seconds, and the message window reports no errors. The Diagram Tree contains two diagrams:
UModel imports the project in just a few seconds, and the message window reports no errors. The Diagram Tree contains two diagrams:  We can click the Model Tree tab and expand the source folder to view icons representing all the Java classes UModel imported:
We can click the Model Tree tab and expand the source folder to view icons representing all the Java classes UModel imported:  We can go back to the Diagram Tree to open the Content of source UML class diagram. After setting all the line styles to orthogonal and repositioning a few lines and classes to avoid overlap, we see the diagram clearly illustrates the application classes and their relationships:
We can go back to the Diagram Tree to open the Content of source UML class diagram. After setting all the line styles to orthogonal and repositioning a few lines and classes to avoid overlap, we see the diagram clearly illustrates the application classes and their relationships:  Note the name of the Transaction class is in italic, indicating it is an abstract class (or super class), and the BalanceInquiry, Withdrawal, and Deposit subclasses inherit its features. If you click the Transaction class to select it, inheritance is illustrated in the UModel Hierarchy helper window and any JavaDoc comments appearing in the source code immediately before the class definition are displayed in the Documentation window:
Note the name of the Transaction class is in italic, indicating it is an abstract class (or super class), and the BalanceInquiry, Withdrawal, and Deposit subclasses inherit its features. If you click the Transaction class to select it, inheritance is illustrated in the UModel Hierarchy helper window and any JavaDoc comments appearing in the source code immediately before the class definition are displayed in the Documentation window:  If we were using only a text editor to examine the legacy application, we would need to look into every single source code file to understand the hierarchy image shown above. That’s because the Transaction class does not internally identify its subclasses. When we do locate one subclass, it does not identify its siblings. And we can’t be sure some other illogically-named class is not a subclass of Transaction until we look at them all. You can also select each class individually to examine its documentation in the Documentation window. Or, if you prefer a cleaner diagram, you can remove the association labels from the diagram only:
If we were using only a text editor to examine the legacy application, we would need to look into every single source code file to understand the hierarchy image shown above. That’s because the Transaction class does not internally identify its subclasses. When we do locate one subclass, it does not identify its siblings. And we can’t be sure some other illogically-named class is not a subclass of Transaction until we look at them all. You can also select each class individually to examine its documentation in the Documentation window. Or, if you prefer a cleaner diagram, you can remove the association labels from the diagram only:  Now the asterisk representing the definition of “zero to many” multiplicity of Accounts in the BankDatabase is much more apparent.
Now the asterisk representing the definition of “zero to many” multiplicity of Accounts in the BankDatabase is much more apparent.  Another member of our development team found a partial class diagram purporting to represent the legacy project and passed it on. We can immediately see it does not look like the diagram UModel generated:
Another member of our development team found a partial class diagram purporting to represent the legacy project and passed it on. We can immediately see it does not look like the diagram UModel generated:  The documentation for our legacy app does not match the code – an unfortunate but common event! There are several differences between the old diagram and the one we generated:
The documentation for our legacy app does not match the code – an unfortunate but common event! There are several differences between the old diagram and the one we generated:
Let’s consider each point:
We’ll add the annotation, then update the aggregation characteristic of each ATM association in the UModel properties window. Let’s also use the UModel Layout toolbar to make the rectangles representing all the classes the same size. Now our class diagram looks like this: The completed class diagram just gets us started on our analysis. In the next installments we’ll drill deeper into the application code, automatically generate more UML diagrams, and draw some new diagrams of our own as our understanding of the existing code increases. If you want to jump in right away and reverse engineer your own Java, C#, or Visual Basic legacy app, click here to download a free, fully functional 30-day trial of Altova UModel.
The completed class diagram just gets us started on our analysis. In the next installments we’ll drill deeper into the application code, automatically generate more UML diagrams, and draw some new diagrams of our own as our understanding of the existing code increases. If you want to jump in right away and reverse engineer your own Java, C#, or Visual Basic legacy app, click here to download a free, fully functional 30-day trial of Altova UModel.
Altova Software Version 2009 SP1 Available
Today we released Service Pack 1 of Altova Version 2009 product line (v2009 SP1), which includes helpful bug fixes and other enhancements, as well as a new feature in the MapForce data mapping tool (detailed below). v2009 SP1 is a free update for all v2009 customers, as well as any customer with a valid Support and Maintenance Package. Note that v2009 SP1 is a new product version, and not a patch – you can simply visit the Altova Download Page to download and install the latest version of your product(s) to update.
Recursive User Defined Functions
Added based on feedback from Altova partners, this new feature in MapForce 2009 SP1 provides support for non-inlined user-defined functions in data mapping projects. Now users can create recursive function calls, enabling them to map data dynamically by expressing operations in terms of themselves. In hierarchical data structures like XML, for instance, it is possible for an element to contain itself or be referenced, in some way or another, by a descendant. Creating a recursive user-defined function allows you to process this data, looping through the elements incrementally and returning data that has been evaluated dynamically. Update to get this new functionality and all the v2009 SP1 enhancements across the Altova product line. If you’re not already a v2009 customer, you can download a free, fully functional trial using the same link.
SOA and Cloud Services Within Your Budget
The hardships affecting today’s economy present new challenges for organizations. Interdepartmental budgets are being cut, and large purchases are being carefully scrutinized. Costly enterprise software and mainframe computing systems that once held promise are being reconsidered on a global scale in favor of more agile, component-based systems that cut costs and increase efficiency with forward-thinking concepts like Service-oriented Architecture (SOA) and cloud computing. These architectural concepts incorporate modern technologies and object-oriented approaches to solve real-world technology issues in complex environments while decreasing maintenance, integration, and deployment costs with modular design and component re-use. The Altova MissionKit is a highly affordable toolset uniquely suited to address this shift toward more flexible and lightweight infrastructure. With strong support for XML, UML, databases, and data integration technologies, the MissionKit offers all of the tools necessary to build agile architectures replete with repeatable services, reusable components, and scalable resources.
SOA & Cloud Computing
SOA and Web/cloud services are two of the strongest buzzwords in technology today. Though they have some clear differences, both of these concepts represent a paradigm shift from large-scale enterprise systems to service-based architectures built on modular components and reusable functionality. The SOA approach aims to help organizations respond more quickly to business requirements by packaging processes as a network of interoperable and repeatable services. This modularity creates system flexibility and gives developers the agility required to build new capabilities into the current system as needed – without reinventing the proverbial wheel. SOA is essentially a series of interconnected and self-contained services, the functionality of which is dynamically located and invoked based on certain criteria, communicated in messages. At the heart of SOA is a high level of component reuse that drives down costs and increases efficiency in a fully scalable architecture. Cloud services build upon the concept of interoperable services, adding a virtualization component to help relieve internal servers from being overtaxed by the constant reuse of these services within the system. This paradigm uses the Internet and Internet-enabled technologies to increase performance and processing speed by storing information permanently in the "cloud" and caching it only temporarily on client machines. Cloud computing implementation is a powerful option for increasing system capacity and capabilities by leveraging next-generation data centers in combination with the World Wide Web. Both SOA and cloud computing seek to alleviate problems created by inflexible architectures that rely heavily on tightly coupled enterprise application infrastructure. This focus on interoperability and independent software services reveals a distributed solution that is event-driven, flexible, and cost conscious in almost any setting.
Anatomy of a Service-based Architecture
Since their inception, XML and Web services have been continuously gaining notoriety as the standards of choice for secure, efficient, and platform-independent data exchange between software applications and over the Internet. XML provides the foundation for the protocols that power Web services infrastructure: WSDL (Web Services Description Language) and SOAP, an XML-based messaging standard. Web services are hardware, programming language, and operating system independent, meaning that they are duly amenable to the seamless and interoperable exchange of data over a network and uniquely suited to component-based systems. Web services architecture Both SOA and cloud-based architectures generally rely on WSDL to describe interaction and functionality and locate operating components within the system. WSDL works hand-in-hand with SOAP, a messaging protocol used by the client application to invoke the methods and functions defined in the WSDL description. The example below is the stock quote example used in the W3C WSDL specification and describes a simple, single operation service that retrieves real-time stock prices based on ticker symbol input. Of course, most services that exist within enterprise architectures are far more complex.
Both SOA and cloud-based architectures generally rely on WSDL to describe interaction and functionality and locate operating components within the system. WSDL works hand-in-hand with SOAP, a messaging protocol used by the client application to invoke the methods and functions defined in the WSDL description. The example below is the stock quote example used in the W3C WSDL specification and describes a simple, single operation service that retrieves real-time stock prices based on ticker symbol input. Of course, most services that exist within enterprise architectures are far more complex.  Take, for example, the publicly available Amazon Web services, which provide accessible Cloud services and infrastructure to a growing number of companies worldwide, including Twitter, SmugMug, and WordPress.com. These services essentially allow independent organizations to rent some of the immense power built into the Amazon distributed computing environment and add the same scalability, reliability, and scalability to their online presence at a fraction of the price. The much anticipated Windows Azure from Microsoft® operates on a similar model, giving developers the opportunity to build and deploy cloud-based applications with minimal on-site resources. Amazon provides a WSDL file that contains the definition of the Web service, the requests that the service accepts, and so on. Developers can then write a SOAP-based client application that invokes the Amazon Web service for the functionality it provides. (At this time Amazon provides a number of Cloud-based services for application hosting, backup and storage, content delivery, e-commerce, search, and high-performance computing.)
Take, for example, the publicly available Amazon Web services, which provide accessible Cloud services and infrastructure to a growing number of companies worldwide, including Twitter, SmugMug, and WordPress.com. These services essentially allow independent organizations to rent some of the immense power built into the Amazon distributed computing environment and add the same scalability, reliability, and scalability to their online presence at a fraction of the price. The much anticipated Windows Azure from Microsoft® operates on a similar model, giving developers the opportunity to build and deploy cloud-based applications with minimal on-site resources. Amazon provides a WSDL file that contains the definition of the Web service, the requests that the service accepts, and so on. Developers can then write a SOAP-based client application that invokes the Amazon Web service for the functionality it provides. (At this time Amazon provides a number of Cloud-based services for application hosting, backup and storage, content delivery, e-commerce, search, and high-performance computing.)
Altova MissionKit
Recently named "Best Development Environment" in the Jolt Product Excellence Awards, the Altova MissionKit is a diverse set of software tools that provides scalable options for leveraging your current software assets in an SOA or cloud-enabled environment. Strong support for XML, Web services, data integration, process automation, and databases, as well as accessibility to powerful APIs give developers flexible options for creating service-based solutions and an affordable alternative to costly consultant fees, extract/transform/load (ETL) tools, and/or enterprise service bus (ESB) products. The Altova MissionKit* supports end-to-end Web services development and includes a graphical WSDL editor, visual Web services builder, advanced capabilities for managing WSDL and other XML file relationships, a SOAP client and debugger, WSDL data integration, code generation, and more. Together, all of these features provide a robust solution for integrating disparate services and systems in a distributed computing environment, whether the components be in-house, network, or Cloud-based.
WSDL Editor
The XMLSpy XML editor provides a graphical interface (GUI) for designing and editing WSDL documents. The structure and components of the WSDL are created in the main design window using graphical design mechanisms (with tabs allowing users to toggle back and forth between text view), and additional editing capabilities are enabled from comprehensive entry helper windows. Users can easily create and edit messages, types, operations, portTypes, bindings, etc., inline. In addition, publicly maintained WSDL files like the Amazon Simple Storage Service, or Amazon S3, (below) can be opened instantly using the Open URL command in XMLSpy. XMLSpy’s WSDL editor gives developers a sophisticated environment for rapid Web services development, managing WSDL syntax and validation through an intuitive, drag and drop graphical interface. The addition of a documentation generation feature makes it possible to share the complete details of a Web service interface with non-technical stakeholders in HTML or Microsoft Word.
XMLSpy’s WSDL editor gives developers a sophisticated environment for rapid Web services development, managing WSDL syntax and validation through an intuitive, drag and drop graphical interface. The addition of a documentation generation feature makes it possible to share the complete details of a Web service interface with non-technical stakeholders in HTML or Microsoft Word.
SOAP Client
SOAP requests can be manually created in XMLSpy’s SOAP client based on the operations defined in the WSDL. Once an operation is selected, XMLSpy initiates the request based on the connections provided in the WSDL and displays the XML syntax of the SOAP envelope in the main window. The message can then be sent directly to the server for an immediate response.
SOAP Debugger
XMLSpy also includes a SOAP debugger, which acts as Web services proxy between client and server, enabling developers to analyze WSDL files and their SOAP message components, single-step through transactions, set breakpoints on SOAP functions, and even define conditional breakpoints that are triggered by a stated XPath query.
Building Web Services
Once a WSDL definition is complete, it can also be visually implemented using MapForce, Altova’s any-to-any data integration tool. MapForce gives users the ability to map data to or from WSDL operations and then autogenerate program code in Java or C#. Tight integration with Visual Studio and Eclipse makes it possible to then compile the code within either of these IDEs and deploy the service on the client machine. When you create a new Web service project by specifying a Web services definition file (WSDL), MapForce automatically generates mapping files for each individual SOAP operation. The SOAP input and output messages can then be easily mapped to other source data components (XML, databases, flat files, EDI, XBRL, Excel 2007) to create a complete Web services operation. Data processing functions, filters, and constants can also be inserted to convert the data on the fly.
The SOAP input and output messages can then be easily mapped to other source data components (XML, databases, flat files, EDI, XBRL, Excel 2007) to create a complete Web services operation. Data processing functions, filters, and constants can also be inserted to convert the data on the fly.  MapForce can autogenerate Web services implementation code in Java or C# for server-side implementation, and it is also accessible for automation via the command line.
MapForce can autogenerate Web services implementation code in Java or C# for server-side implementation, and it is also accessible for automation via the command line.
File Relationship Management
For complex Web-based applications that include a large number of disparate files and project stakeholders, the MissionKit offers an advanced graphical XML file relationship management tool in SchemaAgent. SchemaAgent can analyze and manage relationships among XML Schemas, XML instance documents (SOAP), WSDL, and XSLT files. The client/server option enables any changes to be visualized in real time across a workgroup. This gives organizations the ability to track and manage their mission critical SOA files as reusable individual components, reducing development time and the occurrence of errors.
This gives organizations the ability to track and manage their mission critical SOA files as reusable individual components, reducing development time and the occurrence of errors.
Data Integration
A key factor of any SOA is the ability for disparate systems to communicate seamlessly via automated processes. As an any-to-any graphical data integration and Web services implementation tool, MapForce facilitates this undertaking with support for a wide variety of data formats including XML, databases, flat files (which can be easily parsed for integration with legacy systems with the help of the unique FlexText™ utility), EDI, XBRL, Excel 2007, and Web services. MapForce supports complex data mapping scenarios with multiple sources and targets and advanced data processing functions. Transformations can easily be automated via code generation in C#, C++, or Java, or the command line. Full integration with Visual Studio and Eclipse also makes this an ideal development tool for working in large-scale enterprise projects – without the heavy price tag. This gives developers a flexible and agile middleware component that can work in virtually any service-based architecture. The ability to integrate disparate data in on-the-fly is a key requirement in real-world enterprise and cross-enterprise systems where legacy systems and other less flexible formats co-exist with XML and other modern, interoperable standards.
MapForce supports complex data mapping scenarios with multiple sources and targets and advanced data processing functions. Transformations can easily be automated via code generation in C#, C++, or Java, or the command line. Full integration with Visual Studio and Eclipse also makes this an ideal development tool for working in large-scale enterprise projects – without the heavy price tag. This gives developers a flexible and agile middleware component that can work in virtually any service-based architecture. The ability to integrate disparate data in on-the-fly is a key requirement in real-world enterprise and cross-enterprise systems where legacy systems and other less flexible formats co-exist with XML and other modern, interoperable standards.
Database Management
Even in the rapidly evolving semantics-driven macrocosm that is Web 2.0, most companies still use one or more relational databases to store and manage their internal data assets. The Altova MissionKit supports working with the most prevalent of these systems (see listing below) in a wide variety of different ways. Database support is offered in XMLSpy, MapForce, StyleVision, and, of course, DatabaseSpy.
DatabaseSpy is a multi-database query, editing, design, and comparison tool that allows users to connect directly to all major databases and edit data and design structure in a graphical user interface with features like table browsing, data editing, SQL auto-completion entry helpers, visual table design, content diff/merging, and multiple export formats. In a service-based architecture, the ability to compare and merge data directly in its native database format is an enormous asset to developers who need to locate changes, migrate differences, or synchronize versions of database tables across test and live environments. As a component of the MissionKit, DatabaseSpy gives disparate groups within organizations the flexibility to work with data from multiple databases in one central interface simultaneously. Whether this data is eventually integrated into other systems or applications or lives permanently in the database, DatabaseSpy provides a simple and flexible solution to managing and maintaining massive data stores.
As a component of the MissionKit, DatabaseSpy gives disparate groups within organizations the flexibility to work with data from multiple databases in one central interface simultaneously. Whether this data is eventually integrated into other systems or applications or lives permanently in the database, DatabaseSpy provides a simple and flexible solution to managing and maintaining massive data stores.
Single Source Publishing
In today’s world of highly automated data transfer and management, it is still necessary for human readers to ultimately consume the data in some format or other. Of course, the problem that organizations often run into is what format to publish to. XML and single source publishing have revolutionized content management, document exchange, and even multilingual communications by separating content structure from appearance. An XML-based documentation system can greatly reduce costs through facilitating ease of conversion for delivery to many different data formats and types of applications. The single source concept ensures that workflow processes (i.e., conversion, edits, etc.) do not have to be repeated or reworked – that all content in the repository requires only minimal restructuring and promotion before being loaded to respective applications for delivery. Altova StyleVision is a graphical stylesheet design tool that enables users to easily apply single source publishing to XML, XBRL, and database content, without having any affect on the source data. In this way, companies can create reusable template designs for data that can then be rendered automatically in HTML, RTF, PDF, Microsoft Word 2007, and even an Authentic e-Form for immediate publication to any conceivable medium without any process disruption – resulting in the presentation of accurate, consistent, and standardized information in real-time. Single source publishing gives organizations the ability to add a human component to their highly automated data processing workflows, enabling them to view transmission reports at any stage. For example, in a world where compliance management plays such a large role in day to day enterprise operations, StyleVision can be integrated into any SOA to provide a sort of visual audit trail for manually reviewing XML, XBRL, and database transactions. StyleVision’s template-based approach to stylesheet design makes it an ideal addition to a distributed development environment, where repeatable processes are an integral part of the system’s overall efficiency.
Single source publishing gives organizations the ability to add a human component to their highly automated data processing workflows, enabling them to view transmission reports at any stage. For example, in a world where compliance management plays such a large role in day to day enterprise operations, StyleVision can be integrated into any SOA to provide a sort of visual audit trail for manually reviewing XML, XBRL, and database transactions. StyleVision’s template-based approach to stylesheet design makes it an ideal addition to a distributed development environment, where repeatable processes are an integral part of the system’s overall efficiency.
Conclusions
Financial downturns can make investing in technology a difficult decision. However, forward-thinking organizations will find that focusing on restructuring the legacy assets they already have in place, automating internal processes, and adding virtualization layer to their application infrastructure can lead to increases in efficiency, speed, and potentially enormous ROI. The Altova MissionKit gives businesses all of the tools that they need to augment their enterprise architecture with iterative, process-driven solutions that will recover costs through the reuse of current assets and the ability to deliver Web-driven automation within and across organizations on a global scale. The MissionKit is a highly affordable solution that offers developers, software architects, and IT users all of the tools they need to build flexible and powerful technology solutions and efficiencies that advance component-based service-oriented infrastructure – without breaking the budget.
Exploring Large XML/XBRL Documents with XMLSpy
Last week, while giving a demo of the new XBRL capabilities in the Altova MissionKit, we stumbled across an interesting question: What is the best way for a semi-technical SME (in this case a CPA) to navigate a large XML/XBRL document for data entry? XMLSpy, which is included in the MissionKit tool suite, has a lot of cool features and different views for XML data, including the ever-popular grid view for visualizing the hierarchical structure of an instance document in a graphical manner. The ability to easily expand and collapse containers and drag and drop to change position makes XMLSpy’s grid view a pretty good choice for the task. Of course let’s not forget that the XMLSpy XML editor also has a Find feature that would enable users to simply press Ctrl F or use the Find in Files window to find any element that they are looking for… but alas, in the case of XBRL, where element names are mindbogglingly verbose, this may be a challenge. Consider, for example, the US-GAAP’s aptly named <us-gaap:IncomeLossFromContinuingOperationsBeforeIncomeTaxesMinorityInterestAnd IncomeLossFromEquityMethodInvestments>. Not so much fun to type into a Find dialog… Our solution, therefore, and the winner for the easiest and most comprehensive way for even a non-technical user to find XML elements in a large document, utilizes a combination of longstanding XMLSpy features (the XPath Analyzer window) and a new feature in XMLSpy v2009, XPath auto-completion. Simply begin typing the element name in the XPath Analyzer window, and XMLSpy will show you all of the possibilities. Next, choose the one you are looking for, and XMLSpy will navigate directly to that node in the XML document.
Of course let’s not forget that the XMLSpy XML editor also has a Find feature that would enable users to simply press Ctrl F or use the Find in Files window to find any element that they are looking for… but alas, in the case of XBRL, where element names are mindbogglingly verbose, this may be a challenge. Consider, for example, the US-GAAP’s aptly named <us-gaap:IncomeLossFromContinuingOperationsBeforeIncomeTaxesMinorityInterestAnd IncomeLossFromEquityMethodInvestments>. Not so much fun to type into a Find dialog… Our solution, therefore, and the winner for the easiest and most comprehensive way for even a non-technical user to find XML elements in a large document, utilizes a combination of longstanding XMLSpy features (the XPath Analyzer window) and a new feature in XMLSpy v2009, XPath auto-completion. Simply begin typing the element name in the XPath Analyzer window, and XMLSpy will show you all of the possibilities. Next, choose the one you are looking for, and XMLSpy will navigate directly to that node in the XML document.  Now that was easy! And better yet, you get to tell your friends that you know XPath. 😉 Of course, for developers, intelligent XPath auto-completion provides a lot more than the ability to find a node quickly. As you type, it provides you with valid XPath functions, as well as element and attribute names from the associated schema and XML instance(s). XMLSpy accounts for namespaces when listing options and even provides deep path suggestions when the required node is not in close proximity to the current context. XMLSpy is available standalone or as part of the award-winning MissionKit tool suite.
Now that was easy! And better yet, you get to tell your friends that you know XPath. 😉 Of course, for developers, intelligent XPath auto-completion provides a lot more than the ability to find a node quickly. As you type, it provides you with valid XPath functions, as well as element and attribute names from the associated schema and XML instance(s). XMLSpy accounts for namespaces when listing options and even provides deep path suggestions when the required node is not in close proximity to the current context. XMLSpy is available standalone or as part of the award-winning MissionKit tool suite.
Teach DiffDog a New Trick
Teach DiffDog a New Trick You can easily train DiffDog, Altova’s diff/merge tool for files, directories, and databases, to correctly interpret new file types. For instance, more and more file standards are taking advantage of the Zip compression format to deliver entire sets of files in a single convenient package. Let’s say you want to use DiffDog to examine and compare files created by Google Earth that are saved in .kmz archives. When you initially open a folder containing .kmz documents, then attempt to compare two files in a DiffDog document window, DiffDog reports the .kmz files contain binary content: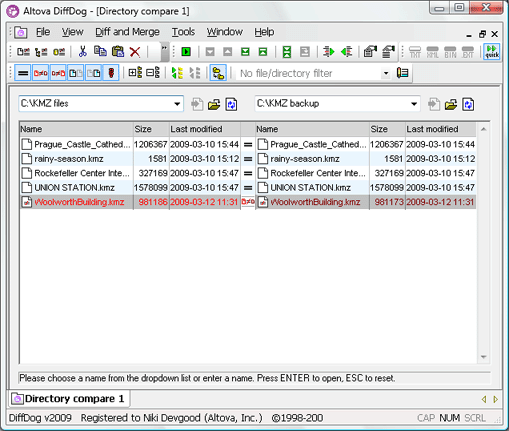
 All you have to do is add the .kmz file extension in the File Types tab of the DiffDog Options dialog:
All you have to do is add the .kmz file extension in the File Types tab of the DiffDog Options dialog:  And click the Zip conformant radio button to assign the correct behavior:
And click the Zip conformant radio button to assign the correct behavior:  Now that DiffDog understands the .kmz file extension is a Zip archive, it expands the Directory compare window to list all the component files.
Now that DiffDog understands the .kmz file extension is a Zip archive, it expands the Directory compare window to list all the component files. 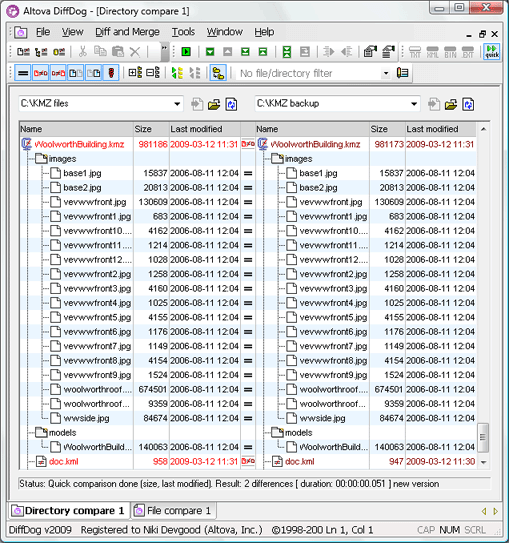 You can see differences inside the archives. When you double-click any file pair, DiffDog automatically fetches them from the Zip archives and presents them for interactive editing in a new File Compare window. However, some of the file types enclosed in the Zip archive are also unknown. We learned from reading the XML Aficionado blog entry on Google Earth and XMLSpy that .kml files are an open XML-based standard for geo-spatial information. We can add .kml to DiffDog files types and specify XML-conformant syntax coloring:
You can see differences inside the archives. When you double-click any file pair, DiffDog automatically fetches them from the Zip archives and presents them for interactive editing in a new File Compare window. However, some of the file types enclosed in the Zip archive are also unknown. We learned from reading the XML Aficionado blog entry on Google Earth and XMLSpy that .kml files are an open XML-based standard for geo-spatial information. We can add .kml to DiffDog files types and specify XML-conformant syntax coloring:  Now DiffDog displays the files with syntax coloring and we can apply all the DiffDog XML-aware differencing functionality.
Now DiffDog displays the files with syntax coloring and we can apply all the DiffDog XML-aware differencing functionality.  If you dig deeper into the .kmz archive, you’ll discover .dae files are also XML-based. After you add .dae to the DiffDog files list and set it as XML-compliant, give yourself a treat!
If you dig deeper into the .kmz archive, you’ll discover .dae files are also XML-based. After you add .dae to the DiffDog files list and set it as XML-compliant, give yourself a treat!  DiffDog is available as a standalone tool or as part of the Altova MissionKit tool suite. The recently released DiffDog Version 2009 added powerful database content diff/merge capabilities – take a free trial for a walk around the block.
DiffDog is available as a standalone tool or as part of the Altova MissionKit tool suite. The recently released DiffDog Version 2009 added powerful database content diff/merge capabilities – take a free trial for a walk around the block.
Altova MissionKit Wins Prestigious Jolt Award
We are very excited to announce that the Altova MissionKit won the Jolt Product Excellence Award for Best Development Environment last night! Lauded as the "Oscars of the Software Development Industry," the Jolt Product Excellence and Productivity Awards are presented each year to products that have "jolted" the industry with their significance and made the task of creating software faster, easier, and more efficient. According to their Web site, the Jolt Awards, "…recognize the most innovative, trend-making, ahead-of-the-curve products. Jolt-award winners are the software products, books and technologies that developers should be using today." We are honored – and very proud – to be recognized with this designation for the MissionKit, Altova’s suite software development tools for XML, databases, and UML. The unmatched functionality and tight integration between the tools in the MissionKit have been designed from day one to make developers’ lives easier, and we couldn’t be happier to have this recognized first and foremost by our customers and now by this panel of distinguished Jolt Award judges! The complete list of Jolt award winners has been posted, and more info and photos will follow soon as they’re available. A big thank you to the Jolt judges, and congratulations to all the other Jolt Award winners!
What's New…To Me?
With each release, we update the Altova What’s New page with many details and screenshots describing all the functionality added to each product in the Altova MissionKit. If you’ve ever visited the page, you know it’s quite long — and that’s why we only include information on the latest release. This is very helpful for the folks who are one version behind, but what if it’s been a while since you upgraded? You can check out the New Features Index pages, which allow you to select the current version of your product(s) to see everything that’s been added since:
What's New in MapForce 2009?
It feels like we’ve been writing about XBRL and HL7 for months… Let’s move away from that topic for the moment and talk about additional essential new functionality added to MapForce in the v2009 release. Granted, some of these features have been added as a necessity for mapping to/from multi-dimensional XBRL data, but they also transcend well beyond interactive financial data reporting to the other aspects of mapping XML, database, flat file, EDI, Excel 2007, and Web services data in MapForce.
Custom Functions for Data Mapping
MapForce functions add a custom data processing layer to your mappings, letting you reformat output structure and even manipulate content on-the-fly. With v2009 we have added a grouping, distinct-values, and a predicated position function to the already well-shelved MapForce function library. Grouping functions can be selected for code generation in XSLT 2.0, Java, C#, and C++ and let you effectively reorganize source data into based on common values:
The distinct-values function is a data filtering operation that, simply put, automatically ignores duplicate input values when writing mapping output results.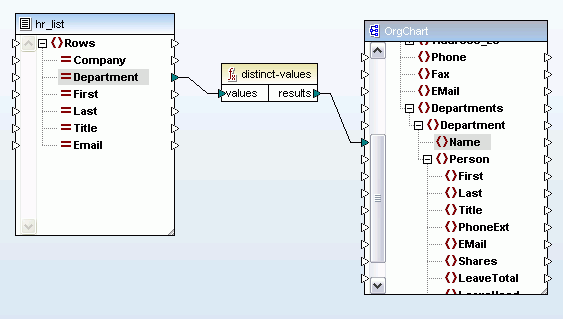 MapForce also now includes a predicated position function that lets you filter out data based on its context position in the input document. For example, the mapping below will return data for only the first two people listed in the source document.
MapForce also now includes a predicated position function that lets you filter out data based on its context position in the input document. For example, the mapping below will return data for only the first two people listed in the source document. 
Extended Database Support
For users creating database mappings, MapForce 2009 provides new native support for additional databases: Microsoft SQL Server 2008, Oracle 11g, and PostgreSQL 8. It also now supports mapping XML fields in SQL Server. The complete list of natively supported databases is:
Data Mapping Documentation
The ability to generate data mapping documentation makes it much easier to collaborate on large data integration projects, which often include a variety of designers, developers, subject matter experts, and stakeholders.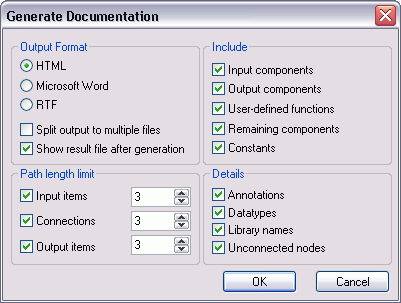
Find Dialog for Identifying Nodes
And now for a personal favorite: a new find feature. Yes, this may sound very simple and mundane – unless you have had the pleasure of mapping large and complex multi-layered data components like XBRL and EDI (there we go again!). Consider, for example, digging through an HL7 ADT A05 transaction to find the second CWE identifier field under the fifteenth PR1 segment. Ahhh… much easier!! Take a look at the full list of new features in MapForce v2009 – and, as always, keep in mind that Altova adds new functionality to all of the MissionKit tools based on user requests… so keep ‘em coming!
Ahhh… much easier!! Take a look at the full list of new features in MapForce v2009 – and, as always, keep in mind that Altova adds new functionality to all of the MissionKit tools based on user requests… so keep ‘em coming!
HL7 Data Integration
By now, you may be aware of the global push that is being made for data transparency – both in the realm of financial reporting* with a recent XBRL mandate in the U.S., and electronic health records – and that these efforts are focused on the creation and maintenance of XML standards. Of course most of you are among the XML savvy and can feel free to please join me in a resounding “duh” to the rest of the world that is only now beginning to realize the value of XML data in reducing errors, lowering costs, and generally increasing the overall efficiency of data management. But for now, let’s focus a bit on healthcare data and standards. Both HL7 and the HIPAA mandated X12N formats healthcare data exchange have traditionally been EDI-based, but the newest version of HL7 (version 3.x), released in 2005 is XML-based and constrained by a formal framework (HDF) that allows for an evolving data model within a carefully defined development methodology. Yes people, standards – bring it on!! Well, of course there is a need to map this data from the HL7 EDI to HL7 XML, to and from backend systems, to Web services and beyond. So what now? Do you need to become an expert in all of these formats? Weren’t standards supposed to make things EASIER? Please ladies and gentleman, return to your seats! Let me draw your attention once again to MapForce, the coolest data integration tool on the market, with support for mapping and converting data to and from XML, databases, flat files, EDI (including HL7, X12, and EDIFACT), Excel 2007, and Web services.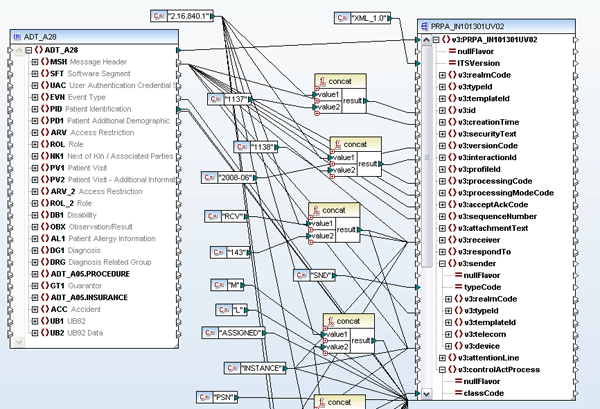 The shot above shows a simple graphical mapping updating an HL7 v2.6 message to v3.x. Altova MapForce is an any-to-any visual data mapping tool that supports mapping HL7 data, in its legacy EDI or newer XML-based format, to and from XML, databases, flat files, other EDI formats, and Web services. Mappings are implemented by simply importing the necessary data structures (MapForce ships with configuration files for the latest EDI standards and offers the full set of past and present HL7 standards as a free download) and dragging lines to connect nodes. A built-in function library lets you add advanced data filters and functions to further manipulate the output data. MapForce can also facilitate the automation of your HL7 transaction workflow through code generation in Java, C#, or C++ and an accessible command line interface. Additional support for mapping HL7 data to and from Web services gives healthcare organizations the ability to meet new technology challenges and changing enterprise infrastructures as they unfold within internal and external provider domains. Read more on our new HL7 tools page in the Altova Solutions Center. *The Altova MissionKit has been infused with XBRL support to meet financial reporting mandates.
The shot above shows a simple graphical mapping updating an HL7 v2.6 message to v3.x. Altova MapForce is an any-to-any visual data mapping tool that supports mapping HL7 data, in its legacy EDI or newer XML-based format, to and from XML, databases, flat files, other EDI formats, and Web services. Mappings are implemented by simply importing the necessary data structures (MapForce ships with configuration files for the latest EDI standards and offers the full set of past and present HL7 standards as a free download) and dragging lines to connect nodes. A built-in function library lets you add advanced data filters and functions to further manipulate the output data. MapForce can also facilitate the automation of your HL7 transaction workflow through code generation in Java, C#, or C++ and an accessible command line interface. Additional support for mapping HL7 data to and from Web services gives healthcare organizations the ability to meet new technology challenges and changing enterprise infrastructures as they unfold within internal and external provider domains. Read more on our new HL7 tools page in the Altova Solutions Center. *The Altova MissionKit has been infused with XBRL support to meet financial reporting mandates.
What's New in XMLSpy 2009?
In addition to being tremendously useful, some of the new features in XMLSpy 2009 are just plain cool. The complete list of new functionality includes:
We’ve already blogged quite a bit about the first two items on the list: support for XBRL validation and XBRL taxonomy editing. Some more details on the other new features are below.
Intelligent XPath Auto-Completion
We’ve been delighted to receive feedback from customers who are really excited about this new feature. If you’re developing XSLT or XQuery, writing XPath expressions just got a lot easier. As you’re composing an XPath expression in Text View, Grid View, or the XPath Analyzer, XMLSpy now provides you with valid XPath functions, as well as element and attribute names from the associated schema and XML instance(s). XMLSpy’s intelligent XPath auto-completion accounts for namespaces when listing options and even provides deep path suggestions when the required node is not in close proximity to the current context.
Native Support for Additional Databases
XMLSpy 2009 adds new native support for the latest versions of SQL Server and Oracle, and brand new support for PostgreSQL. Support for DBs in XMLSpy allows you to generate an XML Schema based on a database, import and export data based on database structures, and generate relational database structures from XML Schemas, and so on. The built-in Database Query window lets you perform queries against the database and edit the data. Here’s the complete list of databases with native support in XMLSpy:
SQL Server support has also been enhanced to allow viewing and editing of XML fields that are stored in the database.
Extensions for Identity Constraint Editing in Schema View
Configuring identity constraints (i.e., key/keyref/unique values) is an important aspect of XML Schema development, especially for database users. Adding to existing support for editing these identity constraints, there are now enhanced visual cues and editing options in XMLSpy 2009. A new tab Identity Constraints tab in the Components entry helper window displays all existing constraints in a tree view and allows you to easily modify or create new relationships. Furthermore, identity constraints are now indicated by green lines, informative icons, and mouse-over messages in the Content Model View. A right-click menu allows you to easily add new relationships and specify field and selector values by typing them manually, using drop-down entry helpers, or by simply dragging and dropping the desired nodes.
Expanded Source Control System Support
Based on customer feedback, we’ve completely reworked the source control system interface in XMLSpy and also added the same level of source control support to UModel, our UML modeling tool, allowing both products to intelligently integrate with all major SCM tools. Once a project is bound to a version control system, XMLSpy automatically monitors the status of all files and prompts the you to check out a file whenever you starts to modify the document. In addition, the actual state of each file is shown through checkmarks or locks in the upper right corner of each file icon. What do you think of these new features? What would you like to see added to the next version of XMLSpy? Let us know by commenting below.
New features in UModel 2009 UML modeling tool
The recently launched UModel 2009 includes new features that will help development teams of all sizes take maximum advantage of UML software modeling.
Support for version control systems
You can use version control to manage UModel project files and generated source code files. Over two dozen popular source code systems are supported. Check out the list here.
Extensive API to manipulate UModel or create UModel plug-ins
You could create an elaborate trace tool for testing and debugging that illustrates your application flow by manipulating elements in UModel diagrams, or you can create a simple plug-in that adds a custom command or menu option using your own icons and buttons. The UModel installation even includes plug-in code examples to help you get started. The sample plug-ins create new menu and toolbar options to provide shortcuts to particular style settings, to automate a series of tasks, and to reinforce a naming convention, all common modeling steps that are likely to be unique for each development team.
 The sample code even shows you where to add the name and description description that appear in the UModel Customization dialog when a user installs your plug-in.
The sample code even shows you where to add the name and description description that appear in the UModel Customization dialog when a user installs your plug-in.  The screen shot below shows UModel with several custom plug-ins installed. PlugInMenu3 adds the prefix m_ to the name whenever a new property is created in a class.
The screen shot below shows UModel with several custom plug-ins installed. PlugInMenu3 adds the prefix m_ to the name whenever a new property is created in a class.  Note the plug-in custom toolbars directly above the Diagram Tree. The custom toolbar at the far left lets the user choose red or green to fill all currently-selected diagram elements. The Set Prefix toolbar lets the user turn the prefix feature on or off. If you want to try out the sample plug-ins yourself you can compile the sample code and add the resulting .dll files in the UModel Customize dialog. If you want to deploy the plug-ins across multiple workstations by sharing the .dll files, you will also have to register them manually at each workstation.
Note the plug-in custom toolbars directly above the Diagram Tree. The custom toolbar at the far left lets the user choose red or green to fill all currently-selected diagram elements. The Set Prefix toolbar lets the user turn the prefix feature on or off. If you want to try out the sample plug-ins yourself you can compile the sample code and add the resulting .dll files in the UModel Customize dialog. If you want to deploy the plug-ins across multiple workstations by sharing the .dll files, you will also have to register them manually at each workstation.
Support for profile diagrams in the latest UML 2.2 specification
An enterprise software architect might use custom stereotypes to define specific properties suitable to your team’s problem domain. The architect could then distribute these to the team via a shared package. The UModel Properties helper window lets you define custom stereotypes with a high level of precision. We are interested to hear about the applications users devise for the UModel API, plug-ins, and custom stereotypes over the coming weeks. You can add a comment to this blog entry, exchange tips with other users in the Altova Support Forum, or contact us through the link on the right side of the Altova Case Studies page to collaborate on a case study. If your development team hasn’t enjoyed the benefits of model-based software development, you can download a fully-functional free trial to test drive UModel 2009 for 30 days.
We are interested to hear about the applications users devise for the UModel API, plug-ins, and custom stereotypes over the coming weeks. You can add a comment to this blog entry, exchange tips with other users in the Altova Support Forum, or contact us through the link on the right side of the Altova Case Studies page to collaborate on a case study. If your development team hasn’t enjoyed the benefits of model-based software development, you can download a fully-functional free trial to test drive UModel 2009 for 30 days.
New tables and XPath filtering for flexible stylesheet design
To an Altova MissionKit user, it probably comes as no surprise that the majority of the new features in our latest (v2009) release were based on customer requests – yeah, that’s how we roll. But we also had the opportunity to build a lot of new functionality into the MissionKit tools, specifically XMLSpy, MapForce, and StyleVision, because of our added support for XBRL. As you may already know, XBRL is built on top of XML, and adds semantic definitions to financial reporting data. XBRL Dimensions 2.1 also has some interesting rendering and presentation requirements that, in our humble opinion, have given StyleVision some of its coolest new features to date: an all-new table design and XPath filtering. The new table design in StyleVision makes the visual stylesheet design interface only that much more intuitive. Now, you can design your table rows and columns and then simply drag borders to resize. You can also right-click to rearrange the table structure with copy and paste – or just delete the entire row/column right there. The new table design also lets you have static and dynamic properties within the same table design.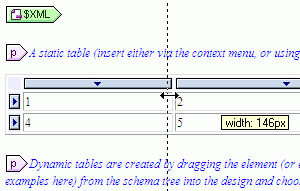 XPath filtering is also an enormously important new feature in StyleVision – especially for those of us who like to create reusable design templates. This feature lets you filter data out of your rendering based on an XPath expression. Simply right-click the node that you want to filter, and StyleVision’s XPath Builder will open and provide intelligent auto-completion to help you formulate a valid XPath statement. It even interprets your location in the stylesheet design so that your expression is not only valid according to the XPath standard, but it also makes sense in the context of your template design.
XPath filtering is also an enormously important new feature in StyleVision – especially for those of us who like to create reusable design templates. This feature lets you filter data out of your rendering based on an XPath expression. Simply right-click the node that you want to filter, and StyleVision’s XPath Builder will open and provide intelligent auto-completion to help you formulate a valid XPath statement. It even interprets your location in the stylesheet design so that your expression is not only valid according to the XPath standard, but it also makes sense in the context of your template design. 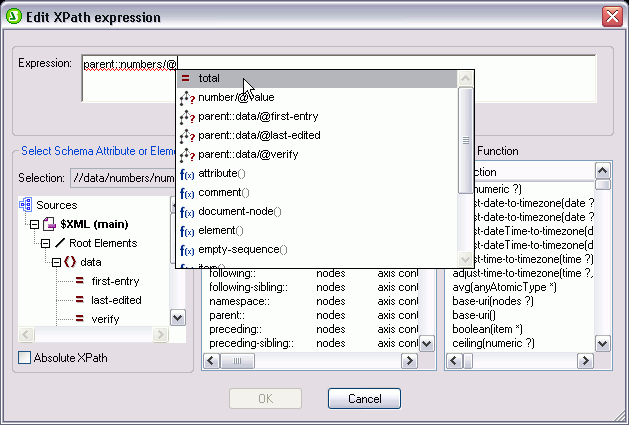 Of course, if you need to make all of your filtered data available again, all you need to do is delete the XPath filter icon in your design. StyleVision 2009 delivers all this and single source output in HTML, RTF, PDF, and Word 2007 from XML, databases, and now XBRL – and you can even design your own e-Forms for editing in Altova Authentic. Check out a free trial, and please let us know what you think!
Of course, if you need to make all of your filtered data available again, all you need to do is delete the XPath filter icon in your design. StyleVision 2009 delivers all this and single source output in HTML, RTF, PDF, and Word 2007 from XML, databases, and now XBRL – and you can even design your own e-Forms for editing in Altova Authentic. Check out a free trial, and please let us know what you think!
More Altova MissionKit 2009 News
Since we announced Version 2009 of the Altova MissionKit last week, Altova’s CEO Alexander Falk has been detailing some of the hottest new functionality (among other interesting topics) over on the XML Aficionado Blog. In case you missed it, check out these highlights:
XBRL Support Added to Altova MissionKit 2009
What is XBRL?
The eXtensible Business Reporting Language (XBRL) is an XML-based vocabulary for electronic transmission of business and financial data. Currently in version 2.1, XBRL is an open standard that is maintained by XBRL International, a global non-profit consortium of over 550 major companies, organizations, and government agencies. XBRL was developed to facilitate business intelligence (BI) automation by enabling machine-to-machine communication and data processing for financial information with an eye towards cost reduction through the elimination of time consuming and error-prone human interaction. Official support from European Parliament and a mandate the United States Securities and Exchange Commission (SEC) has all but secured XBRL’s future as the official standard for financial reporting. You can learn a lot more about the nuts and bolts of XBRL in the XBRL white paper written by Altova’s Technical Marketing Manager, Liz Andrews.
XBRL Tools
All of the power and functionality that XBRL brings to financial data is useless without XBRL-conformant tools to interpret and process this data. In fact, understanding the importance of tools for XBRL, the XBRL recommendation writes software vendors into its abstract:
As such, XBRL development and data integration can be supported in a variety of different ways. The Altova MissionKit 2009 provides comprehensive support for working with XBRL, from validation and editing, to transformation and rendering, in multiple tools: XMLSpy 2009 – XBRL validator and XBRL taxonomy editor. When you need to ensure that your XBRL filing documents are valid and compliant, XMLSpy can be used to to validate an XBRL instance file against its corresponding taxonomy. If you need to extend a standard taxonomy to meet your organization’s filing needs, the graphical XBRL taxonomy editor in XMLSpy gives you a graphical model with tabs that organize different types of taxonomy elements, wizards, and entry helpers, all of which guide data input based on the structural information provided in the XBRL instance and base taxonomies. MapForce 2009 – XBRL exchange and data integration tool. When you need to extract financial data from back end systems and transform it into compliant XBRL filings, MapForce makes it easy with drag-and-drop, graphical data mapping and instant conversion. MapForce allows bi-directional data mapping between XBRL and databases, flat files, Excel 2007, XML, and Web services. Once your mapping project is defined, you can utilize it to automate quarterly and annual XBRL filing generation by transforming data with the MapForce UI, command line, or auto-generated, royalty free application code. This makes public financial data submission a repeatable and highly manageable process, allowing organizations to produce valid XBRL reports as required based on the variable data stored in accounting system fields – without having to define new mappings every quarter.
MapForce 2009 – XBRL exchange and data integration tool. When you need to extract financial data from back end systems and transform it into compliant XBRL filings, MapForce makes it easy with drag-and-drop, graphical data mapping and instant conversion. MapForce allows bi-directional data mapping between XBRL and databases, flat files, Excel 2007, XML, and Web services. Once your mapping project is defined, you can utilize it to automate quarterly and annual XBRL filing generation by transforming data with the MapForce UI, command line, or auto-generated, royalty free application code. This makes public financial data submission a repeatable and highly manageable process, allowing organizations to produce valid XBRL reports as required based on the variable data stored in accounting system fields – without having to define new mappings every quarter. 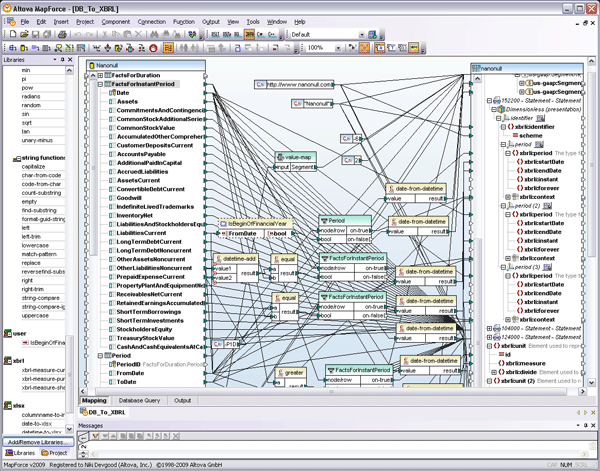 If you need to aggregate XBRL filings from different time periods or different organizations in your back end systems for analysis, MapForce lets you map the XBRL data to databases, flat files, XML – even Web services. Mapping data directly from its source format removes the need for re-keying and potential errors. Together, MapForce and XBRL enable the automation of the multi-dimensional financial analysis that organizations and stakeholders use to evaluate market, company, and industry performance on a regular basis. StyleVision 2009 – XBRL rendering tool. Once data is in XBRL format, and it’s time to render it for consumption on the Web or in printed materials, StyleVision lets you create a straightforward XBRL report to output the data in multiple formats. Simply drag and drop a taxonomy financial statement onto the design pane as an XBRL table, and then use StyleVision’s graphical interface to format stylesheets for simultaneous output in HTML, RTF, PDF, and Word 2007 (OOXML). The XBRL Table Wizard makes it easy to customize the table structure and specify the concepts to include in the report. In the case of the US-GAAP taxonomy, which provides, in addition to the hierarchical organization in its presentation linkbase, some best practices information on how to structure XBRL instances, you can simply select US-GAAP mode to have StyleVision automatically output the data according to this information.
If you need to aggregate XBRL filings from different time periods or different organizations in your back end systems for analysis, MapForce lets you map the XBRL data to databases, flat files, XML – even Web services. Mapping data directly from its source format removes the need for re-keying and potential errors. Together, MapForce and XBRL enable the automation of the multi-dimensional financial analysis that organizations and stakeholders use to evaluate market, company, and industry performance on a regular basis. StyleVision 2009 – XBRL rendering tool. Once data is in XBRL format, and it’s time to render it for consumption on the Web or in printed materials, StyleVision lets you create a straightforward XBRL report to output the data in multiple formats. Simply drag and drop a taxonomy financial statement onto the design pane as an XBRL table, and then use StyleVision’s graphical interface to format stylesheets for simultaneous output in HTML, RTF, PDF, and Word 2007 (OOXML). The XBRL Table Wizard makes it easy to customize the table structure and specify the concepts to include in the report. In the case of the US-GAAP taxonomy, which provides, in addition to the hierarchical organization in its presentation linkbase, some best practices information on how to structure XBRL instances, you can simply select US-GAAP mode to have StyleVision automatically output the data according to this information. 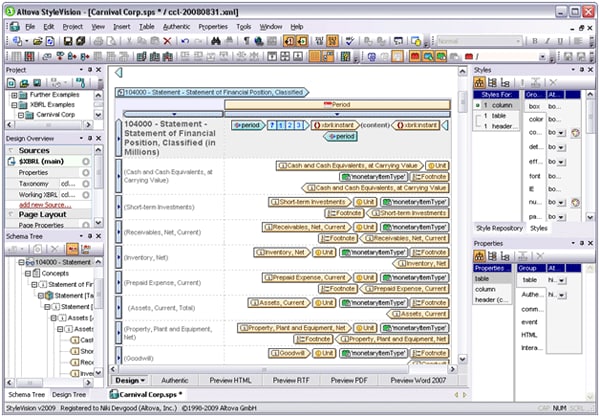 To try this powerful XBRL functionality for yourself, download a free, fully functional 30-day trial of the Altova MissionKit 2009, and please let us know what you think by commenting on this blog or in the Altova Discussion Forum.
To try this powerful XBRL functionality for yourself, download a free, fully functional 30-day trial of the Altova MissionKit 2009, and please let us know what you think by commenting on this blog or in the Altova Discussion Forum.
Now available: Altova MissionKit Version 2009
We are very excited to announce general availability of the Altova MissionKit 2009 suite of XML, database, and UML tools. Version 2009 delivers numerous new features across the tools included in the MissionKit, including comprehensive support for working with XBRL, native support for new databases and database differencing, UML sequence diagram generation, and much more. A few details are below, with complete information and screenshots available on the Altova What’s New page. Coinciding with this major release, we have decided to pass savings realized due to the currently favorable US$/EUR exchange rate directly to our customers by reducing US$ prices across the entire Version 2009 product line.
Support for XBRL
The Altova MissionKit 2009 provides powerful new support for viewing, editing, validating, mapping, and publishing XBRL data. With intelligent wizards, graphical drag-and-drop design models, and various code generation capabilities, the MissionKit Version 2009 gives developers, technical professionals, and power users one easy-to-use suite of tools for working with XBRL and transforming data into content that can be shared with business partners, stakeholders, and regulatory commissions. Altova MissionKit tools with XBRL support are:
Extended Database Functionality
Native support for additional databases has been added to all database-enabled Altova MissionKit tools, including XMLSpy 2009, MapForce 2009, DatabaseSpy 2009, StyleVision 2009, and DiffDog 2009. Current support for SQL Server® and Oracle® databases is now extended to include the most recent versions – SQL Server 2008 and Oracle 11g. New support for the PostgreSQL 8 database is also now available. In addition, both DatabaseSpy 2009 and DiffDog 2009 now allow you to compare and merge database content. Individual database tables or multiple tables within a schema can be compared, whether they are the same database type or completely different databases. Results of the content comparisons are displayed in tables, and differences can be merged bi-directionally. This new database comparison functionality allows users to easily backup, copy, or merge data quickly and easily.
Sequence Diagram Generation
MissionKit users working with UML will be especially interested in this new functionality in UModel 2009. Sequence diagram generation greatly assists developers who need to reverse engineer existing applications written in Java, C#, or Visual Basic. After importing an existing project, directory, or file into a UModel 2009 project, you can now select any operation in any class, and automatically generate a sequence diagram that illustrates the lifecycle of the operation, as well as objects that interact with it. Like all other project diagrams in UModel, sequence diagrams are stored as part of the UModel project file and can be included in generated UModel project documentation. Check out the full list of features added in Version 2009, and be sure to check back here frequently, as we’ll be blogging about more new features each week. As always, you can download a free trial of the Altova MissionKit to test out this new functionality for yourself.
Altova customer Recordare builds MusicXML-based solution
Recordare® is a technology company focused on providing software and services to the musical community. Their flagship products, the Dolet® plugin family, are platform-independent plugins for popular music notation programs, facilitating the seamless exchange and interaction of sheet music data files by leveraging MusicXML. Dolet acts as a high quality translator between the MusicXML data format and other applications, enabling users to work with these files on any conceivable system, including industry leading notation and musical composition applications Finale® and Sibelius®. The list of MusicXML adopters also includes optical scanning utilities like SharpEye or capella-scan, music sequencers like Cubase, and beyond. Dolet increases the MusicXML support in all of these programs and promotes interoperability and the sharing of musical scores. In creating the Dolet plugins, Recordare used Altova’s XML editor, XMLSpy, for editing and testing the necessary MusicXML XML Schemas and DTDs, and the diff/merge tool, DiffDog, for regression testing.
The Challenge
Music interchange between applications had traditionally been executed using the MIDI (Musical Instrument Digital Interface) file format, a message transfer protocol that has its roots in electronic music. MIDI is not an ideal transfer format for printed music, because it does not take into account the multitude of notations (e.g., rests, repeats, dynamics, lyrics, slurs, tempo marks, etc.) that convey much of the meaning. MusicXML is an open, XML-based file format specifically created to encapsulate musical notation or digital sheet music data that was built on top of previous formats, MuseData and Humdrum. XML lends MusicXML the power and flexibility to be easily accessed, parsed, rendered, and otherwise manipulated by a wide variety of automated tools, and its general acceptance as a standard makes it an ideal format for scoring using computer technology. Since its original release by Recordare in January of 2004 (version 2.0 was released in June 2007), MusicXML has gained acceptance in the music notation industry with support in over 100 leading products, and is recognized as the de facto XML standard for music notation interchange. These products would not have adopted MusicXML unless it could be used to exchange data with industry-leading applications like Finale and Sibelius. By developing advanced plugins for popular music notation suites, Recordare would be able to deliver to their customers all of the advantages that XML can bring for data exchange and standardization.
The Solution
Below is an example showing the score of the first few measures of Beethoven’s An die ferne Geliebte, Op. 98 as it is written in sheet music: and a small snippet of the same piece translated to MusicXML:
and a small snippet of the same piece translated to MusicXML:  The MusicXML-based Dolet 4 plugins for Finale and Sibelius provide a more accurate and usable representation of sheet music than Standard MIDI translation. For example, the images below show the same piece of music. On the left is a Finale 2009 rendering of a MIDI file exported from Sibelius, and on the right is the same application’s interpretation of a MusicXML 2.0 file exported from the same version of Sibelius.
The MusicXML-based Dolet 4 plugins for Finale and Sibelius provide a more accurate and usable representation of sheet music than Standard MIDI translation. For example, the images below show the same piece of music. On the left is a Finale 2009 rendering of a MIDI file exported from Sibelius, and on the right is the same application’s interpretation of a MusicXML 2.0 file exported from the same version of Sibelius. 
 In the MIDI rendition, vital information like chord symbols, lyrics, slurs, articulations, and even title and composer are omitted from the translation. In addition to providing native support for MusicXML, the recently released Dolet 4 for Finale and Dolet 4 for Sibelius plugins enhance the capabilities of these programs by adding advanced features like:
In the MIDI rendition, vital information like chord symbols, lyrics, slurs, articulations, and even title and composer are omitted from the translation. In addition to providing native support for MusicXML, the recently released Dolet 4 for Finale and Dolet 4 for Sibelius plugins enhance the capabilities of these programs by adding advanced features like:
In developing the plugins, Recordare was subject to specific requirements dictated by the Sibelius and Finale applications. The Sibelius plugin was programmed in ManuScript, and is one of the largest plugins ever written in that language. Finale, on the other hand, requires plugins to have a C++ core, and Recordare implemented this, adding MusicXML logic in Java and a JNI layer to provide the two-way Java/C++ communication. Recordare’s Dolet plugins are now critical aspects of the music preparation process for many television and film scores as well as new music publications. Errors in translation need to be fixed in maintenance updates, while ensuring that no new errors are introduced into these complex translation plugins. Regression testing of the MusicXML file produced by the Dolet plugins is thus an essential part of Recordare’s quality assurance process. Recordare used Altova’s DiffDog in the development of the Dolet plugins. XMLSpy was used to test and edit their DTDs and XML Schemas, and DiffDog for regression testing the MusicXML files produced by the software. Recordare has several regression test suites covering a wide range of musical repertoire, from baroque to hip-hop. DiffDog allows easy differencing of multiple runs of these test suites, including the ability to ignore differences in XML metadata elements such as software version and XML creation date that always change across test cases. Recordare has used Altova’s XMLSpy XML editor to edit the MusicXML DTDs and XML Schemas, starting with the use of XMLSpy 3.5 (released in 2001) to create the earliest alpha and beta versions of the MusicXML DTD. Version 2.0 of MusicXML added a compressed zip version of the format, similar to what is used in other XML applications like Open Office and Open XML. XMLSpy 2008 Enterprise Edition’s comprehensive support for zipped XML files made it easy to test this new feature together with the Dolet for Finale plugin.
Recordare has used Altova’s XMLSpy XML editor to edit the MusicXML DTDs and XML Schemas, starting with the use of XMLSpy 3.5 (released in 2001) to create the earliest alpha and beta versions of the MusicXML DTD. Version 2.0 of MusicXML added a compressed zip version of the format, similar to what is used in other XML applications like Open Office and Open XML. XMLSpy 2008 Enterprise Edition’s comprehensive support for zipped XML files made it easy to test this new feature together with the Dolet for Finale plugin. 
A small portion of the extensive MusicXML schema shown in XMLSpy’s graphical XML schema editor
XMLSpy’s support for XQuery has also contributed to Recordare’s regression testing efforts. In response to a customer request, Recordare now exports XML processing instructions from the Dolet for Sibelius plugin when it encounters a musical feature that it is unable to translate correctly. A simple XQuery execution to search for all the processing instructions in the XML files in a given folder lets Recordare check for the presence of these restrictions within each test suite, and then compare the resulting XML files using DiffDog between runs of the test suite. Recently, customer demand led Recordare to develop an XSD version of the MusicXML format. XMLSpy Enterprise Edition was used to develop and test the schemas. Schema validation, schema restriction and extension, and automatically-generated schema documentation were all able to be tested using XMLSpy’s features.
The Results
The Dolet plugins are extensions for common industry software that harness the built-in capabilities of the MusicXML format to make musical scores truly interchangeable across disparate systems and toolsets. These plugins have the capacity to render accurate and meaningful musical notation based on the powerful MusicXML specification. The leading XML Schema editing capabilities in XMLSpy and the strong XML and directory differencing support in DiffDog enabled Recordare to write and polish the MusicXML schemas and perform regression testing on the Dolet plugins. The resulting high quality of the schemas and software has made MusicXML and the Dolet plugins a key element of the toolkit for composers, arrangers, publishers, copyists, and engravers throughout the industry wherever printed music is used. Try XMLSpy, DiffDog, and the other Altova MissionKit tools for yourself with a free 30-day trial.
New MapForce Online Training – Code Generation
I’m pleased to announce that the next module in the Altova Online Training Series on the MapForce data mapping tool is now available. MapForce Code Generation is an advanced-level course that provides step-by-step tutorials for generating program code (including C# , C++, Java, XSLT, and XQuery) based on graphically defined data mappings and integrating that code into your own applications (royalty-free). Detailed tutorials also walk you through how to add custom XSLT and XQuery functions, add function libraries, and process mappings with multiple files.The MapForce Code Generation module is available on-demand, so you can learn when your schedule allows, and, like all Altova Online Training courses, there is no fee or registration required. Please let us know what you think of MapForce Code Generation – comments and suggestions are appreciated.
Free Online Training Module: Intro to StyleVision
We’ve just released a new Altova Online Training Module: Introduction to StyleVision. This free training module provides an introduction to the StyleVision stylesheet design tool interface and functionality as well as interactive tutorials for transforming XML and database content into eye-catching HTML pages, RTF documents, PDF reports, Word 2007 (OOXML) documents, and intuitive Authentic® forms. Detailed tutorials will help users create an effective StyleVision design and insert dynamic and static content. This module also explores how to format the components of the StyleVision design and create global templates. Check out the full list of free Altova Online Training modules, all of which are available in a convenient, on-demand format. As always, please share your feedback and suggestions about Altova Online Training with us, either by using the survey included in the training module or by leaving a comment on this blog.
Check out the full list of free Altova Online Training modules, all of which are available in a convenient, on-demand format. As always, please share your feedback and suggestions about Altova Online Training with us, either by using the survey included in the training module or by leaving a comment on this blog.
Altova MissionKit and DatabaseSpy Named Jolt Award Finalists
New Altova Solutions Center
Take a look at our new Solutions Center design! Not only does it look great (thanks to the Altova Art and Web Development teams), but it also gives a clear breakdown of Altova MissionKit tools and how they can help you be prepared and well-armed to approach common business and technology challenges.As always, we’d love to hear from you about how you use the Altova MissionKit in your organization – we are always looking for great case studies!
Not only does it look great (thanks to the Altova Art and Web Development teams), but it also gives a clear breakdown of Altova MissionKit tools and how they can help you be prepared and well-armed to approach common business and technology challenges.As always, we’d love to hear from you about how you use the Altova MissionKit in your organization – we are always looking for great case studies!
New Demo Video: Intro to DatabaseSpy
We’re expanding our Flash video series to cover DatabaseSpy, Altova’s multi-purpose database utility. Available to view now, the first DatabaseSpy video is a two-minute introduction that quickly highlights many DatabaseSpy features and shows off its elegant and fun-to-use interface. If you have ever wondered how a multi-database query and design tool can help with a range of database analysis, design, and editing tasks, check out this quick tour. You’ll get to see the DatabaseSpy Quick Connection Wizard, Database Browser, SQL Editor, data editing functionality, and the Graphical Design Editor that lets you visualize, create, or modify database tables and relationships without writing SQL commands. Find out for yourself why DatabaseSpy has received such high acclaim – and look for more Flash videos coming soon in the DatabaseSpy series!
If you have ever wondered how a multi-database query and design tool can help with a range of database analysis, design, and editing tasks, check out this quick tour. You’ll get to see the DatabaseSpy Quick Connection Wizard, Database Browser, SQL Editor, data editing functionality, and the Graphical Design Editor that lets you visualize, create, or modify database tables and relationships without writing SQL commands. Find out for yourself why DatabaseSpy has received such high acclaim – and look for more Flash videos coming soon in the DatabaseSpy series!
Voting is Open in the Developer.com POY Awards
The US presidential election might be over, but your votes are still needed! Altova DatabaseSpy and Altova XMLSpy are finalists in the 2009 Developer.com Product of the Year Awards. We’d like to ask for your vote to help show your support for Altova tools. Please cast your vote for Altova DatabaseSpy in the “Database Tool or Add-in” category and Altova XMLSpy in the “.NET Tool or Add-in” category.The polls close soon, so please vote today. As always, we thank you for your support!
Please cast your vote for Altova DatabaseSpy in the “Database Tool or Add-in” category and Altova XMLSpy in the “.NET Tool or Add-in” category.The polls close soon, so please vote today. As always, we thank you for your support!
Next Altova Online Training Module is Available
We recently blogged about the return of free Altova Online Training, with its new, more convenient, on-demand format. The first module available was Introduction to MapForce, and we’re pleased to announce that the next module in the series is now available. MapForce Data Sources and Targets is aimed at the intermediate MapForce user and provides students with step-by-step tutorials for mapping XML, databases, CSV, EDI, text, and Excel 2007 files in the data mapping tool. Detailed tutorials also walk you through how to process and map legacy text files using MapForce FlexText. This module also covers the methods of mapping and allows you to practice each method, including source-driven, target-driven, and copy-all mapping.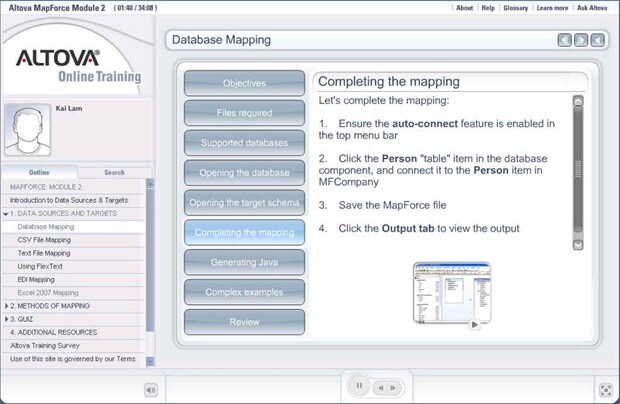 MapForce Data Sources and Targets is in BETA status, and we hope you’ll give us your feedback and suggestions so that we can continue to improve. Please respond either using the survey included in the class or by leaving a comment on this blog.
MapForce Data Sources and Targets is in BETA status, and we hope you’ll give us your feedback and suggestions so that we can continue to improve. Please respond either using the survey included in the class or by leaving a comment on this blog.