Extract Data for PDF Mapping
MapForce, Altova’s award-winning data mapping tool, includes support for PDF input in data integration and ETL workflows. The MapForce PDF Extractor makes it easy to define rules for extracting PDF data in a structured format to make it available for mapping to other popular formats like Excel, XML, JSON, databases, and more.
Let’s take a look at how it works.

How to Extract Data from PDF
The PDF file format enjoys near ubiquity in communications across verticals today thanks to its ability to offer a consistent presentation on any platform or device. PDFs typically combine multiple ways of presenting data in elements that work well for human readers, including text, images, charts, and tables, all with a variety of formatting options.
However, though they are great for presenting data in a user-friendly way, PDFs lack any built-in structure required for extracting that data effectively for integration with other business systems, which, of course, is a common requirement. Traditional data extraction tools often fail to accurately capture information from PDFs, particularly when dealing with complex layouts and varying formatting styles. This can result in errors, inefficiencies, and the need for manual intervention to correct the extracted data.
To address these PDF data integration challenges, Altova created the MapForce PDF Extractor, a visual tool that makes it easy to define rules for extracting structured data from PDFs.
Learn how MapForce PDF Extractor works in this how-to video:
The best way to get started with the MapForce PDF Extractor is to load a sample document with the format of the data you need to extract. This might be an invoice, data entry form, report, customer record, etc. The PDF Extractor displays this sample document so you can begin to define a template and rules for extracting the data in a structured way. The straightforward design of the MapForce PDF Extractor makes it easy to specify the PDF document structure in a visual way, using point-and-click and drag-and-drop functionality.
Next to the PDF view pane, a schema pane displays a tree structure that represents how the PDF will be parsed and the data will be extracted.
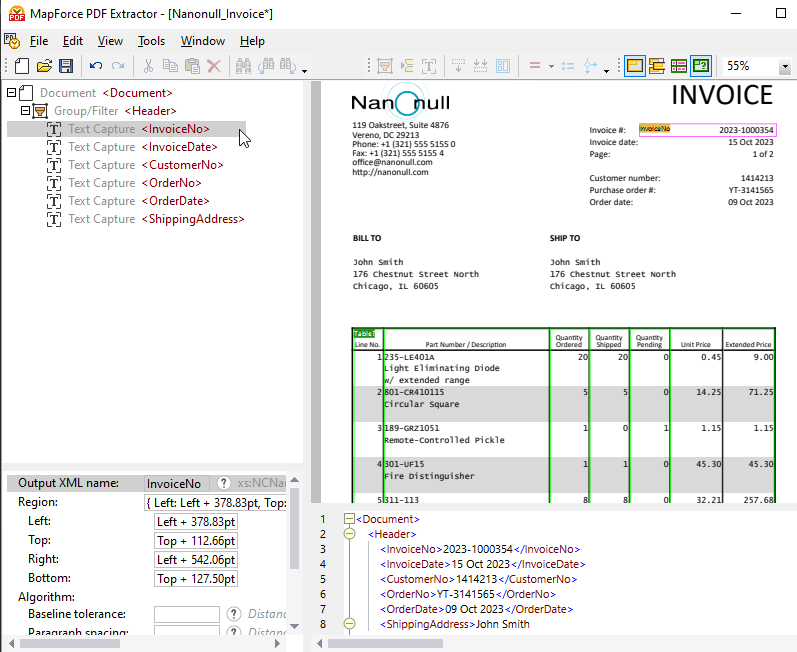
The properties pane lets you define properties and calculate expressions, as needed. At the bottom of the PDF document view is the output pane (shown above), which lets you see a preview of the result of the PDF data extraction based on the properties and extraction rules you define. The output is represented by an XML document showing XML tags for the structure as well as the actual content of the sample file that is being extracted.
To capture portions of the document to add to the schema tree, simply highlight an area and right click to create a text capture.
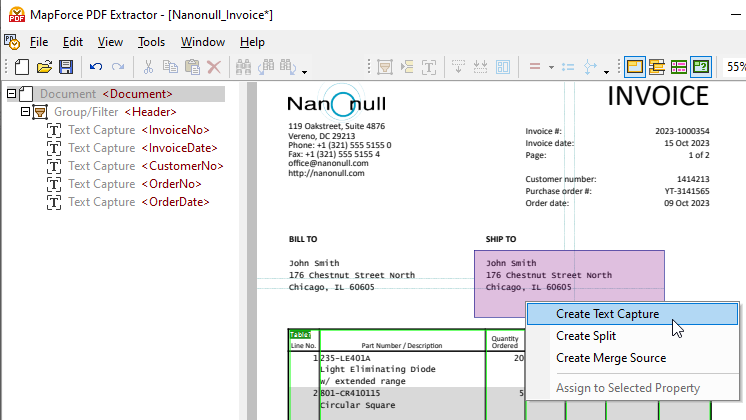
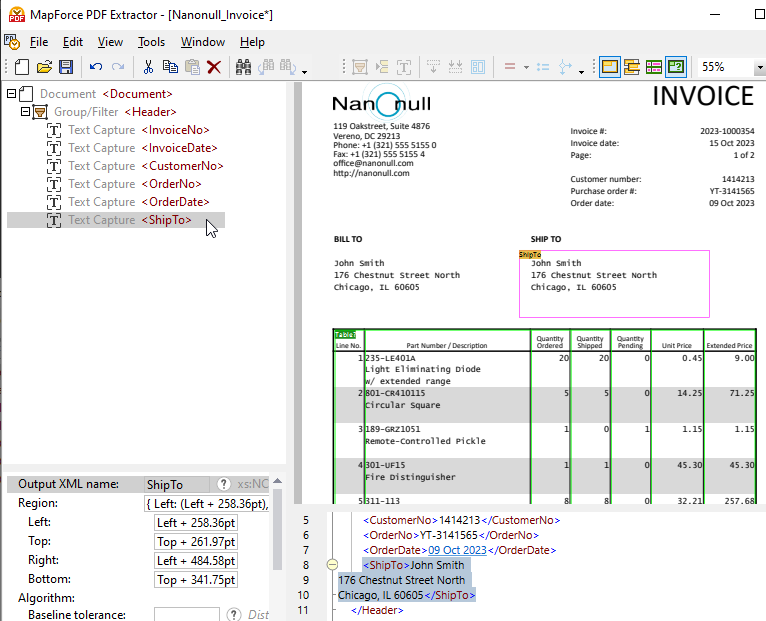
Drag the newly created element to the desired place in the tree and give it a descriptive name.
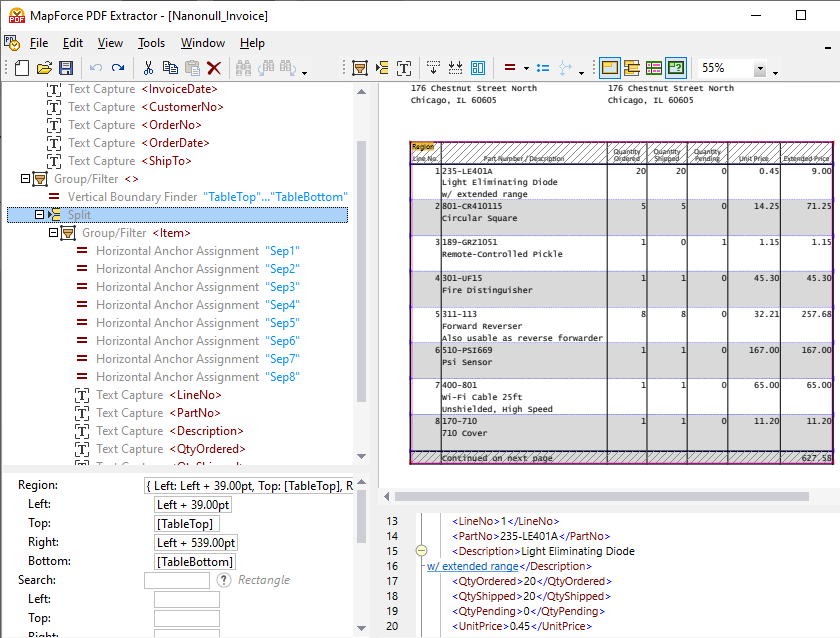
In addition to support for defining data extraction rules manually, the MapForce PDF Extractor includes a powerful suggestion engine that automatically identifies common document elements and attempts to detect their structure. For instance, the suggestion engine will identify tables that exist in the document, which you can opt to extract automatically and then refine as necessary. The split operator in the schema pane helps you define how to correctly divide the table into separate rows. The suggestion engine can look for edges or lines to create the split, split based on a fixed distance, or detect changes in the background color, which you can preview in the PDF view pane. At the same time, the suggestion engine captures columns and header text, which you can fine tune as necessary, as can be seen in the video above.
Clicking on any object in the schema tree highlights the corresponding structure and data capture rules as they apply in the PDF document view.
Map PDF to Other Formats
Once your template in the MapForce PDF Extractor is complete, you can add it to a MapForce data mapping project to efficiently map the PDF data to other supported formats. Simply drag and drop to associate source and target nodes and take advantage of the built-in library of data processing functions to transform the PDF data. Common applications include:
- PDF to Excel
- PDF to XML
- PDF to JSON
- PDF to SQL or NoSQL database systems
- PDF to EDI messages
- PDF to CSV or text
In addition to these scenarios, MapForce supports chained data mapping processes as well as multiple source/target data structures.
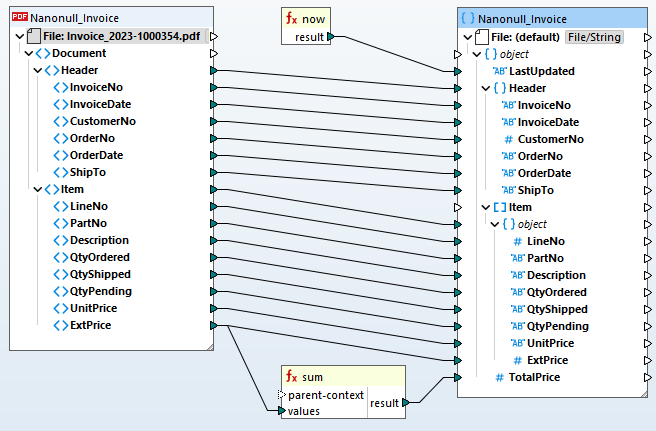
Based on your data mapping definition, MapForce transforms the data instantly. Or, you can take advantage of MapForce Server Advanced Edition for recurrent PDF transformations and ETL pipelines. This allows organizations to automate data integration and streamline processes by seamlessly incorporating PDF data into their existing systems, databases, and workflows.
Get started with the MapForce PDF Extractor by downloading a free trial from the Altova web site.