Data Integration
Altova MapForce excels at connecting and transforming data across a wide range of databases, making it a powerful tool for data integration projects of all sizes. It supports popular relational databases such as SQL Server, Oracle, MySQL, PostgreSQL, IBM DB2, and more. With MapForce’s graphical interface, you can simply drag-and-drop mappings between tables and columns, visually designing how data should flow and transform between sources and targets. It even provides user-friendly features for merging multiple data inputs into a single output, helping you streamline the development process.
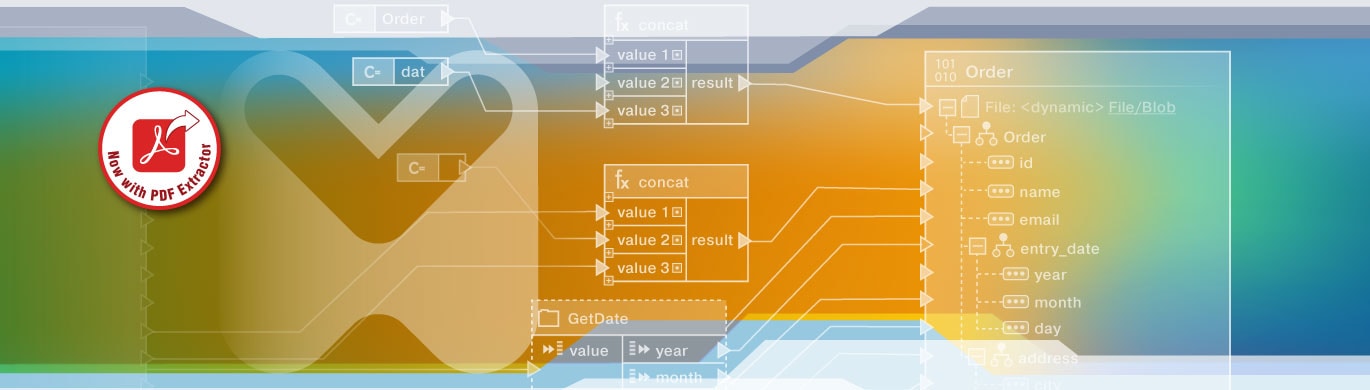
Beyond basic mapping, MapForce offers robust functions and filters that can be inserted to handle data transformations on the fly—things like joining data from various tables, filtering records based on dynamic criteria, or converting data types automatically.
Here is a selection of blog posts about data integration:
- Using OCR to Unlock Data for PDF Data Integration
- AI-based Database Image Classification with Altova MapForce
- Data Mapping NoSQL Databases
- Data Mapping Binary Objects
- Data Mapping Binary Objects – Part 2
- Data Mapping JSON Lines
- Transitioning Data Mapping Projects from Development through Testing and Production
- Database Mapping with Database Exception Handling
Posts categorized: data-integration
- Automate Data Integration and Transformation Workflows with FlowForce Server
- How to Create a Chained Data Transformation
- Automatically Convert EDI to XML
- Data Mapping Made Easy
- Using Decision Tables to Simplify Data Mapping Logic
- Unlocking Scanned PDFs with OCR Support in MapForce
- New in Altova Software 2026
- CbC Reporting Made Easy
- How to Create Batch Data Mapping Projects
- OpenAPI Tools for Developers
- Updating Shopify Inventory from a Mobile App
- Exporting Products from Shopify as CSV
- New Tools for Shopify, OpenAPI, & More
- ETL Tutorial: Video
- What is ETL?
- ETL Basics: CSV to Database in MapForce
- Text Search for Precise PDF Data Extraction
- Altova Version 2025 with YAML Grid and More
- Run Altova Server Software on Azure Cloud
- Mapping Structured Data with Enhanced Node Functions
- Extract Data for PDF Mapping
- AI Integration & PDF Data Mapping in Version 2024
- AI-based Database Image Classification with Altova MapForce
- AI-based Database Image Classification with Altova MapForce
- AI-based support request sentiment analysis using MapForce and GPT-4
- How to Convert Data in MapForce [Video]
- Drive VDA EDI Conversion and Transformation with MapForce
- Split Mode in Grid View and More in v2023r2
- Validating and Debugging Data Transformations
- Dark Mode and Much More in Version 2023
- How to Compare CSV Files or Compare a CSV File to a Database Table
- MapForce Data Mapping Tutorial (Video)
- Transforming and Converting Protobuf
- Transforming and Converting Protobuf
- Excel Data Mapping to Update Existing Documents
- Data Mapping NoSQL Databases
- API Data Mapping
- How to View Workflow Automation Reports on FlowForce Server
- Data Mapping with XSLT3 Math Functions
- Data Mapping Binary Objects – Part 2
- Data Mapping Binary Objects
- Web Service Data Integration
- New Data Integration Tools
- How to Convert Legacy Text Files [Video]
- Data Mapping JSON Lines
- Data Mapping JSON Lines
- Transitioning Data Mapping Projects from Development through Testing and Production
- Handle HTTP Errors During Automated Data Integration
- Handling HTTP Errors in Web Service Data Mappings
- Database Mapping with Database Exception Handling
- Database Mapping with Database Exception Handling
- Database Tracing to Log Changes Made by a Data Mapping Project
- Database Tracing to Log Changes Made by a Data Mapping Project
- Updated JSON Schema Support Highlights v2019 Release 3
- Job Distribution on FlowForce Server
- Node Functions Simplify Mapping Hierarchical Data Structures
- Data Mapping NCPDP SCRIPT
- MapForce Server Accelerator Edition Achieves a New Level of Data Transformation Performance
- Use Join to Integrate Data in Any Format
- A Typical MapForce Server Use Case
- JSON Data Mapping and Transformation with MapForce
- EDI Data Mapping with MapForce
- MapForce Supports SQL Merge When It’s the Right Tool for the Job
- MapForce Offers Dynamic Access to Node Names
- Faster EDI Data Translation
- XBRL Data Mapping: WIP Taxonomy
- Data Mapping REST Web Services
- Using Google Cloud SQL
- Applying Data Mapping Patterns
- Interactive Debugger for Data Integration Projects
- New JSON Schema Editor and Data Mapping Debugger Debut in Altova Version 2016
- Data Mapping Files with XML Mixed Content
- Manipulating Data in Cross-Platform Mobile Applications
- New Data Integration Whitepaper Now Available
- Data Integration for Mobile Devices – MobileTogether Works with FlowForce Server
- Automating Data Integration Workflows – Download the E-Book
- FlowForce Server Job Cache Enhancements
- Deploy Data Mappings and Report Designs for Automated Processing
- XML Wildcard Data Mapping and Transformation in MapForce
- Result Caching Accelerates Application Response Time
- FlowForce Server Jobs as HTTP Services
- Use XPath Expressions to Refine Data Selection
- Filesystem Commands and More Wizardry with FlowForce Server Built-in Functions
- Constant Quest for Efficiency
- Download Example Files for FlowForce Server, MapForce, and StyleVision
- Taming Bad Input Data with FlowForce Server
- Customizing a FlowForce Server Job
- Automate Data Mapping and Transformation with FlowForce Server
- New Server Products for Data Transformation
- Automate Data Transformation with FlowForce Server
- Process Multiple Input Files in a Single Data Mapping
- Stored Procedures in Database Mappings
- Web Service as a Look-Up Table to Refine GPS Data
- New Case Study: Automating XBRL Data Collection and Processing
- Resist Data Integration Redundancy
- Data Exchange for the Mobile Workforce
- Processing the Groupon API – Epilogue
- XML Development with Database Integration
- Leverage Your Financial Data with the XBRL Chart Wizard–Part 1
- Processing the Groupon API with MapForce – Part 2
- Processing the Groupon API with Altova MapForce
- Switch Statement vs. Look-up Table in MapForce
- Expandable If-Else Works like a Switch Statement in MapForce
- Altova MapForce Brings Powerful Data Transformation Capabilities to Quark Dynamic Publishing Solution
- HL7 and XML Healthcare Data Integration at HIMSS10
- MapForce v2010r2 New Features
- MapForce v2010 - “Most Wanted”
- HubKey Case Study
- New Data Mapping Demo Video Released
- SOA and Cloud Services Within Your Budget
- What's New in MapForce 2009?
- HL7 Data Integration
- MapForce data mapping tool now supports Excel 2007/OOXML mapping
- Case Study: MapForce EDI Conversion Optimizes Business Transactions
- LANSA OEMs MapForce to Convert Data in Business Process Integration App